This document describes the development of a web scraping tool to extract useful mobile app market data from Appannie's website. The tool automates browsing to Appannie pages using Selenium, scrapes app name, description and version history from individual app pages, and saves the data to CSV files. It iterates through Appannie's top charts from the past year for the US and Chinese markets to build a structured dataset for analysis and to help app developers. The project uses an agile development approach with weekly iterations to expand the tool's functionality and optimize performance over time.






![Chapter 1. Introduction
CHAPTER 1
INTRODUCTION
1.1 Motivation
There are sources of data where it is possible just to consult data through a website
and it is impossible to save a le with some important and selected informations. Web
scraping and data mining methods can be used to prepare a structured or semi-structured
le with ltered and useful data, trasforming a hardly understandble set of data contained
in a website into an organised and readable report of mobile app market stored in a le
[5] [2].
1.2 Purpose
The result of this project aims to help developers and software houses to make decisions
about the development, the presentation, and the advertising of a new mobile app, but
also helps to adjust apps that have already come out.
1.3 Organization
This thesis is the result of an Erasmus traineeship experience at Bournemouth University.
During the training period, there was a rst phase of study to understand how it was
possible to achieve the required results, followed by a second phase of implementation of
the idea.
In the rst stage of this thesis' work, most of the code consisted in a series of attempts
to try dierent approaches to the problem. All the focus went on to understand how was
it possible to develop a tool to extract needed data. The code of a simple web scraping
tool written in python was used to understand how a software like that could work, after
that the focus had shifted to an useful API for the project's porpouse, learning how to
use Selenium API.
1](https://image.slidesharecdn.com/5d5a28d9-a0a8-4490-aa45-c1912a813ffc-160813073233/85/Thesis-6-320.jpg)



![Chapter 3. Discussion
CHAPTER 3
DISCUSSION
3.1 The starting point
Nowadays we have a lot of data about every subject. This could be a preciuos resource
if we use it in the correct way. The problem faced in this thesis is how to extract data
automatically from Appennie website in order to realise an organized set of data that
is easily understandable and readable that can help apps' developers to make better
decisions. From this data set it will be easier to understand some trends of the market
and the reasons that increase or reduce the popularity of each app. it will focus on the
USA market and the chinese market.
3.2 The Approach
The software has been realised using an approach based on an iterative and incremental
development, inspired by agile programming practices [1]. The development was con-
ducted through weekly deliveries of working code, increasing every week the features and
the proprieties of the software. The testing phase was continued for the whole period of
development focusing on just coded parts and new implemented features weekly.
The most important data for this work are the name, the description and the versions
of each app, that are shown in the top 100 charts of Appannie website, for the last year.
To avoid having too much repetitions of data and to reduce the time to compute them, it
has been decided to extract the required data every two weeks, going as far back as one
year into the past. In this way the size of the sample is big enough and the day of the
week does not aect the misuring.
3.3 Appannie's structure
The website pages of interest are two:
1. Top 100 apps charts:
5](https://image.slidesharecdn.com/5d5a28d9-a0a8-4490-aa45-c1912a813ffc-160813073233/85/Thesis-10-320.jpg)
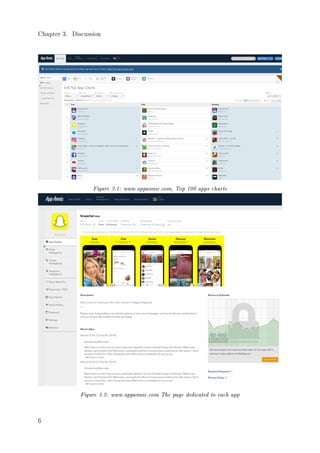
![Chapter 3. Discussion
The most popular 100 apps are shown by downloads in this page. There are 5 type
of charts: free, paid, grossing, new free, new paid. The existance of these lists
depends on the considerated country's market; In relationship to the markets
considerated in this work, in the USA one there are free, paid and grossing
charts, in the chinese one, all the ve types are present.
2. The page dedicated to each app:
There are details related to each app such as name, software house, description,
versions history, images, rewievs' distribution and other useless informations
for this work.
3.4 Selenium API
Selenium is a set of dierent software tools for browser automation and web scraping.
It is one of the most famous and used API for these aims, it can be used with dierent
languages and browsers. It is a very exible, versatile and easy to use set of tools. Using
it it's possible to automate the browser to surf on the website, to look for specic elements
in the HTML code and to extract pieces or pattern found [3].
3.5 Regular expressions
Regular expressions are used to look for everything in web scraping [4]. They are very
useful to extract writing from elements that contain a lot of text, or dierent types of
text (versions element for example) in order to better classify extracted data.
3.6 Browsers
The choice of using Mozilla Firefox was made for the following reasons:
1. One of the most used and reliable browsers
2. Free and open source code
3. The avability of a wide selection of extentions and add-ons to customise the browser's
behavior
3.7 The tool's development
3.7.1 The project
After a phase of feasibility study, some goals have been xed and it has been decided how
and what the tools have to do. It extracts from the top 100 charts of USA and chinese
markets the lists of apps on the charts, grouped by type of chart and country, so every list
is stored in separated CSV les. This process is iterated in order to extract charts every
2 weeks beginning from the current day (or a previusly chosen date) going backwards as
7](https://image.slidesharecdn.com/5d5a28d9-a0a8-4490-aa45-c1912a813ffc-160813073233/85/Thesis-12-320.jpg)
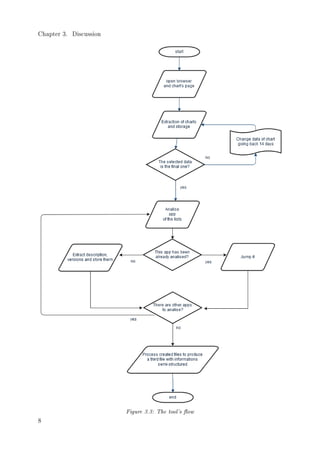
![Chapter 3. Discussion
far as one year into the past or into a specic date. After that, the tool reads recently
created CSV les and, for each url, it opens the browser using that url and extracting all
html code including pictures and saving descripton and history versions in a new CSV le
structured. Now we have all the required data and the tool can process them to produce
a new le where all the obtained informations are readable and understandable.
3.7.2 Opening the browser and Logging in
The rst step of the development was to automate the opening of the browser and to show
the page of an app. The rst problem has been how to automate the authentication in the
website. In fact the website shows data only to registered users. To solve this, selenium
functions Findelement to nd elements contaning username and password elds in the
welcome page, and Sendkeys to ll them with username and password have been used.
this.findElement(By.id(email)).sendKeys(new String []
{ user }); // Enter user
this.findElement(By.id(password)).sendKeys(new String
[] { pass }); // Enter Password
this.findElement(By.id(submit)).click (); // Click on
'Sign In' button
Listing 3.1: Login's automation
3.7.3 The scraping from app's page
In the rst weeks of the traineeship the attention has been focused in coding the core
of the tool, so in writing methods which extract target data from the selected web-
pages. For this stage, a random app page to test every little improvment has been
used, showing extracted data on the terminal of the IDE. Selenium API provides a
driver class which has been expanded with new methods in order to have all the fea-
tures of the original class and to customise them to manage better the surng and the
scraping. Filters of ndelement method that operate looking for the name of the class
inside the html code have been used. In this way it is possible to select just the use-
ful elements in the page, in this case description and the history of the versions.
List WebElement elements; // list of webelement to
store each webelement (paragraph)
WebElement elem;
By bySearch = By.className(app_content_section);
elements = this.findElements(bySearch);
Listing 3.2: Extracted by the method that extracts the description of each app
However, in most parts of app's pages, looking for and clicking on the button more
to show the complete element's text instead of a little rst part of it have been needed.
The problem was that not every page has a more button because some have a little
description that does not need to be expanded to be read. Generalising, this is a frequent
problem in web scraping tools because often, even with the same general structure html
9](https://image.slidesharecdn.com/5d5a28d9-a0a8-4490-aa45-c1912a813ffc-160813073233/85/Thesis-14-320.jpg)
![Chapter 3. Discussion
page, the target element can be hidden in some pages and visible in dierent ones. To
solve that 2 dierent solutions with Selenium API can be used:
1. ndelement with try catch:
This solution of the problem uses exceptions risen by Selenium API in the Findele-
ment method. Findelement can nd an element but if the element is not found
an exception is risen. So it's possible to manage the exception to continue to
run the code even if the miss is not a problem.
2. ndelements with checking on the resultant list:
A dierent solution is to use the FindElements method. FindElements can nd a
undened number of matches but if it nds no element, no exception is risen
and the resultant list will be empty, so it is easy to check the size of the list to
understand if at least one element was found.
There are some pros and cons for each solution: The rst one has the advantage to be
faster if the probability to nd the target element is high, in fact when it nds the element
it stop itself and the next line code is processed. The second one is better when we have
to look for an element but the rst found could not be the searched one so we need to
continue the reaserch. the rts solution has been used in order to get faster operations.
3.7.4 How to save data to CSV le
To save data on a CSV le standard libreries of java to write on les has been used.
The structure of the resultant le is made up of three columns: URL, descrpition and
versions. For the versions elds each version has been divided in order to have only one
version for each eld in the CSV le. To create the splitting using regular expression has
been needed to match all dierent versions of each app (in the html code all versions are
together in the same element) and to put each one in a dierent eld of CSV le.
3.7.5 Web scraping on the chart webpages
This step has represented the most dicult part of the work [5]. The html structure
of this page is complex and dierent for each country, so the code has to generalise
problems and nd consistent solutions. Also, this page uses AJAX to manage the date's
drop-down menu and this is a typical problem when a scraper tool is designed [5].
10](https://image.slidesharecdn.com/5d5a28d9-a0a8-4490-aa45-c1912a813ffc-160813073233/85/Thesis-15-320.jpg)
















![Bibliography
BIBLIOGRAPHY
[1] Kent Beck, Mike Beedle, Arie Van Bennekum, Alistair Cockburn, Ward Cunningham,
Martin Fowler, James Grenning, Jim Highsmith, Andrew Hunt, Ron Jeries, et al.
Manifesto for agile software development. 2001.
[2] Michael Bolin, Matthew Webber, Philip Rha, Tom Wilson, and Robert C Miller.
Automation and customization of rendered web pages. In Proceedings of the 18th
annual ACM symposium on User interface software and technology, pages 163172.
ACM, 2005.
[3] http://www.seleniumhq.org/docs/index.jsp. Selenium documentation.
[4] Simon Munzert, Peter Rubba, Christian, and Dominic Nyhuis. Automated data col-
lection with R: A practical guide to web scraping and text mining. John Wiley Sons,
2014.
[5] Michael Schrenk. Webbots, spiders, and screen scrapers: A guide to developing Internet
agents with PHP/CURL. No Starch Press, 2012.
27](https://image.slidesharecdn.com/5d5a28d9-a0a8-4490-aa45-c1912a813ffc-160813073233/85/Thesis-32-320.jpg)




























