Downloaded 78 times



![Analyzers
The quick brown fox jumped over the lazy dog,
bob@hotmail.com 123432.
StandardAnalyzer:
[quick] [brown] [fox] [jumped] [over] [lazy] [dog] [bob@hotmail.com] [123432]
StopAnalyzer:
[quick] [brown] [fox] [jumped] [over] [lazy] [dog] [bob] [hotmail] [com]
SimpleAnalyzer:
[the] [quick] [brown] [fox] [jumped] [over] [the] [lazy] [dog] [bob] [hotmail]
[com]
WhitespaceAnalyzer:
[The] [quick] [brown] [fox] [jumped] [over] [the] [lazy] [dog,]
[bob@hotmail.com] [123432.]
KeywordAnalyzer:
[The quick brown fox jumped over the lazy dog, bob@hotmail.com 123432.]](https://image.slidesharecdn.com/elasticsearchplugins-140527194610-phpapp02/85/The-ultimate-guide-for-Elasticsearch-plugins-12-320.jpg)


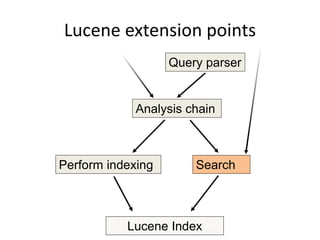


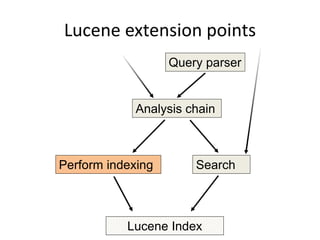

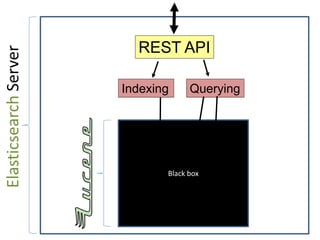















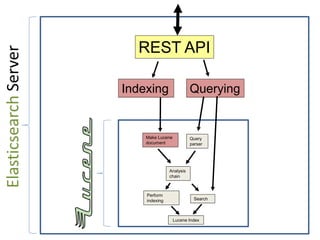
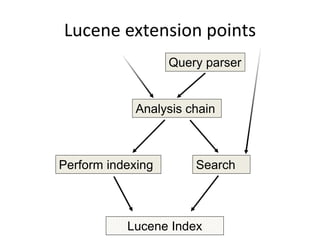
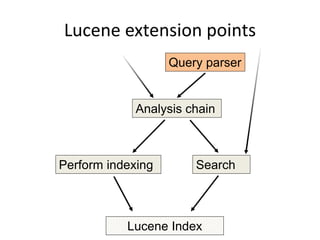
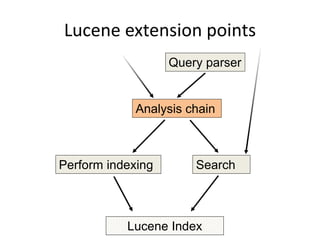
This document discusses Elasticsearch plugins, including: - The different types of plugins like analysis, scripting, and site plugins - Integration points in Elasticsearch that can be extended by plugins - Examples of plugins like custom analyzers and percolators - Considerations for writing plugins like maintenance, versioning, and testing - How to package and install plugins within Elasticsearch



































































