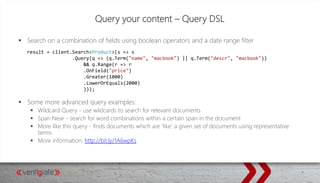
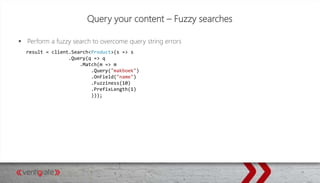
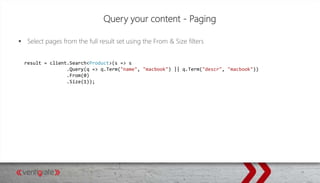
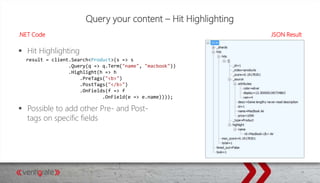
Downloaded 25 times
















![Text Analysis- Adding Custom Analyzers
PUT /my-index/_settings
{
"index":
{
"analysis":
{
"analyzer":
{
“YourCustomAnalyzer":
{
"type": "custom",
"char_filter": [ "html_strip" ],
"tokenizer": "standard",
“filter": [ "lowercase", "stop", "snowball" ]
}
}
}
}
}
A list of available analysis tools:
CharacterFilters: http://bit.ly/1H3hgJF
Tokenizers: http://bit.ly/1zIU2IO
Token filters: http://bit.ly/1AJXCO2
Possible to create your own combination!](https://image.slidesharecdn.com/bootcamp-elasticsearch-150529104328-lva1-app6891/85/ElasticSearch-for-NET-Developers-21-320.jpg)




![Index your Content - .NET
Raw JSON string
Type based indexation
Modify out-of-the-box behavior using decorators
client.Raw.Index("products", "product", new JavaScriptSerializer().Serialize(prod));
client.Index(product);
[ElasticType(Name = "Product", IdProperty="id")]
public class Product
{
public int id { get; set; }
[ElasticProperty(Name = "name", Index = FieldIndexOption.Analyzed, Type = FieldType.String, Analyzer =
"standard")]
public string name { get; set; }](https://image.slidesharecdn.com/bootcamp-elasticsearch-150529104328-lva1-app6891/85/ElasticSearch-for-NET-Developers-27-320.jpg)



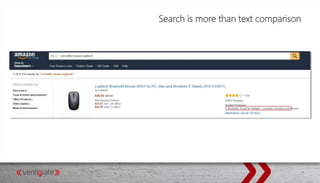
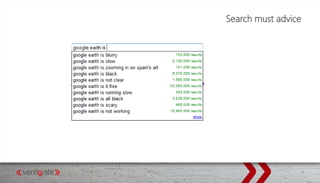
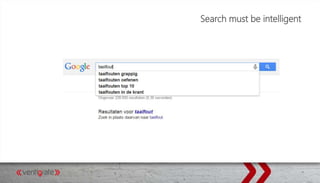
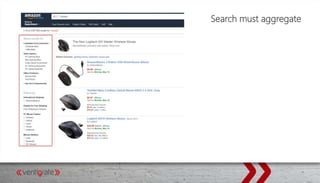
This document provides an overview of Elasticsearch and how to use it with .NET. It discusses what Elasticsearch is, how to install it, how Elasticsearch provides scalability through its architecture of clusters, nodes, shards and replicas. It also covers topics like indexing and querying data through the REST API or NEST client for .NET, performing searches, aggregations, highlighting hits, handling human language through analyzers, and using suggesters.















![Getting the most out of Java [Nordic Coding-2010]](https://cdn.slidesharecdn.com/ss_thumbnails/getting-the-most-out-of-java-nordiccoding2010v1-101203063620-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)






![PHP Experience 2016 - [Workshop] Elastic Search: Turbinando sua aplicação PHP](https://cdn.slidesharecdn.com/ss_thumbnails/14h00brenooliveira-160331182512-thumbnail.jpg?width=640&height=640&fit=bounds)

![[제1회 루씬 한글분석기 기술세미나] solr로 나만의 검색엔진을 만들어보자](https://cdn.slidesharecdn.com/ss_thumbnails/1solr-130414211148-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)









































