Downloaded 89 times















![Discovery
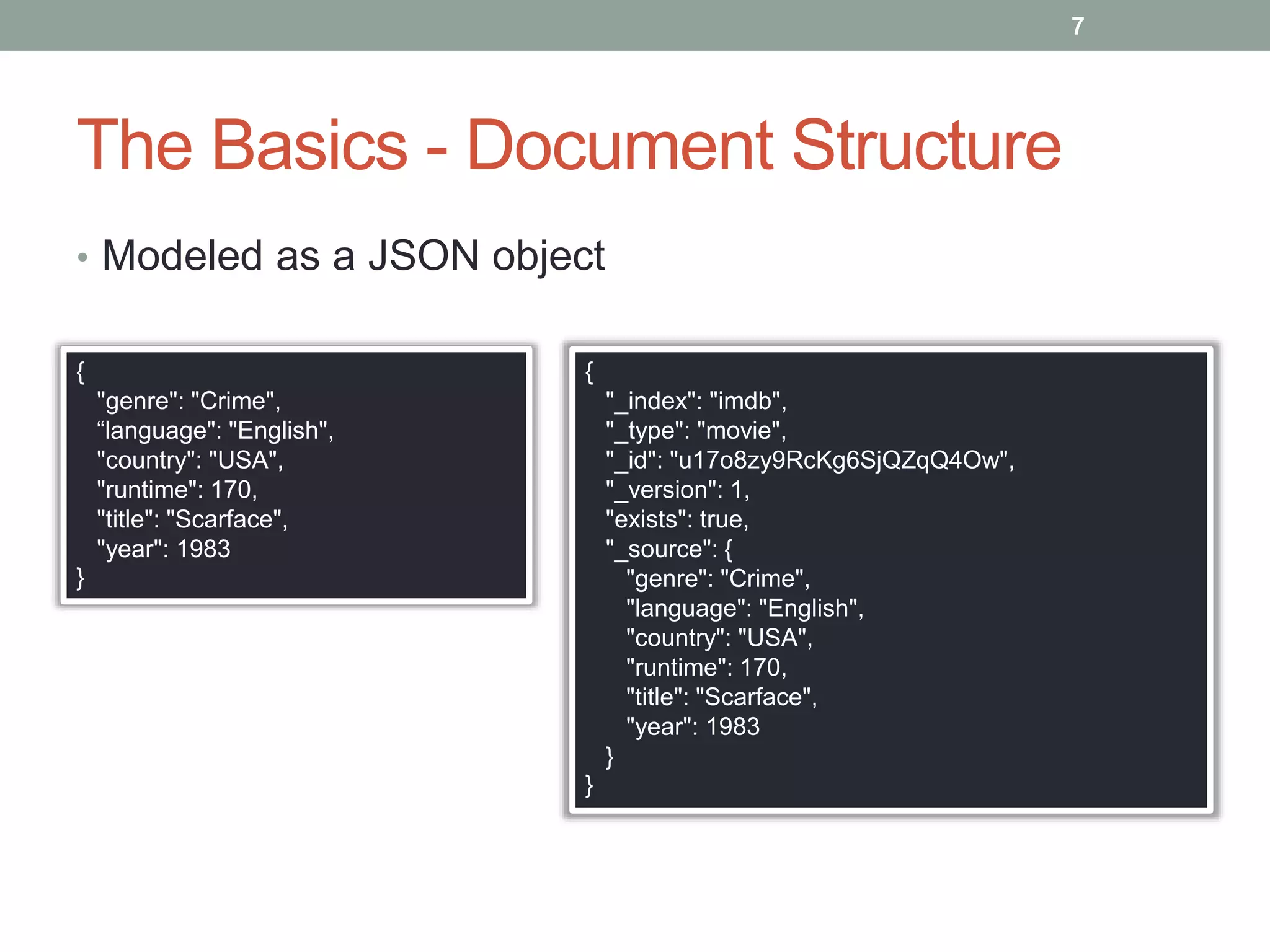
• Nodes discover each other using multicast.
• Unicast is an option
• Each cluster has an elected master node
• Beware of split-brain
• discovery.zen.minimum_master_nodes
• N/2+1, where N>2
• N: # of master nodes in cluster
19
discovery.zen.ping.multicast.enabled: false
discovery.zen.ping.unicast.hosts: ["host1", "host2:port", "host3"]](https://image.slidesharecdn.com/ajuges-140109110240-phpapp01/75/ElasticSearch-AJUG-2013-19-2048.jpg)






![REST API
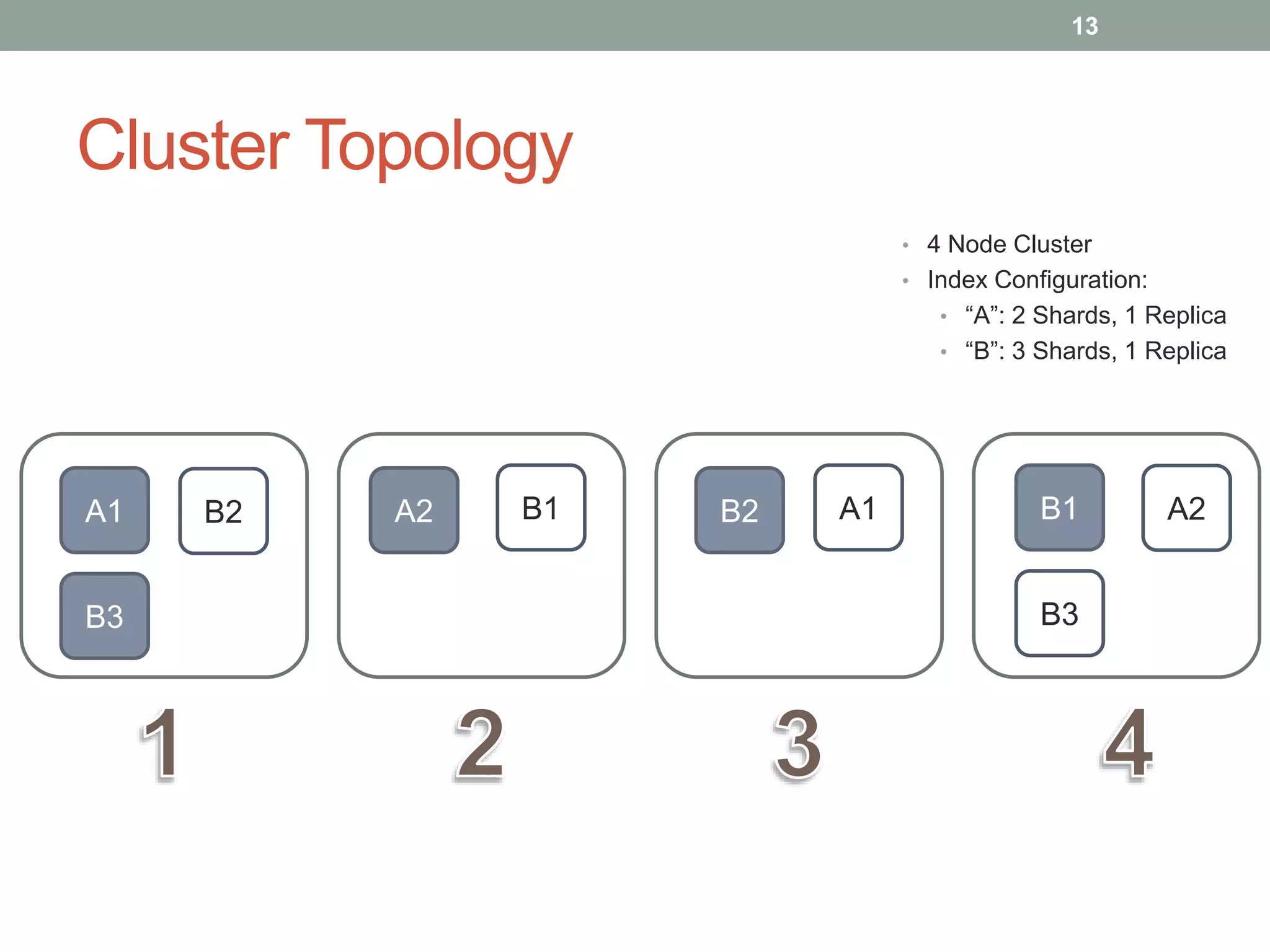
• Exists
• No overhead in loading
• Status Code Result
• Delete
• Get
• Multi-Get
27
{
"docs" : [
{
"_id" : "1"
"_index" : "imdb"
"_type" : "movie"
},
{
"_id" : "5"
"_index" : "oldmovies"
"_type" : "movie"
"_fields" " ["title", "genre"]
}
]
}](https://image.slidesharecdn.com/ajuges-140109110240-phpapp01/75/ElasticSearch-AJUG-2013-27-2048.jpg)
![REST API - Search
• Free Text Search
• URL Request
• http://localhost:9200/imdb/movie/_search?q=scar*
• Complex Query
• http://localhost:9200/imdb/movie/_search?q=scarface+OR
+star
• http://localhost:9200/imdb/movie/_search?q=(scarface+O
R+star)+AND+year:[1981+TO+1984]
• Term, Boolean, range, fuzzy, etc…
28](https://image.slidesharecdn.com/ajuges-140109110240-phpapp01/75/ElasticSearch-AJUG-2013-28-2048.jpg)
![REST API - Search
• Search Types:
• http://localhost:9200/imdb/movie/_search?q=(scarface+OR+star)+A
ND+year:[1981+TO+1984]&search_type=count
• http://localhost:9200/imdb/movie/_search?q=(scarface+OR+star)+A
ND+year:[1981+TO+1984]&search_type=query_then_fetch
• Query and Fetch:
• Executes on all shards and return results
• Query then Fetch:
• Executes on all shards. Only some information returned for rank/sort,
only the relevant shards are asked for data
29](https://image.slidesharecdn.com/ajuges-140109110240-phpapp01/75/ElasticSearch-AJUG-2013-29-2048.jpg)
![REST API – Query DSL
30
http://localhost:9200/imdb/movie/_search?q=(scarface+OR+star)+AND+year:[1981+TO+1984]
curl -XPOST 'localhost:9200/_search?pretty' -d '{
"query" : {
"bool" : {
"must" : [
{
"query_string" : {
"query" : “scarface or star"
}
},
{
"range" : {
“year" : { "gte" : 1981 }
}
}
]
}
}
}'
Becomes…](https://image.slidesharecdn.com/ajuges-140109110240-phpapp01/75/ElasticSearch-AJUG-2013-30-2048.jpg)
![REST API – Query DSL
• Query String Request use Lucene query syntax
• Limited
• Error-prone
• Instead use “match” query
31
curl -XPOST 'localhost:9200/_search?pretty' -d '{
"query" : {
"bool" : {
"must" : [
{
“match" : {
“message" : “scarface star"
}
},
{
"range" : {
“year" : { "gte" : 1981 }
}
}
]
…
Automatically builds
a boolean query](https://image.slidesharecdn.com/ajuges-140109110240-phpapp01/75/ElasticSearch-AJUG-2013-31-2048.jpg)
![REST API – Query DSL
• Match Query
• Boolean Query
• Must: document must match query
• Must_not: document must not match query
• Should: document doesn’t have to match
• If it matches… higher score
• Compound queries
32
{
"bool":{
"must":[
{
"match":{
"color":"blue"
}
},
{
"match":{
"title":"shirt"
}
}
],
"must_not":[
{
"match":{
"size":"xxl"
}
}
],
"should":[
{
"match":{
"textile":"cotton"
}
{
“match”:{
“title”:{
“type”:“phrase”,
“query”:“quick fox”,
“slop”:1
}
}
}](https://image.slidesharecdn.com/ajuges-140109110240-phpapp01/75/ElasticSearch-AJUG-2013-32-2048.jpg)



![Percolate API
• Reversing Search
• Store queries and filter (percolate) documents through them.
36
curl -XPUT localhost:9200/_percolator/stocks/alert-on-nokia -d '{
"query" : {
"boolean" : {
"must" : [
{ "term" : { "company" : "NOK" }},
{ "range" : { "value" : { "lt" : "2.5" }}}
]
}
}
}'
curl -X GET localhost:9200/stocks/stock/_percolate -d '{
"doc" : {
"company" : "NOK",
"value" : 2.4
}
}'](https://image.slidesharecdn.com/ajuges-140109110240-phpapp01/75/ElasticSearch-AJUG-2013-36-2048.jpg)

![Stuff I didn’t cover…
• Analyzers
• Tokenizers
• Token Filters
• Rivers
• RabbitMQ, MySQL, JDBC
38
$ curl -XGET
'localhost:9200/_analyze?tokenizer=whitespace&filters=lowercase
,stop&pretty=1' -d '
The quick Fox Jumped
'
{
"tokens" : [ {
"token" : "quick",
"start_offset" : 5,
"end_offset" : 10,
"type" : "word",
"position" : 2
}, {
"token" : "fox",
"start_offset" : 11,
"end_offset" : 14,
"type" : "word",
"position" : 3
}, {
"token" : "jumped",
"start_offset" : 15,
"end_offset" : 21,
"type" : "word",
"position" : 4
} ]
}](https://image.slidesharecdn.com/ajuges-140109110240-phpapp01/75/ElasticSearch-AJUG-2013-38-2048.jpg)



This document provides an introduction to Elasticsearch, covering the basics, concepts, data structure, inverted index, REST API, bulk API, percolator, Java integration, and topics not covered. It discusses how Elasticsearch is a document-oriented search engine that allows indexing and searching of JSON documents without schemas. Documents are distributed across shards and replicas for horizontal scaling and high availability. The REST API and query DSL allow full-text search and filtering of documents.









































![[2 d1] elasticsearch 성능 최적화](https://cdn.slidesharecdn.com/ss_thumbnails/2d1elasticsearch-140930233029-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)














































