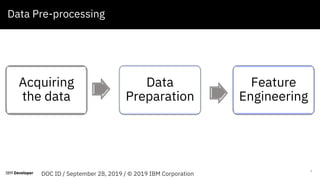
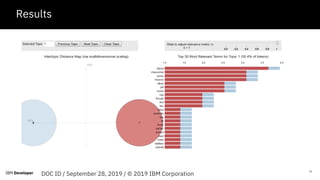
The document discusses text summarization and visualization using IBM Watson Studio. It provides an agenda that includes an introduction to topic modeling and LDA, how to build a topic model, and a Q&A section. The document explains that topic modeling can be used to quickly summarize text, extract important topics, and create visualizations for better data understanding. It also outlines the steps involved, including data preprocessing, feature engineering, and LDA modeling to probabilistically assign words to topics.




















![Basic Grammar Svagr[2]](https://cdn.slidesharecdn.com/ss_thumbnails/svagr2-140219072319-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)













![Document Clustering using LDA | Haridas Narayanaswamy [Pramati]](https://cdn.slidesharecdn.com/ss_thumbnails/documentclusteringusinglda-190430091535-thumbnail.jpg?width=640&height=640&fit=bounds)
































