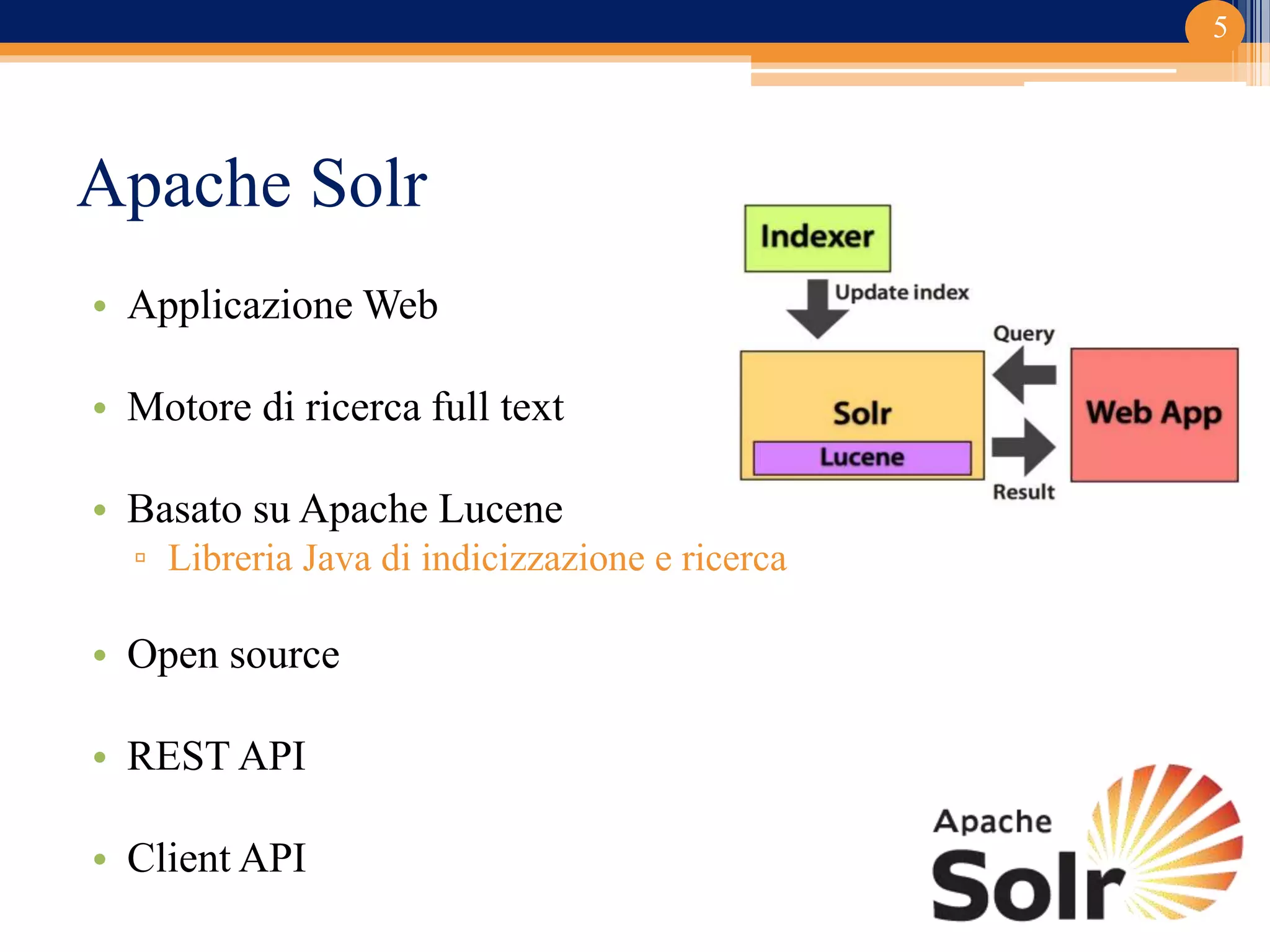
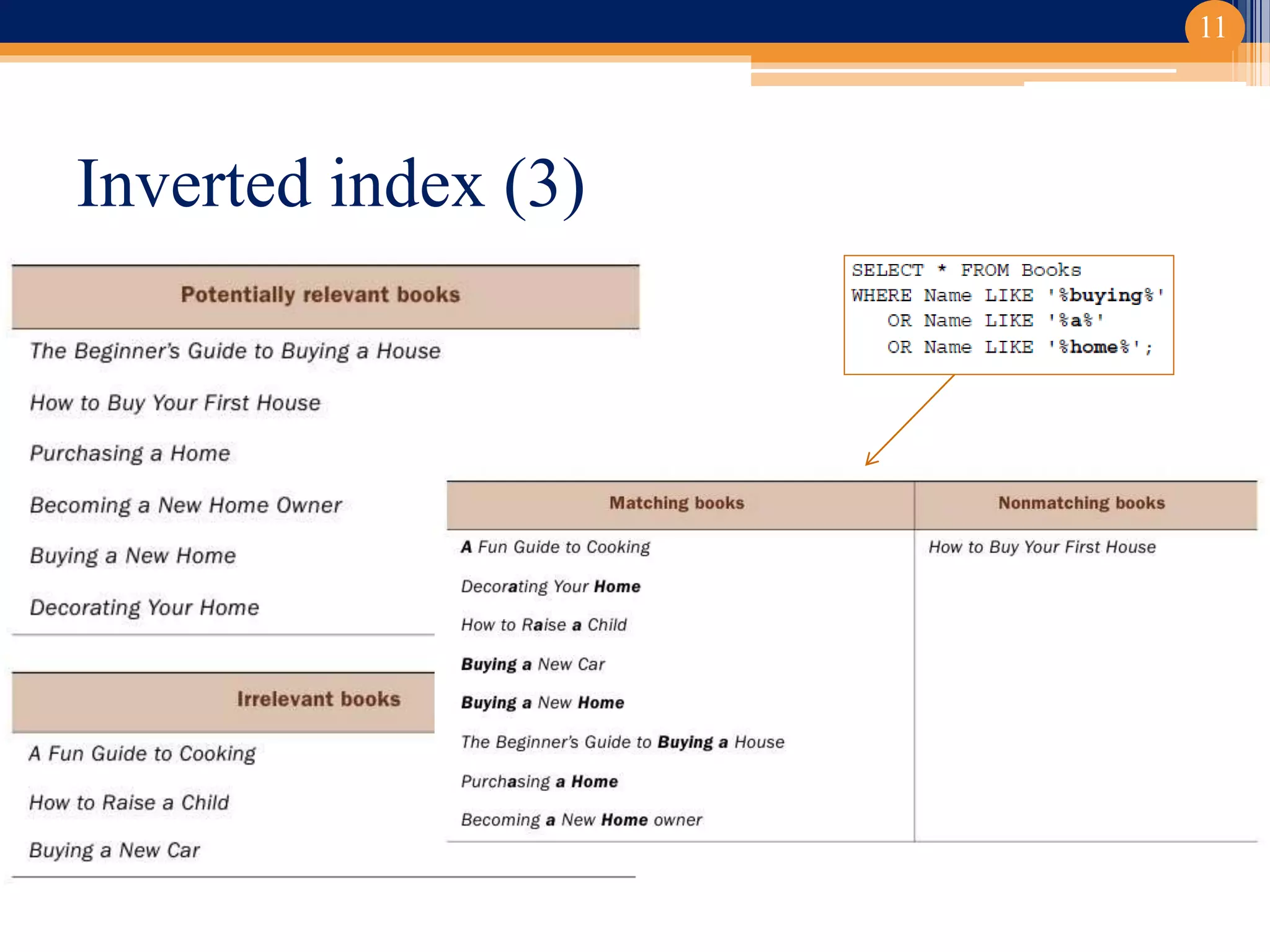
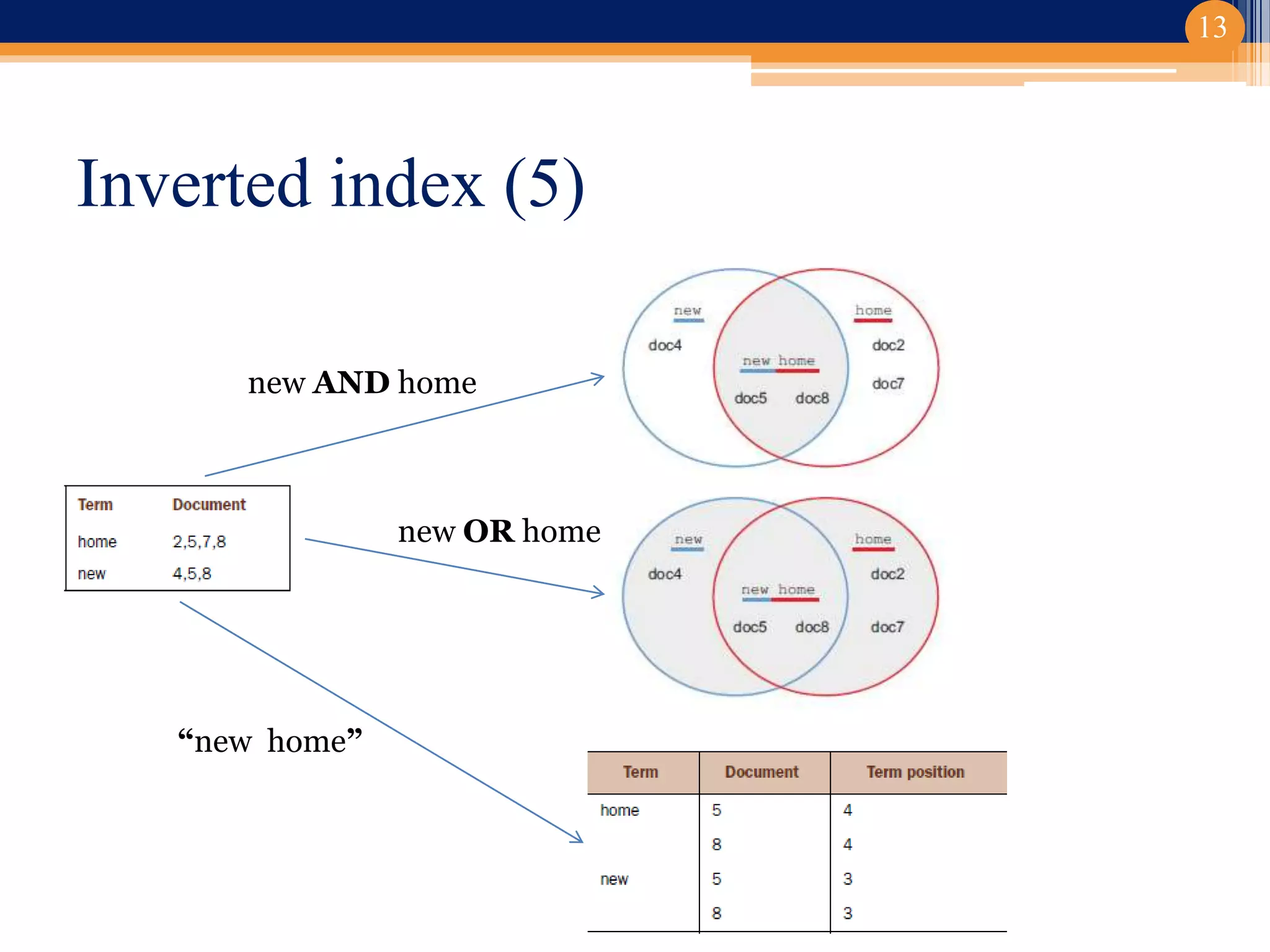
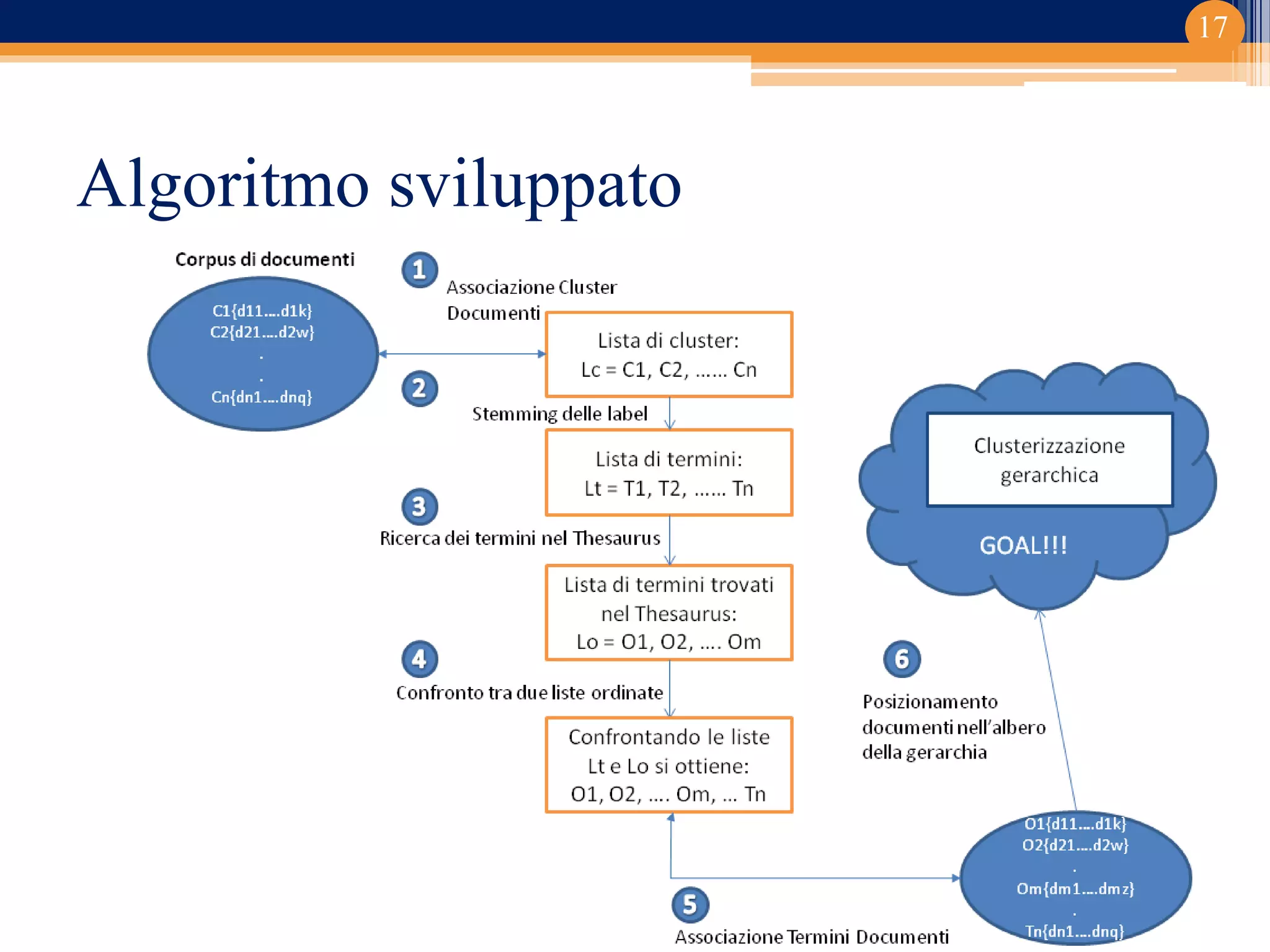
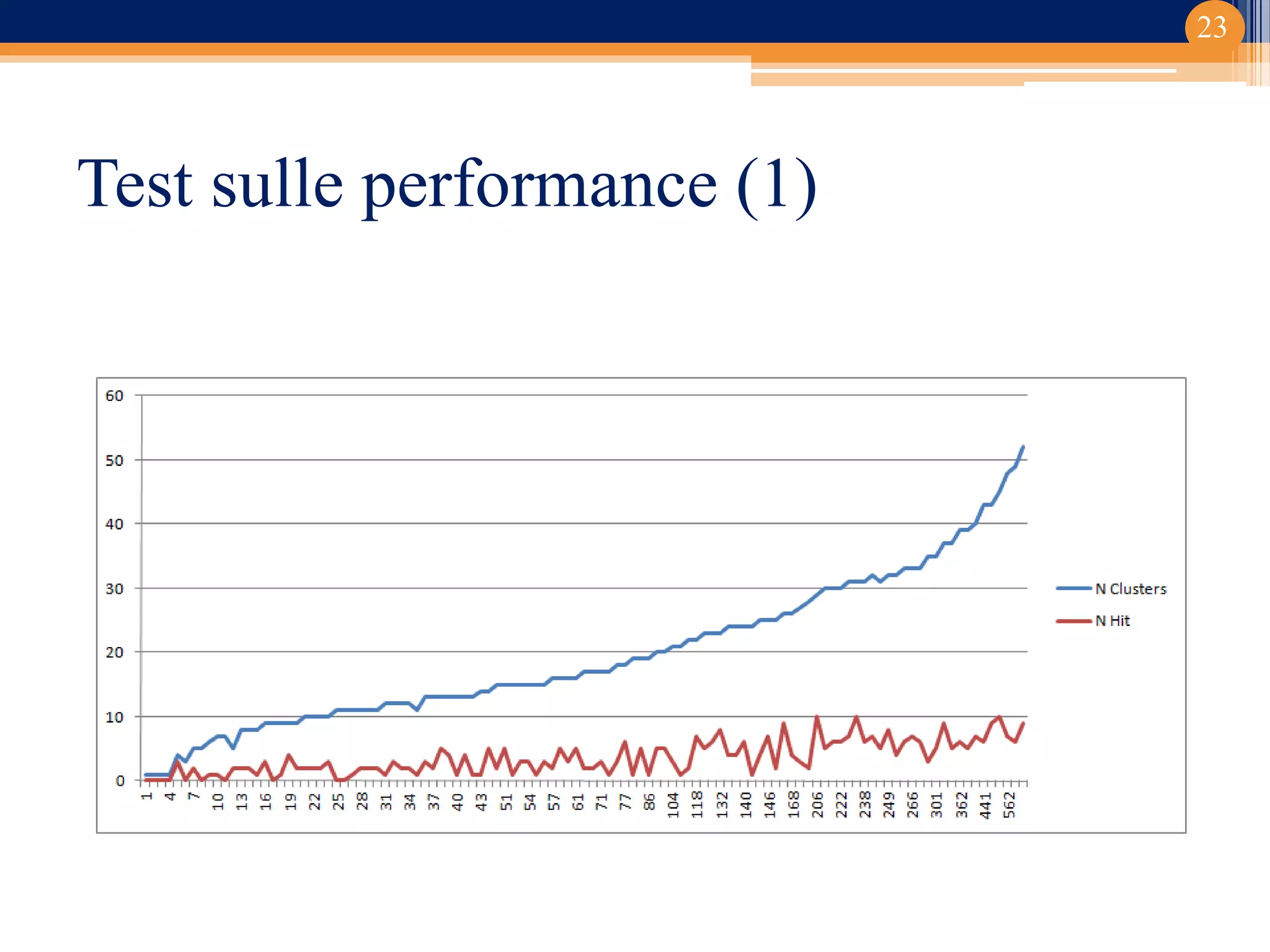
Il progetto ha riguardato lo sviluppo di un componente di ricerca semantica basato su Apache Solr per la classificazione dei documenti. Implementato in un contesto universitario con un focus su clustering e gestione documentale, il lavoro ha prodotta un editor di thesaurus e diverse funzionalità avanzate. Le conclusioni indicano potenziali sviluppi futuri, inclusi studi su relazioni trasversali e sinonimie.