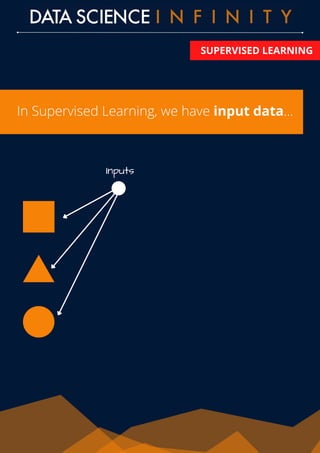
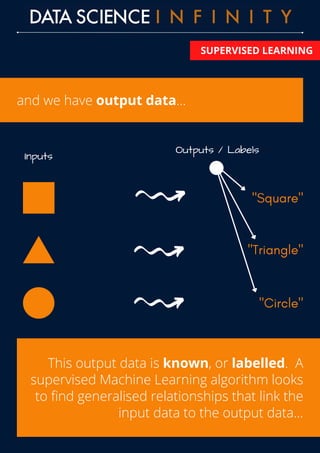
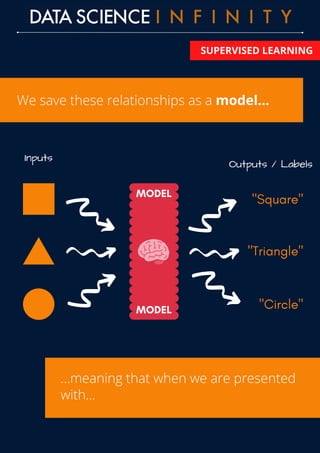
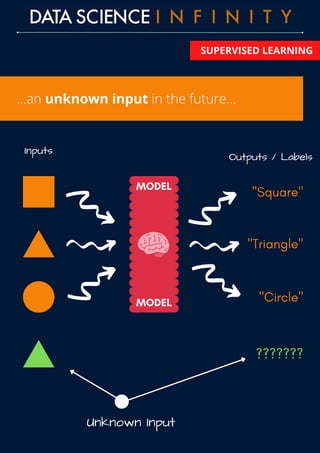
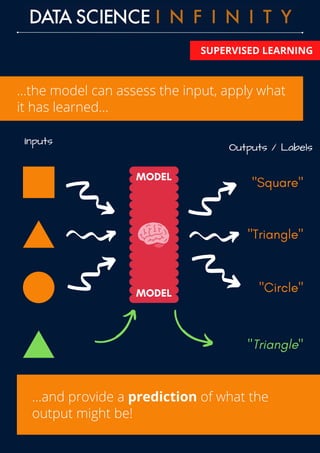
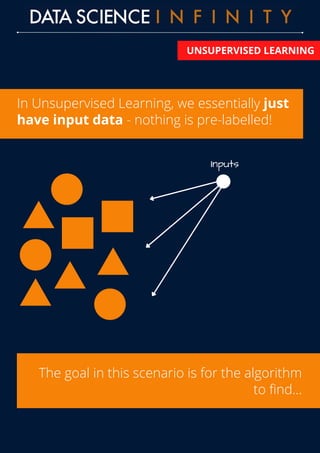
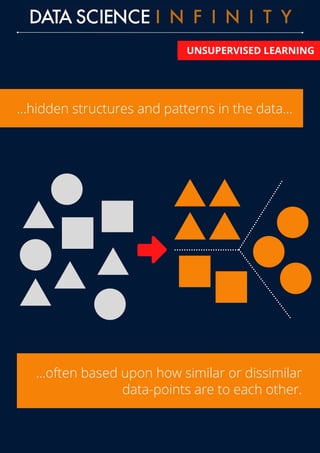
The document outlines the differences between supervised and unsupervised learning in machine learning, highlighting how supervised learning uses labeled data to predict outputs based on input relationships, while unsupervised learning aims to identify hidden structures in unlabeled data. It provides examples of common algorithms used in each area, such as linear regression and k-means clustering. Additionally, the document promotes a data science course that offers skill development, portfolio building, and career placement support.