SQL Server 2012’deIndex
Kavramı Performance Tuning ve
Query Optimization
2.
INDEX YÖNETİMİ:
lndex;bir veri tabanı içinde bulunan verileri hızlı açmak daha
doğrusu hızlı sorgulamak için çok gerekli olan bir yapıdır.
Ancak zamanla index yapısı bozulabilir ve bunun yeniden
yapılandırılması gerekir. İşte bu yüzden veri tabanı
yöneticisinin; index oluşturma(Create
lndex), değiştirme(Alter Index) ve silme(Drop lndex)
işlemlerini çok iyi bilmesi gerekmektedir.
SQL Server 2012 içinde bir veri sayfası (Data Page) içindeki
bir satır(Row) lokasyonuna index uygulanabilir. Bu da bir
tablodaki tüm veri sayfalarına uygulanan yönteme göre
avantajlar sağlar.
Index yapısı, veri tabanının performansını arttırmak için
kullanılır. Bu kısımda temel index yapısını nerede ve nasıl
kullanacağımızı inceleyeceğiz.
3.
Neden Index ?
SQL Server açısından index kullanımının en
önemli amacı, istenen bilginin daha az veri
okunarak daha kısa zamanda getirilmesini
sağlamaktır.
Index kullanarak bir tablonun tamamını
okumaktansa index key vasıtasıyla okumak
istediğimiz kayıda daha hızlı bir şekilde
ulaşmamız mümkündür.
Tamamlanması saatler süren bir sorgunun
uygun index’ler kullanılarak saniyeler
seviyesinde getirilmesi sağlanabilir.
Telefon rehberi index kullanımı için iyi bir
örnektir. (Karışık Rehber – Sıralı Rehber)
Canlı örnek - table scan-index kullanımı
arasındaki fark
Gerekli index’ler faydalı olduğu gibi çok fazla
index kullanımı performans sıkıntısı doğurur.
4.
Index Nasıl Çalışır? (B-Tree – Balanced Tree
Yapısı)
Index’in çalışma prensibini
anlamak, Index tipine ve Index’in hangi
kolonlar üzerine tanımlanması
gerektiğine karar verme aşamaları için
oldukça önem taşımaktadır.
Client İsteği -> Protocol Layer -> Parse -
> Query Processor
Query Processor = Optimize + Execute
Optimize = En Uygun Index’ten Query
Plan Oluşturulur.
Execute = Bu aşamada Index üzerinde
B-Tree yapısı kullanılarak arama yapılır.
5.
Index Nasıl Çalışır? (B-Tree – Balanced Tree
Yapısı)
1 Level Root
1 veya 1’den fazla Intermediate Level
1 Level Leaf
Index’lerde B-Tree Yapısı
NonLeaf Level
6.
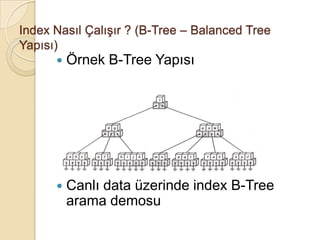
Index Nasıl Çalışır? (B-Tree – Balanced Tree
Yapısı)
Örnek B-Tree Yapısı
Canlı data üzerinde index B-Tree
arama demosu
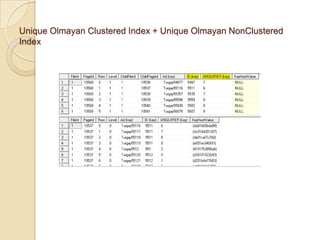
7.
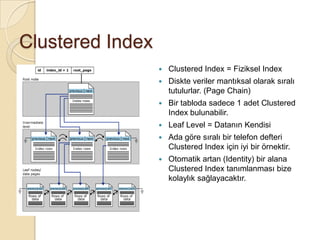
Clustered Index
ClusteredIndex = Fiziksel Index
Diskte veriler mantıksal olarak sıralı
tutulurlar. (Page Chain)
Bir tabloda sadece 1 adet Clustered
Index bulunabilir.
Leaf Level = Datanın Kendisi
Ada göre sıralı bir telefon defteri
Clustered Index için iyi bir örnektir.
Otomatik artan (Identity) bir alana
Clustered Index tanımlanması bize
kolaylık sağlayacaktır.
8.
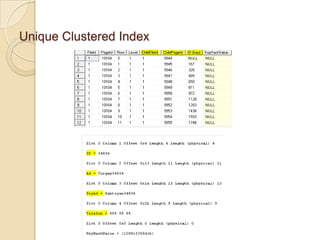
Clustered Index NonLeafLevel Page Örneği
ChildFileId
ChildPageId
Id – Clustered Index Key
UNIQUIFIER – Key’i Unique’leştirmek İçin Kullanılır. (4 byte Integer)
Alt Level Page’lere Erişmek İçin Kullanılır
9.
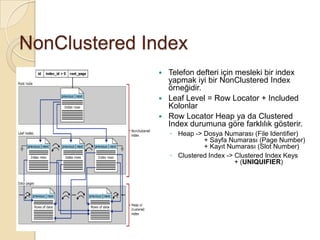
NonClustered Index
Telefondefteri için mesleki bir index
yapmak iyi bir NonClustered Index
örneğidir.
Leaf Level = Row Locator + Included
Kolonlar
Row Locator Heap ya da Clustered
Index durumuna göre farklılık gösterir.
◦ Heap -> Dosya Numarası (File Identifier)
+ Sayfa Numarası (Page Number)
+ Kayıt Numarası (Slot Number)
◦ Clustered Index -> Clustered Index Keys
+ (UNIQUIFIER)
10.
NonClustered Index NonLeafLevel Page Örneği
ChildFileId
ChildPageId
Ad – NonClustered Index Key
Id – Clustered Index Key
UNIQUIFIER(*) – Key’i Unique’leştirmek İçin Kullanılır. (4 byte Integer)
Alt Level Page’lere Erişmek İçin Kullanılır
*Bir key’in unique olup olmaması index tanımlanırken kullanılan UNIQUE ifadesine bağlıdır.
11.
NonClustered Index LeafLevel Page Örneği
Ad – NonClustered Index Key
SoyAd – Included Column
Id – Clustered Index Key
UNIQUIFIER
SoyAd– Included Column
Lookup yapmak için kullanılır.
12.
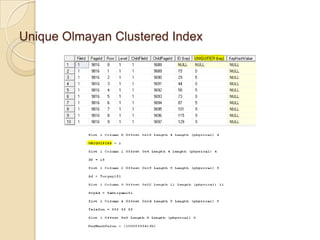
Örneklerle Index Page’lerinİncelenmesi
Clustered Index’te Page’lerin Yapısı
◦ Unique Clustered Index
◦ Unique Olmayan Clustered Index
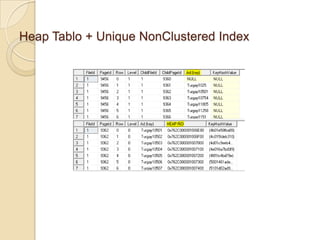
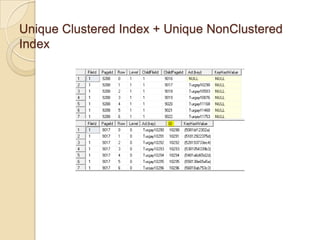
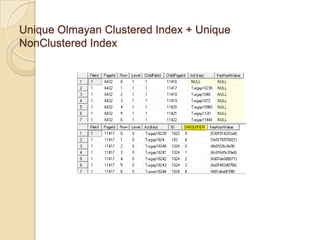
NonClustered Index’te Page’lerin Yapısı
◦ Heap Tablo + Unique NonClustered Index
◦ Unique Clustered Index + Unique NonClustered Index
◦ Unique Olmayan Clustered Index + Unique NonClustered
Index
◦ Unique Olmayan Clustered Index + Unique Olmayan
NonClustered Index
NonClustered Index’te IncludedKolon Kullanımı
SQL Server 2005 ile gelen bir özelliktir.
Amaç sorguyu cover edip lookup yapmamaktır.
Covering Index = Lookup yapma ihtiyacı olmadan istenen tüm
bilgileri leaf level page’lerinde bulunduran NonClustered Index’lerdir.
NonLeaf Level Page’lerde covering column’u bulundurmayıp boyutu
arttırmadan sadece leaf level page’lerde bulundurmayı amaçlar.
Telefon Rehberi için verilen mesleki NonClustered Index örneği
Included kolon ile yapılırsa lookup’tan kurtulunur.
Canlı Örnek - %1.2 daha az index boyutu
◦ Composite Index – (örn. 25.41 MB)
create nonclustered index IX_1 on Person.Address
(City,AddressLine1,PostalCode)
◦ Included Index – (örn. 25.16 MB)
create nonclustered index IX_1 on Person.Address
(City) INCLUDE (AddressLine1,PostalCode)
20.
STATİSTİCS
Statistics bilgiler, birindex veya bir sütun için uygulanabilir. Bu kısımda, bunları nasıl
gerçekleştireceğimizi inceleyeceğiz.
STATİSTİCS OLUŞTURMA ve GÜNCELLEME:
İstatistik bilgiler, sysyindexes tablosu içinde bulunan statblob sütununda tutulur.
Image veri tipine sahip bu sütunda bulunan bilgiler;
İstatistiklerin en son güncellendiği, tarih ve saat.
Tablo içindeki satırların sayısı.
Histogram ve Density bilgileri.
Ortalama key uzunluğu.
Histogram yapısında benzersiz değerler.
Statistics, otomatik veya manuel olarak oluşturulabilir.
21.
Manuel Oluşturmak İçin:
CREATESTATİSTİCS ifadesi ile manuel
olarak, istatistik bilgileri oluşturulabilir. Bu ifadeyi
kullanabilmek için, mutlaka tablonun sahibi olmak
gerekir.
Oluşturabileceğimiz istatistik seçenekleri;
--lndex'lenmemiş sütunlar,
--Composite index içindeki ilk sütun dışında kalan
sütunlar,
--Koşul verilmiş computed sütunlar,
--Image, text ve ntext veri tiplerine sahip olmayan
sütunlar.
22.
Otomatik Olarak Oluşturmakİçin:
Veri tabanı üzerinde sağ tuşa basılarak
Properties seçeneğine tıklanır ve gelen
iletişim kutusundan Options sayfasına
geçilerek, Auto Create Statistics değeri
True yapılır. Varsayılan olarak bu zaten
True değerindedir. Otomatik Statistics
devreye sokulduğu zaman, index
sütununda bulunan veriler ve index'siz
sütunlardan JOIN veya VVHERE ifadesi
kullananların istatistikleri, otomatik olarak
oluşturur
23.
UPDATE STATİSTİCS
UPDATE STATİSTİCSkomutu ile
manuel olarak, Statistics
güncellenebilir.
Aşağıdaki durumlarda istatistiklerin
güncellenmesi gerekebilir;
-- Tablo içine herhangi bir kayıt girmeden
önce index oluşturulacaksa,
--Tablo truncated ise,
--Çok az aynı tür veri içeren birçok
kayıt, tabloya ekleniyorsa.
24.
Sonuç - Özet
Index’i SQL Server’ın beygir gücü olarak tanımlayabiliriz. Etkin index
kullanımı verinin sorgulanması ihtiyacını daha etkin bir şekilde
karşılamak için göz önünde bulundurulması gereken en önemli
konudur
Clustered ve NonClustered Index’lerin davranışları farklı olduğu için
bu 2 index tipi arasındaki farkı bilmek Index oluşturma açısından
önemlidir.
Index’lerin B-Tree yapısının ne şekilde çalıştığı bir diğer önemli
konudur.
Index’lerin tanımlanmış olması, sürekli performanslı bir çalışma
getireceği manasına gelmez. Periyodik olarak Index’lerin bakımının
yapılması Index performansına etki eden önemli faktörlerden biridir.
Index kullanımı çok önemliyken, gereksiz,kullanılmayan Index’leri
sistemde bulundurmak bir o kadar dezavantajdır. Periyodik olarak
kullanılmayan ya da yazma istatistiği okuma istatistiğinden fazla olan
index’lerin belirlenip drop edilmesi gerekir
Aynı şekilde olması gerekipte olmayan index’lerin (Missing Index)