Download as PDF, PPTX





















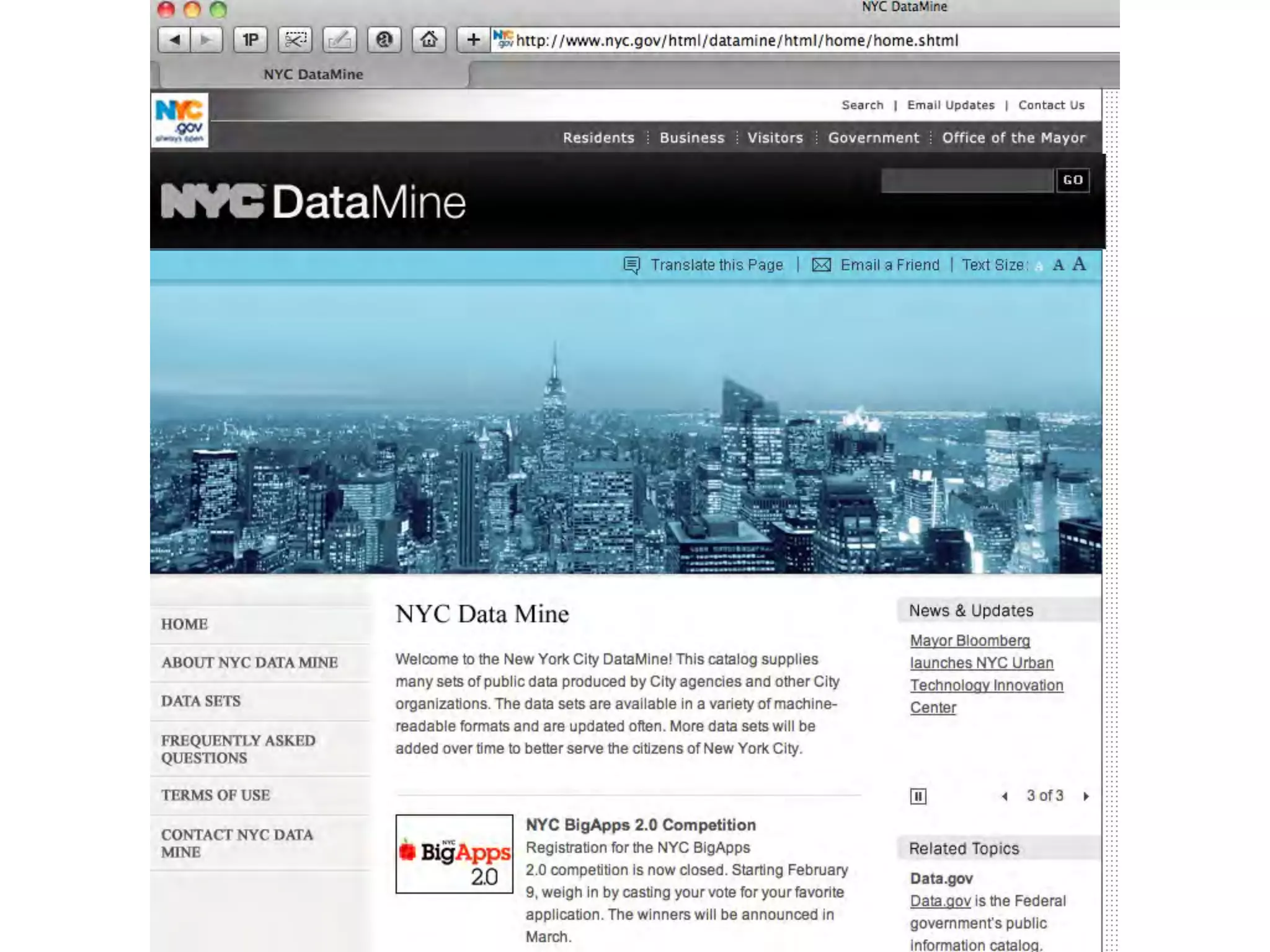


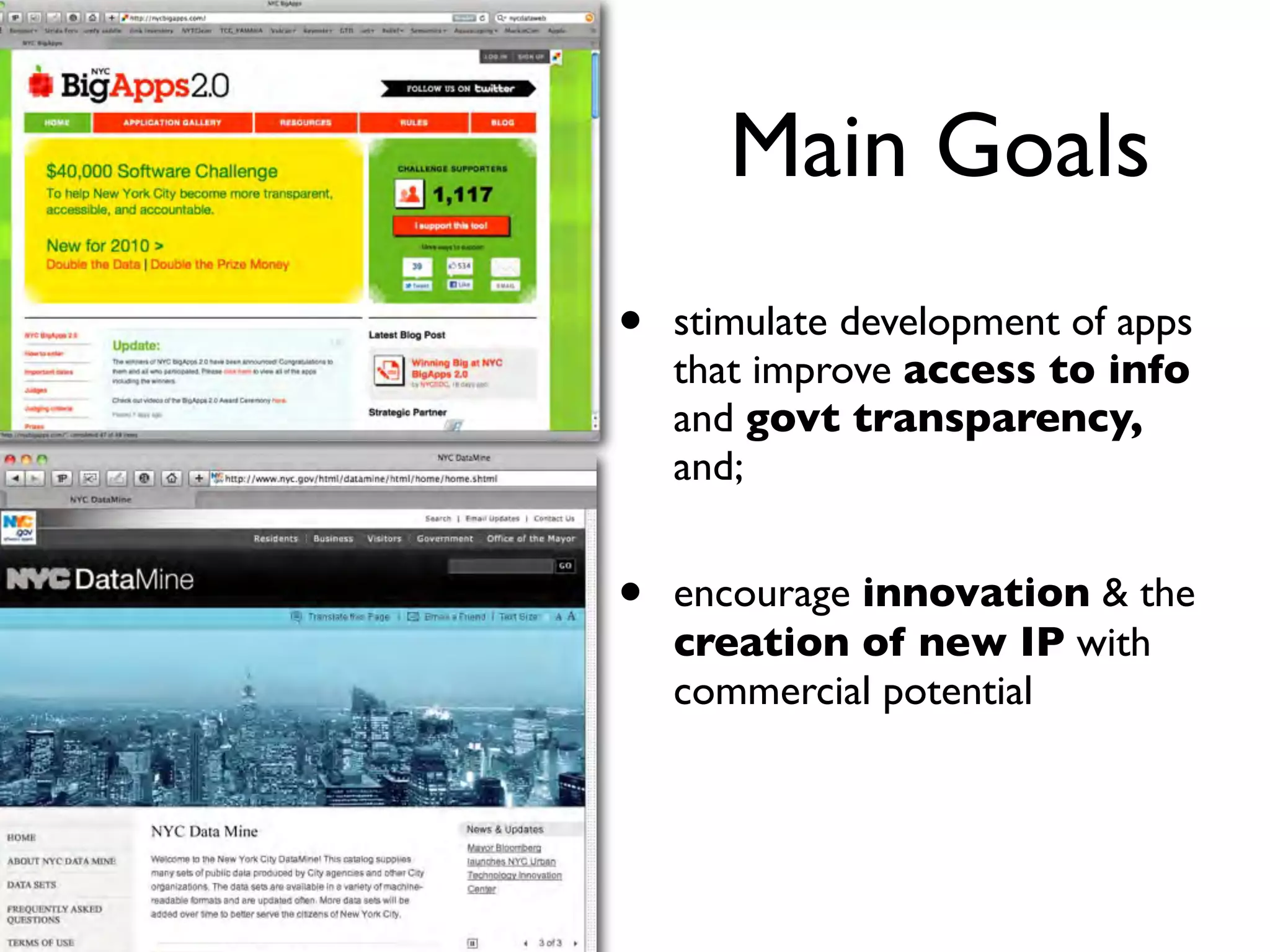
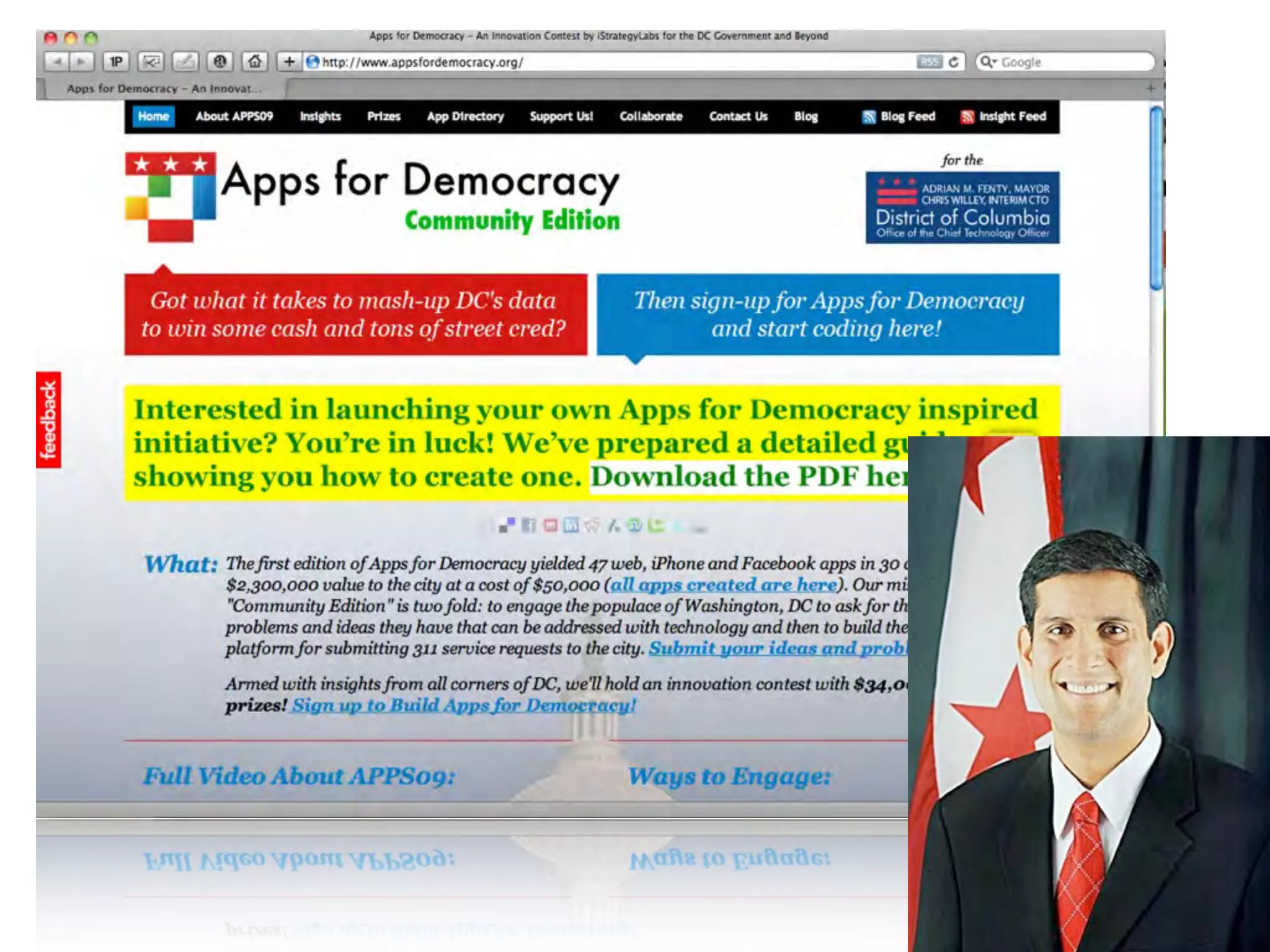










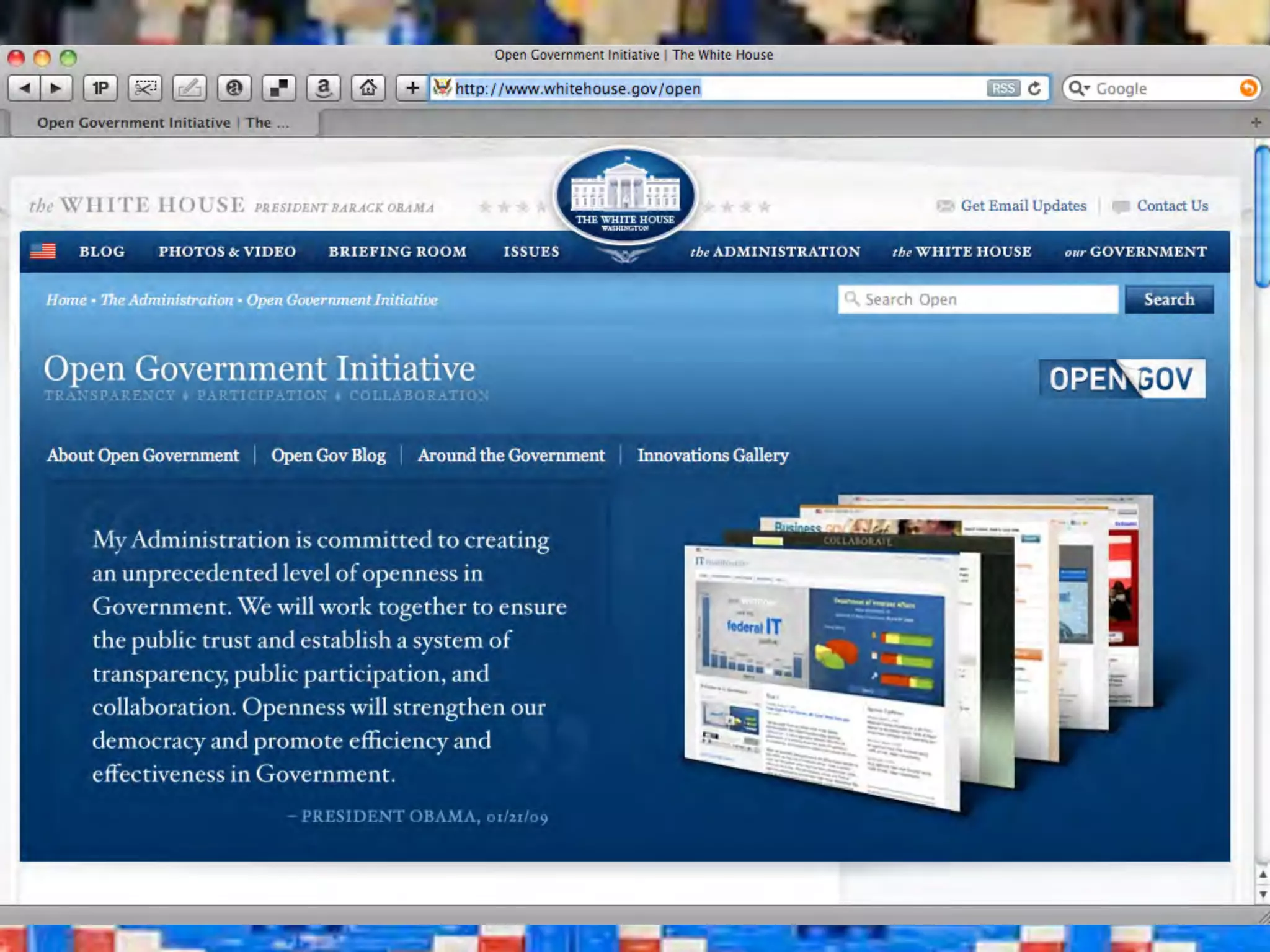
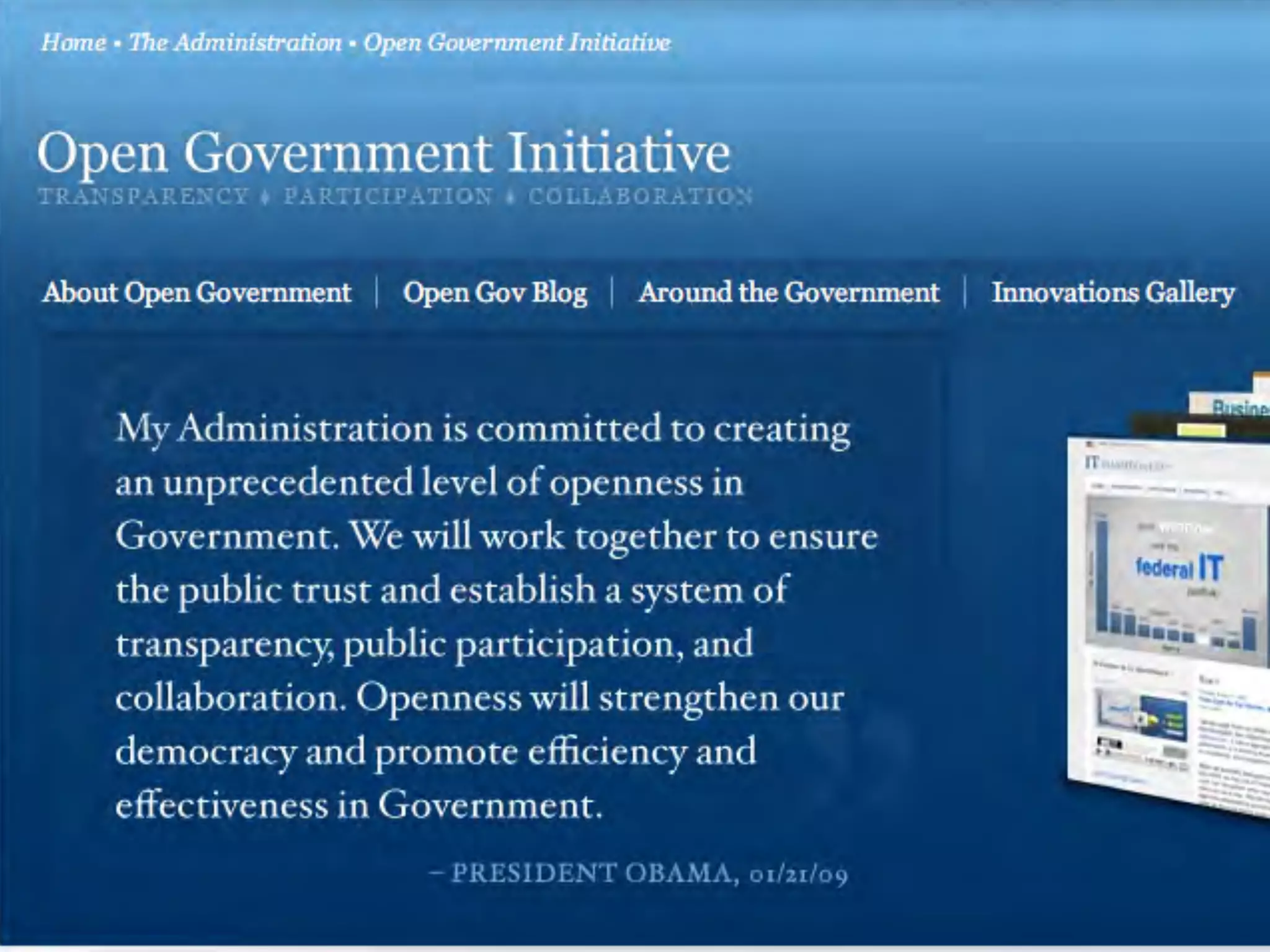














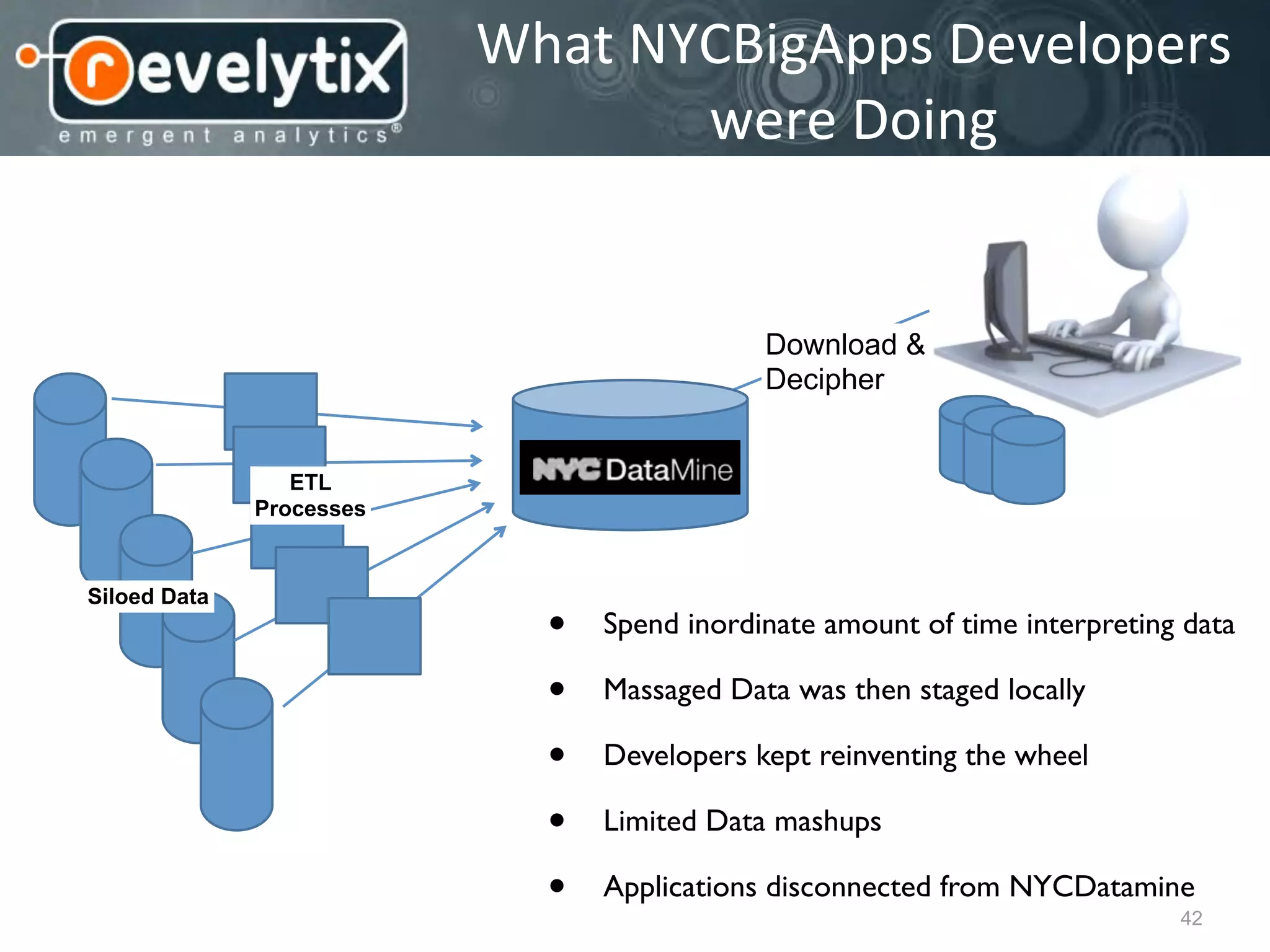


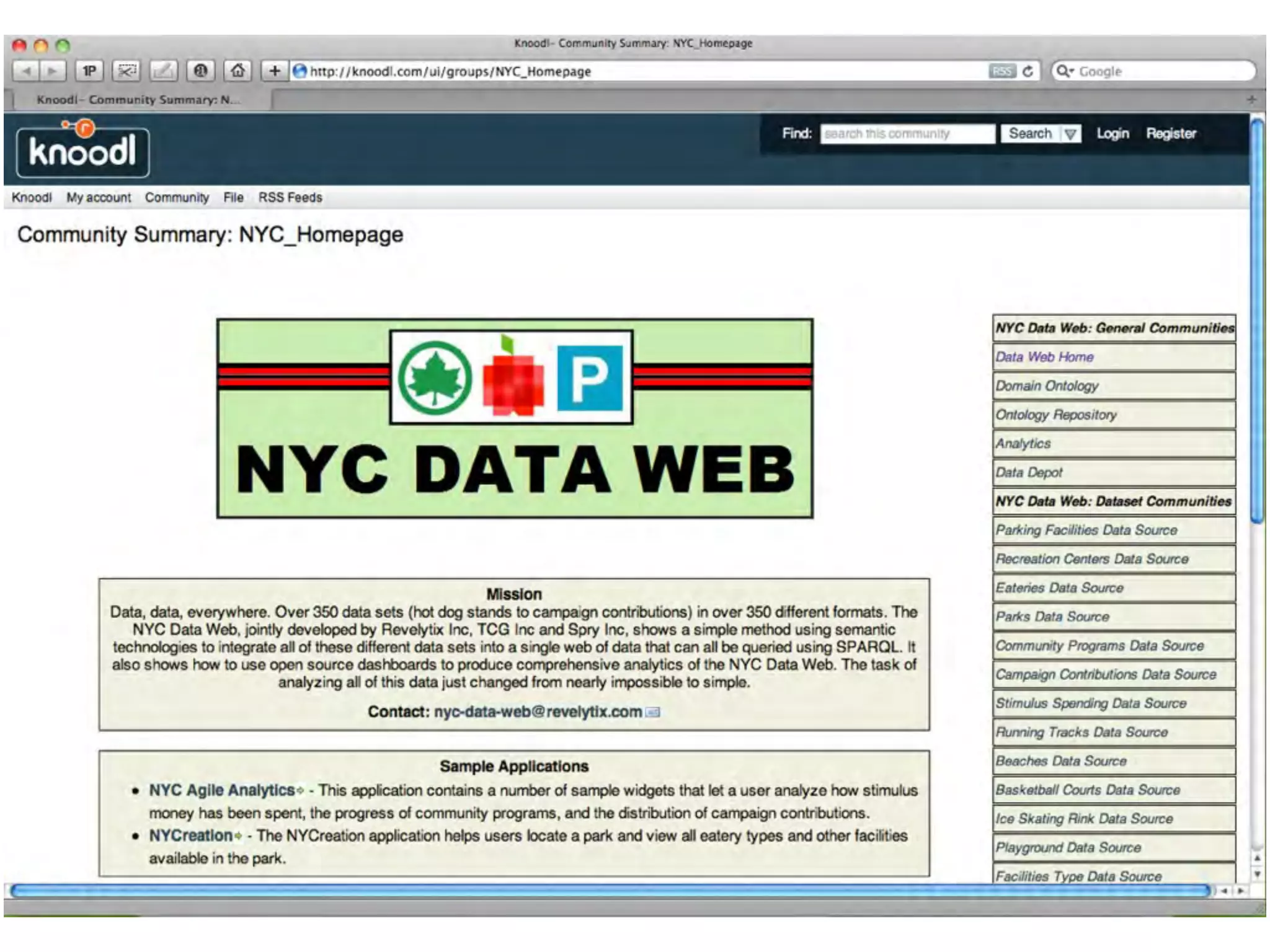
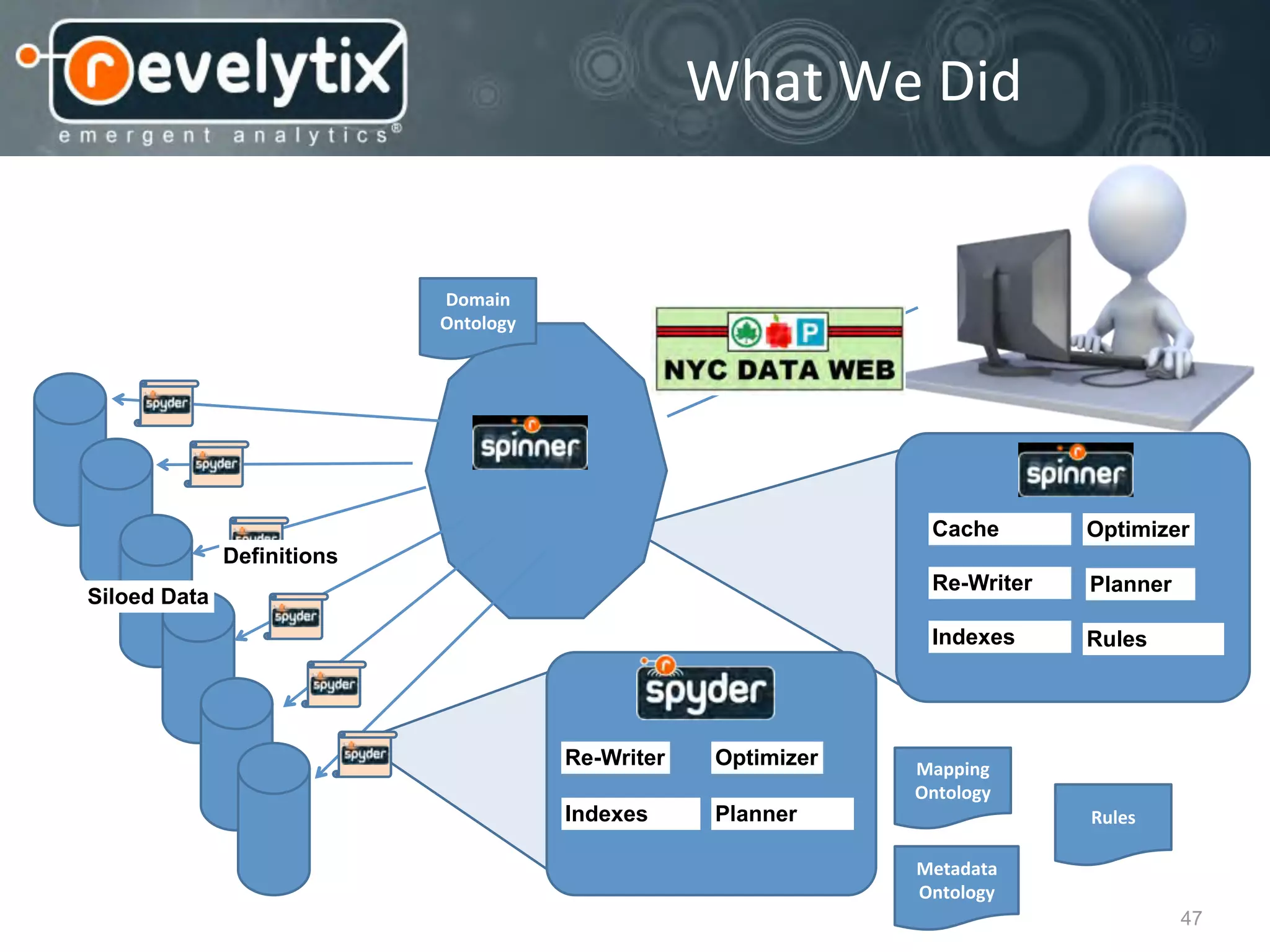


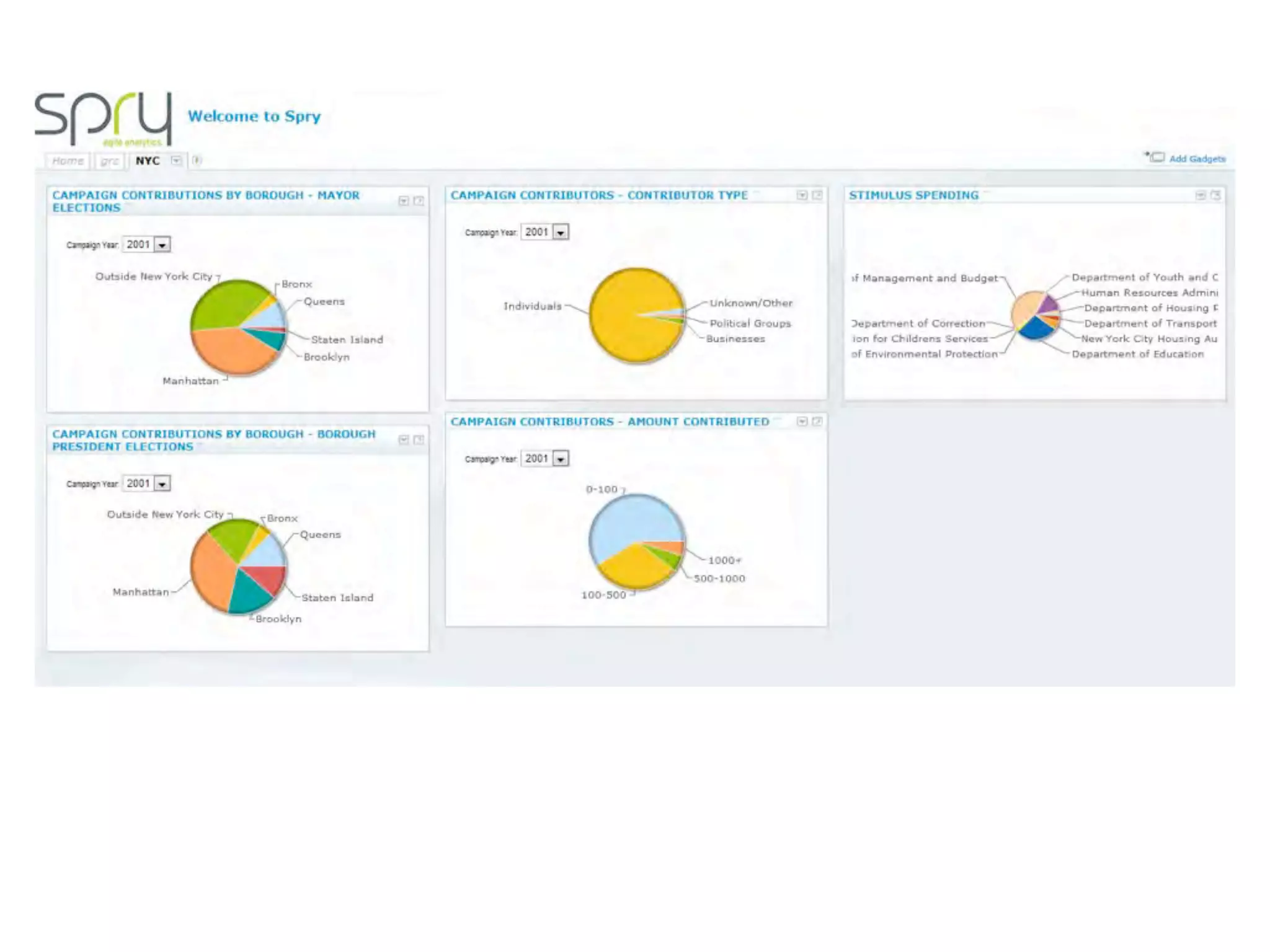
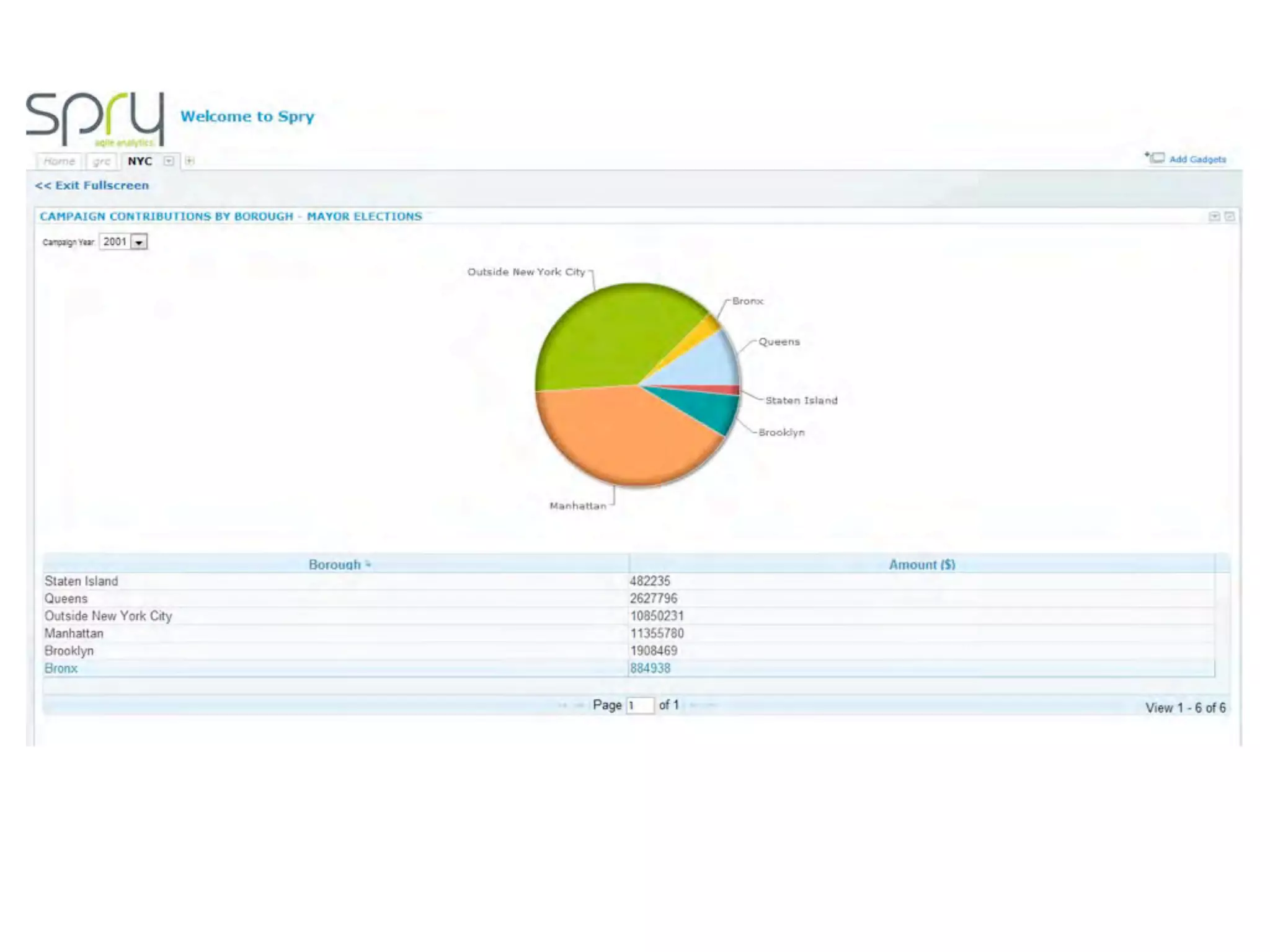
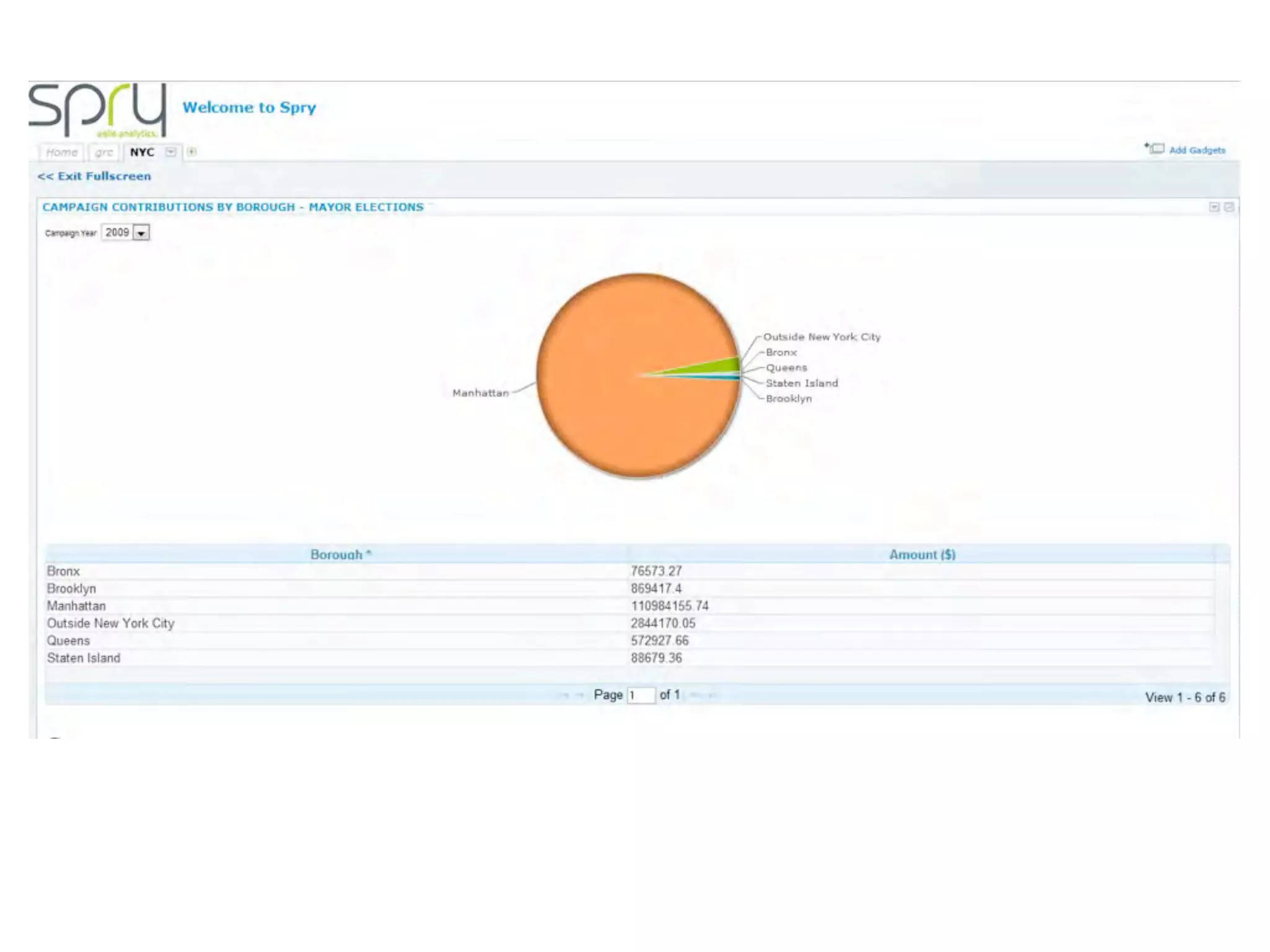
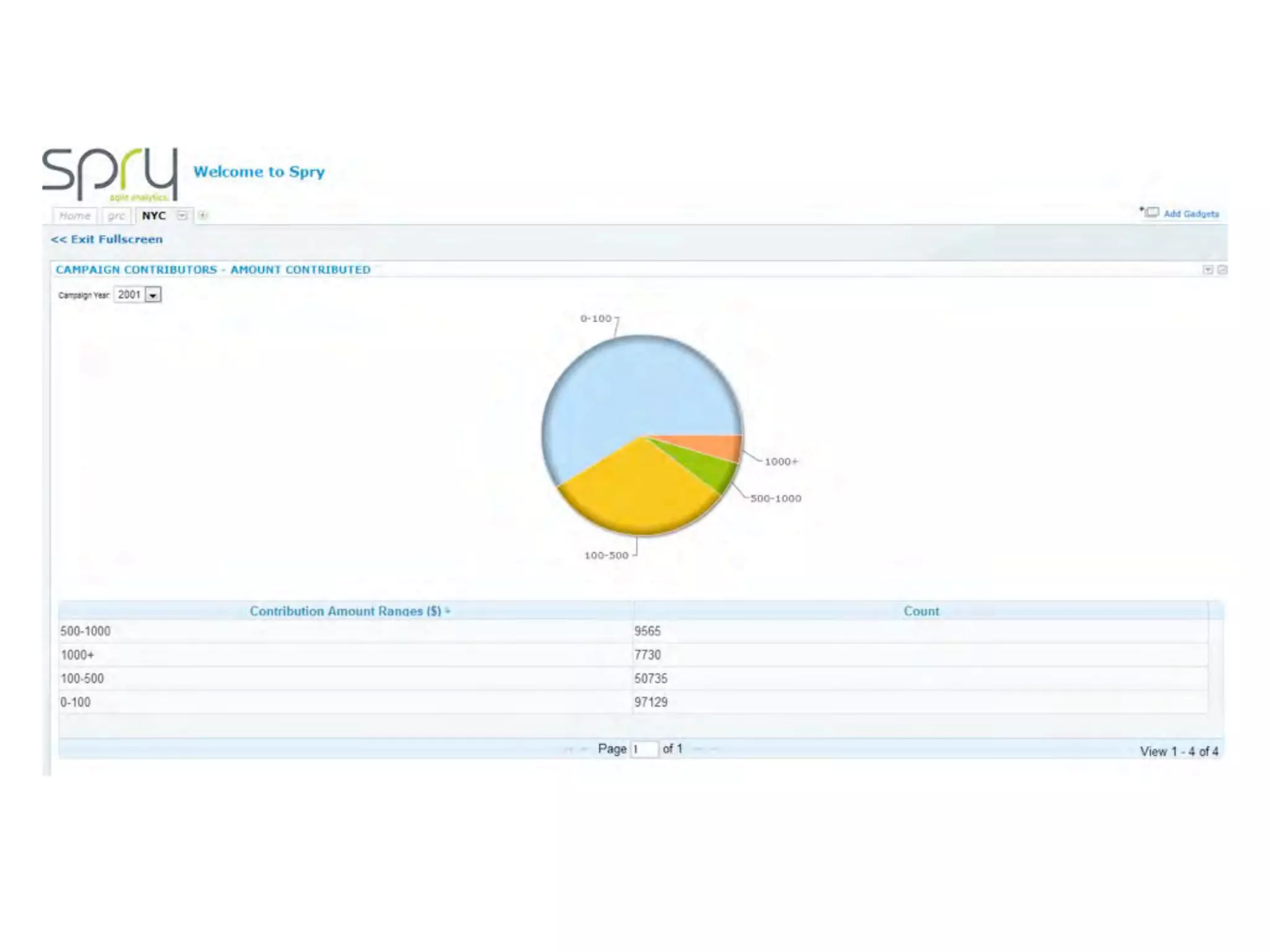
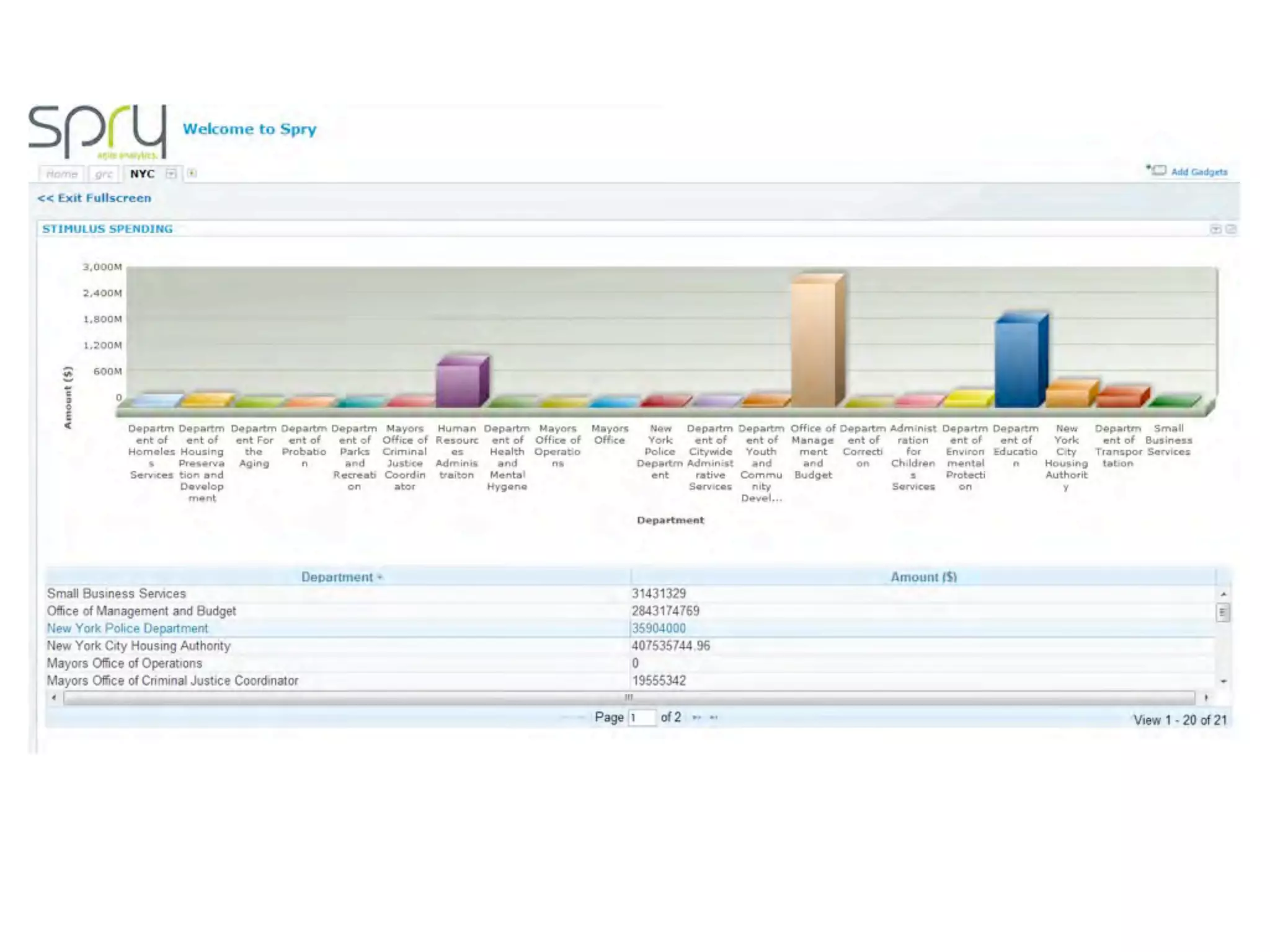
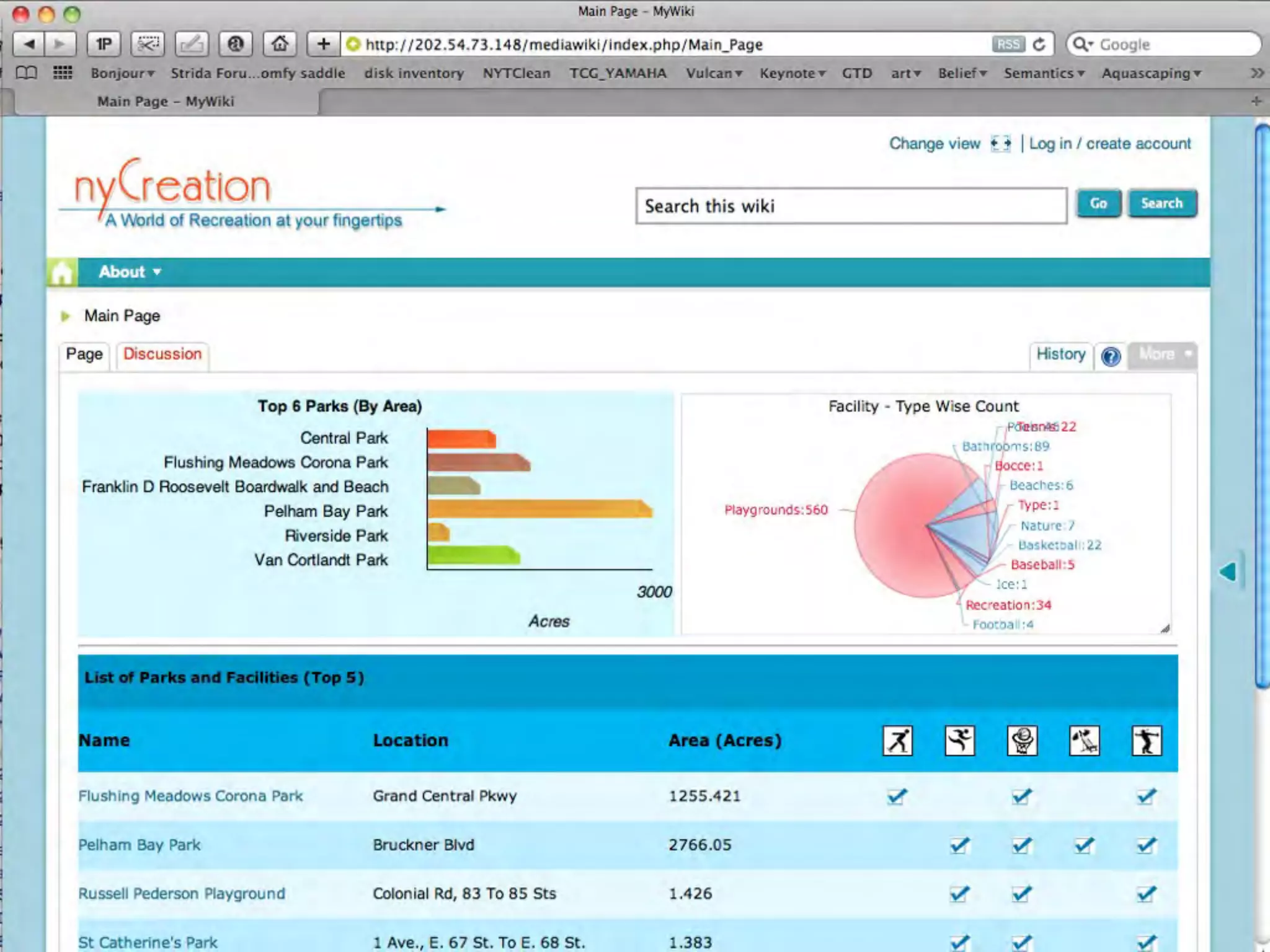
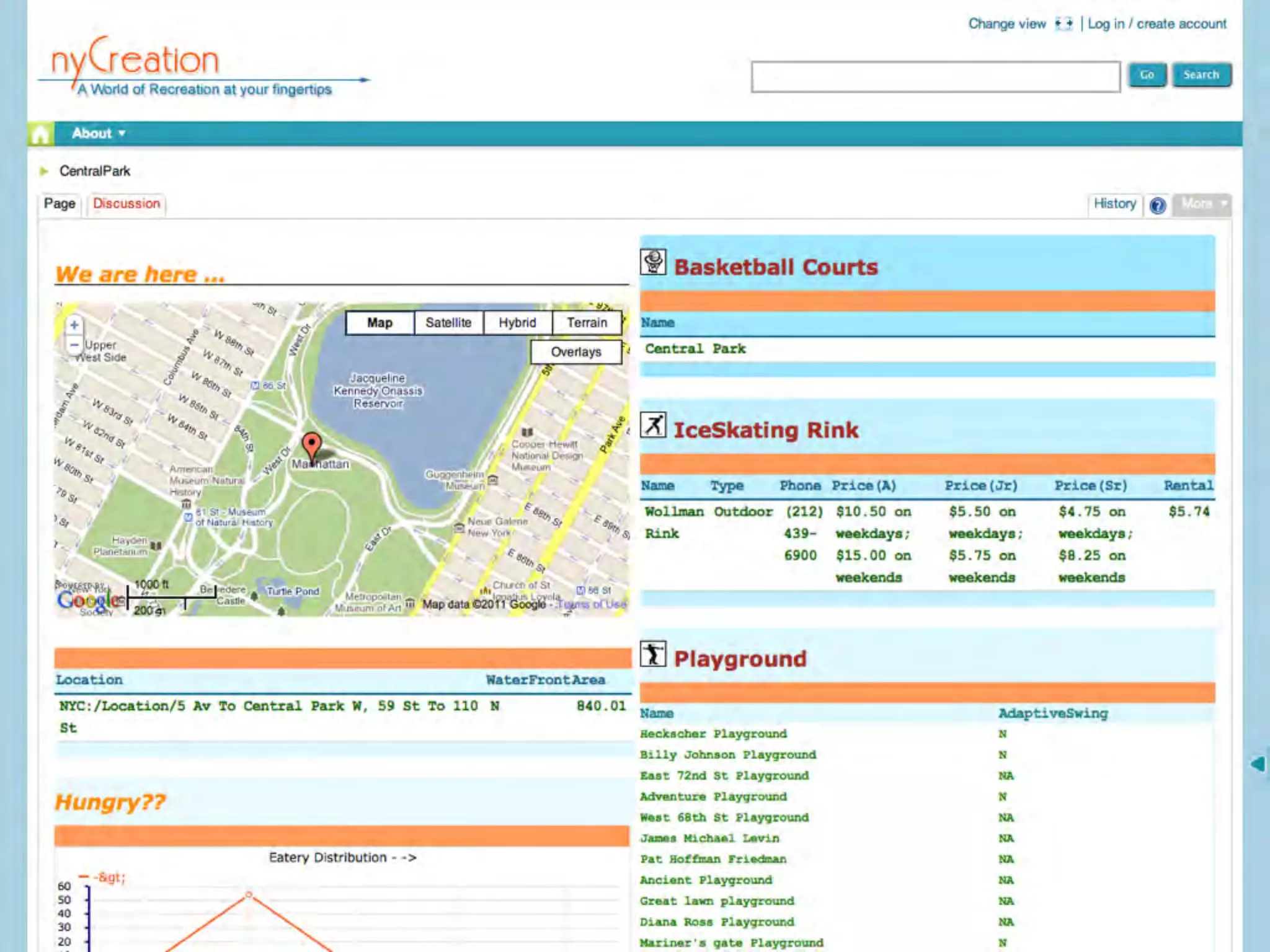
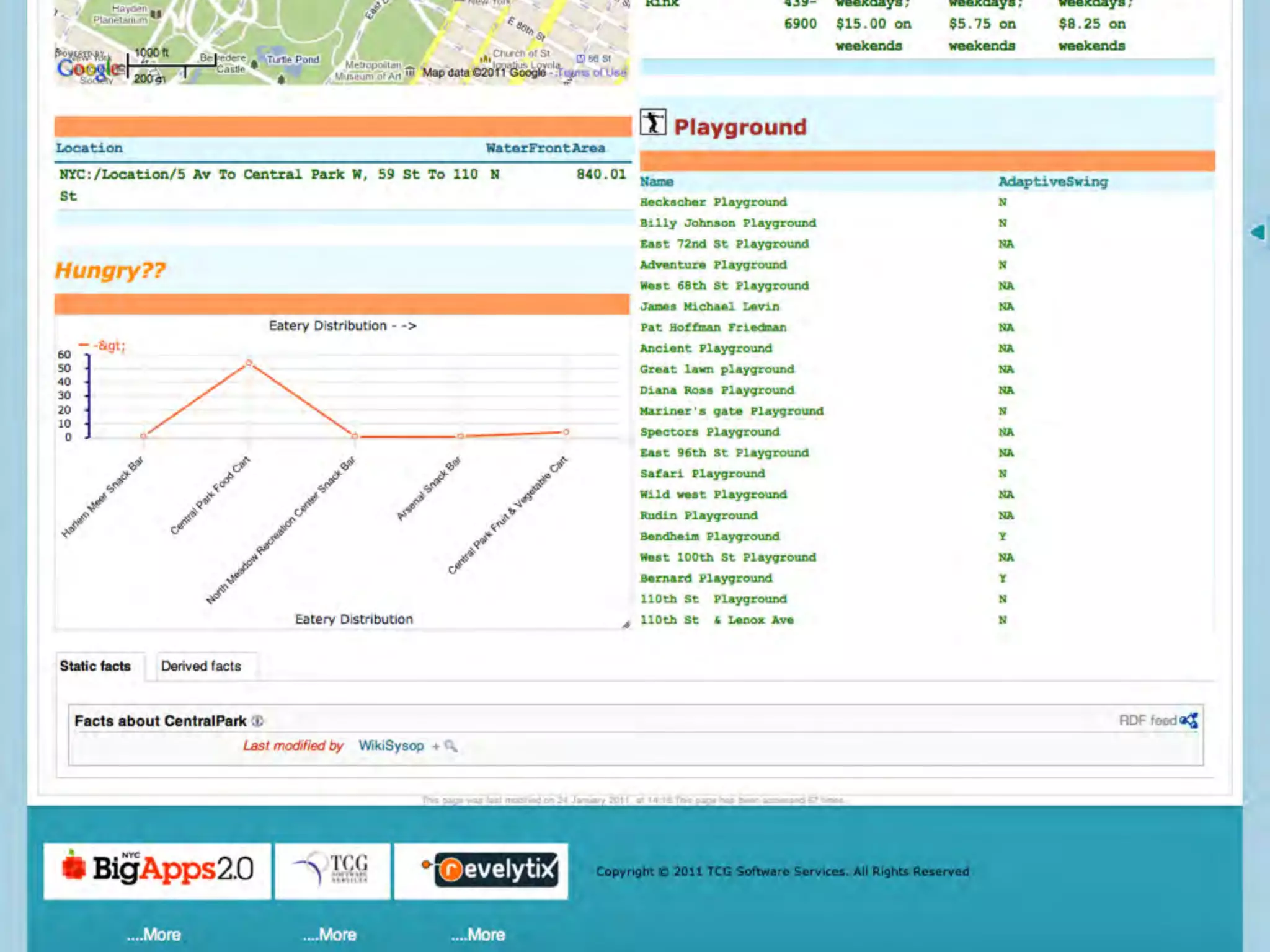
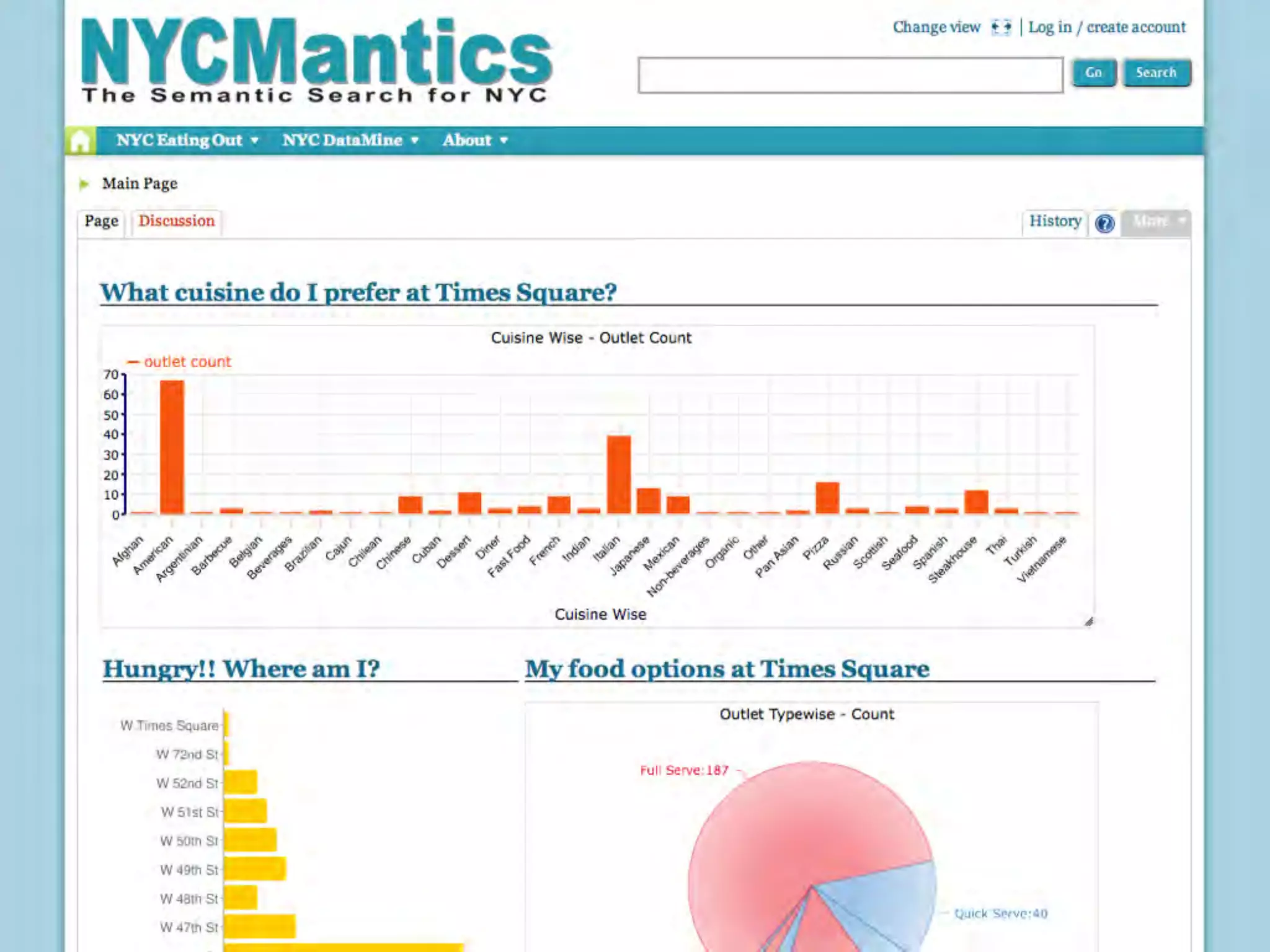
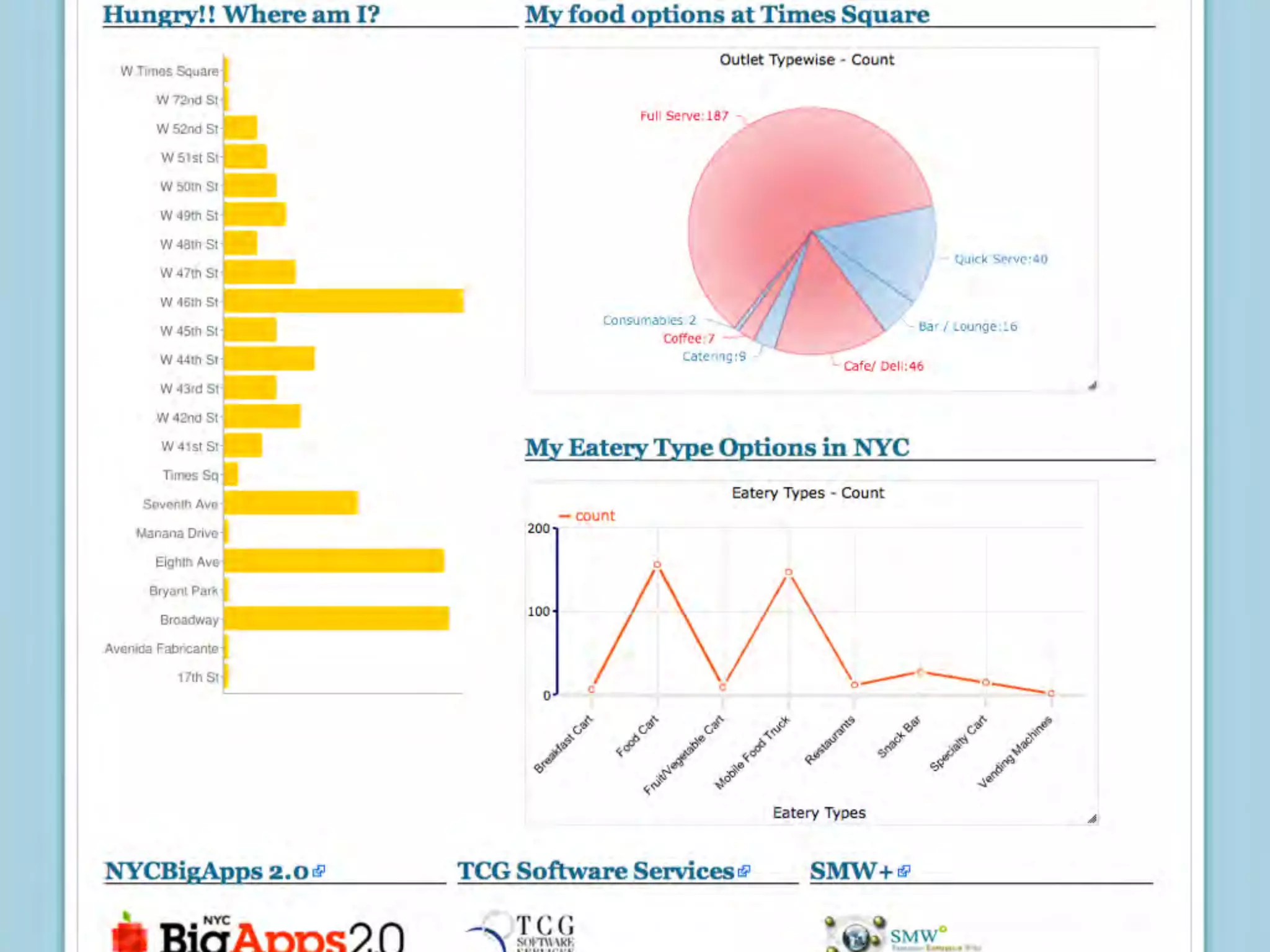
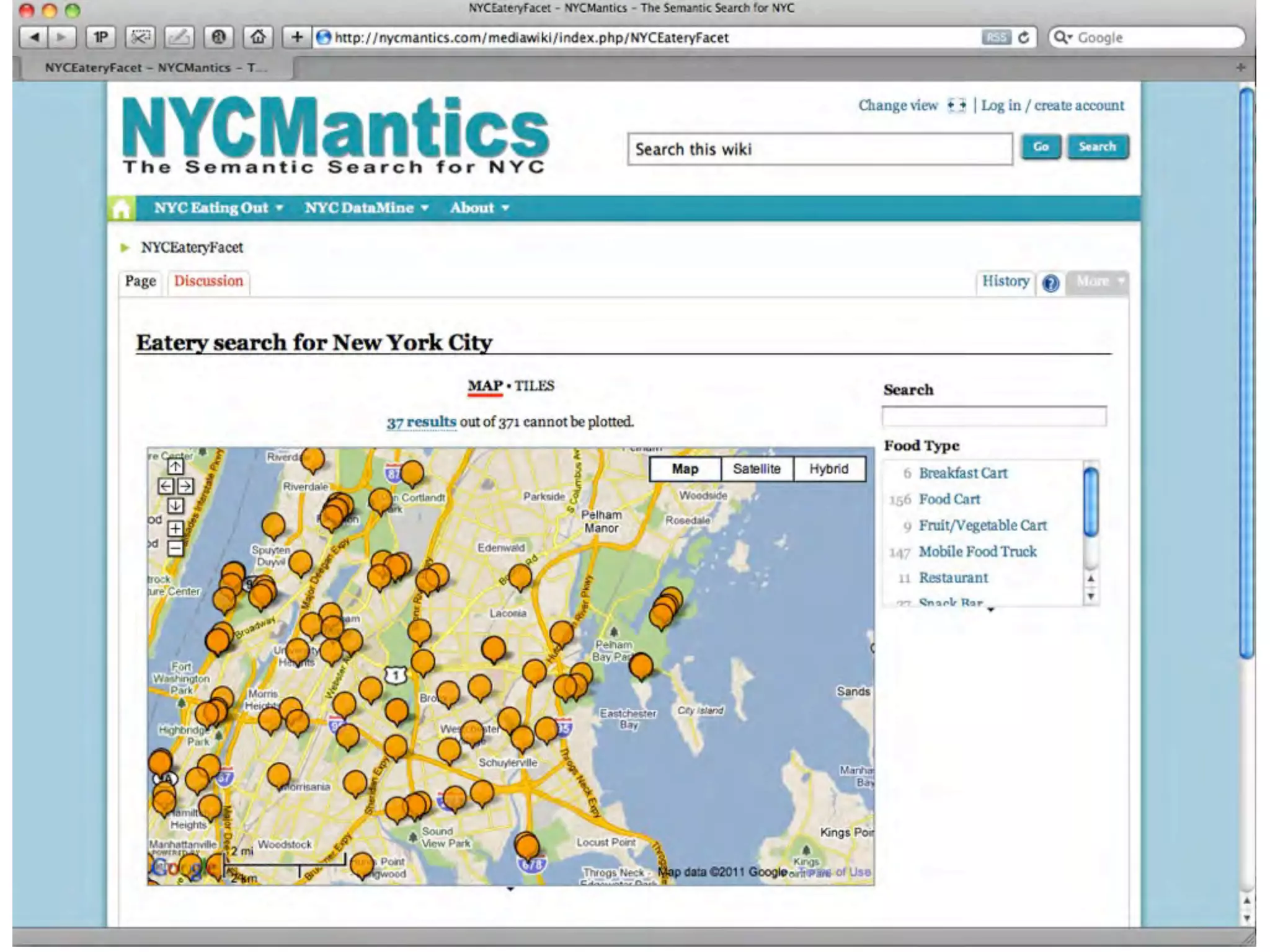
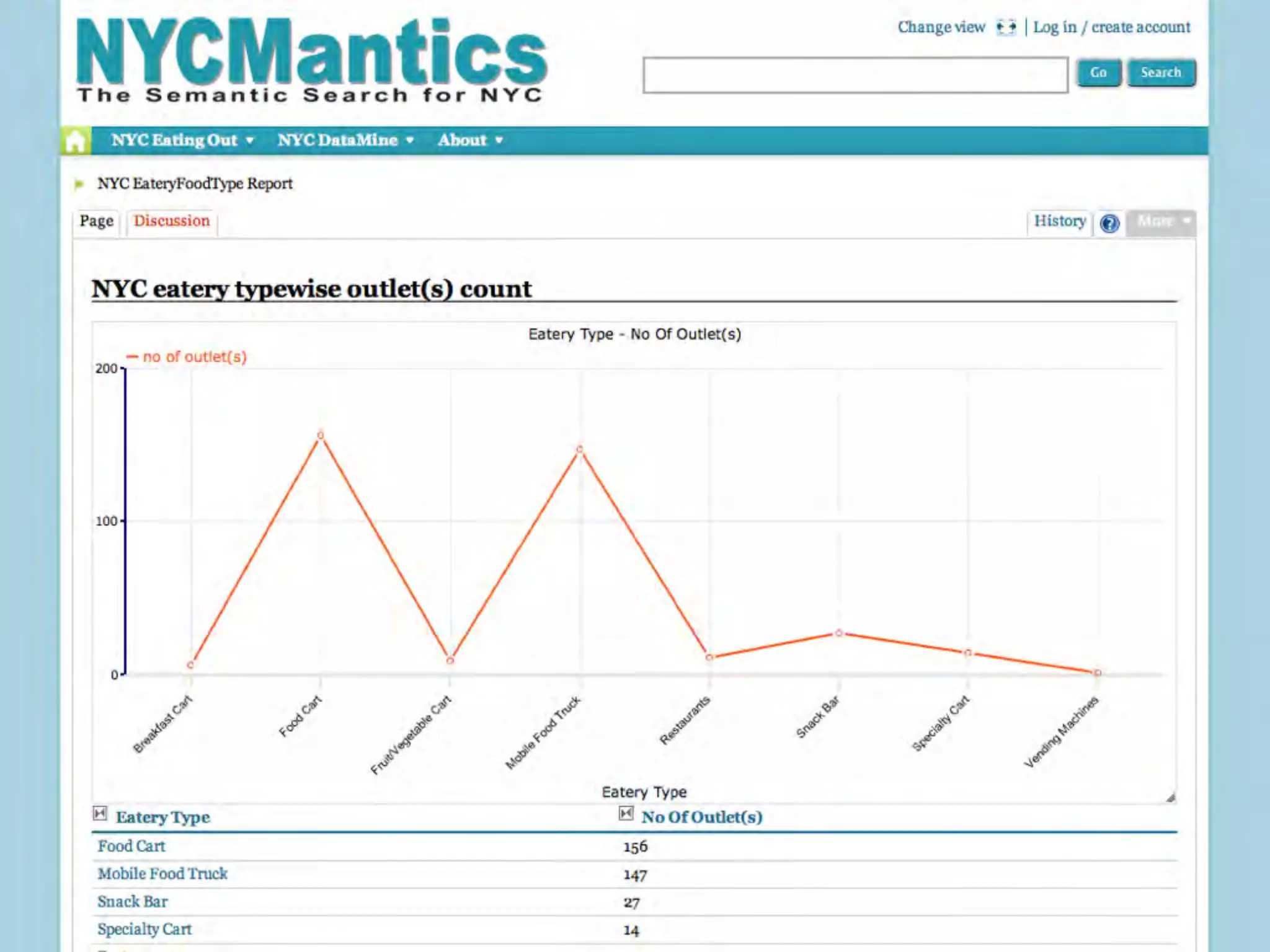
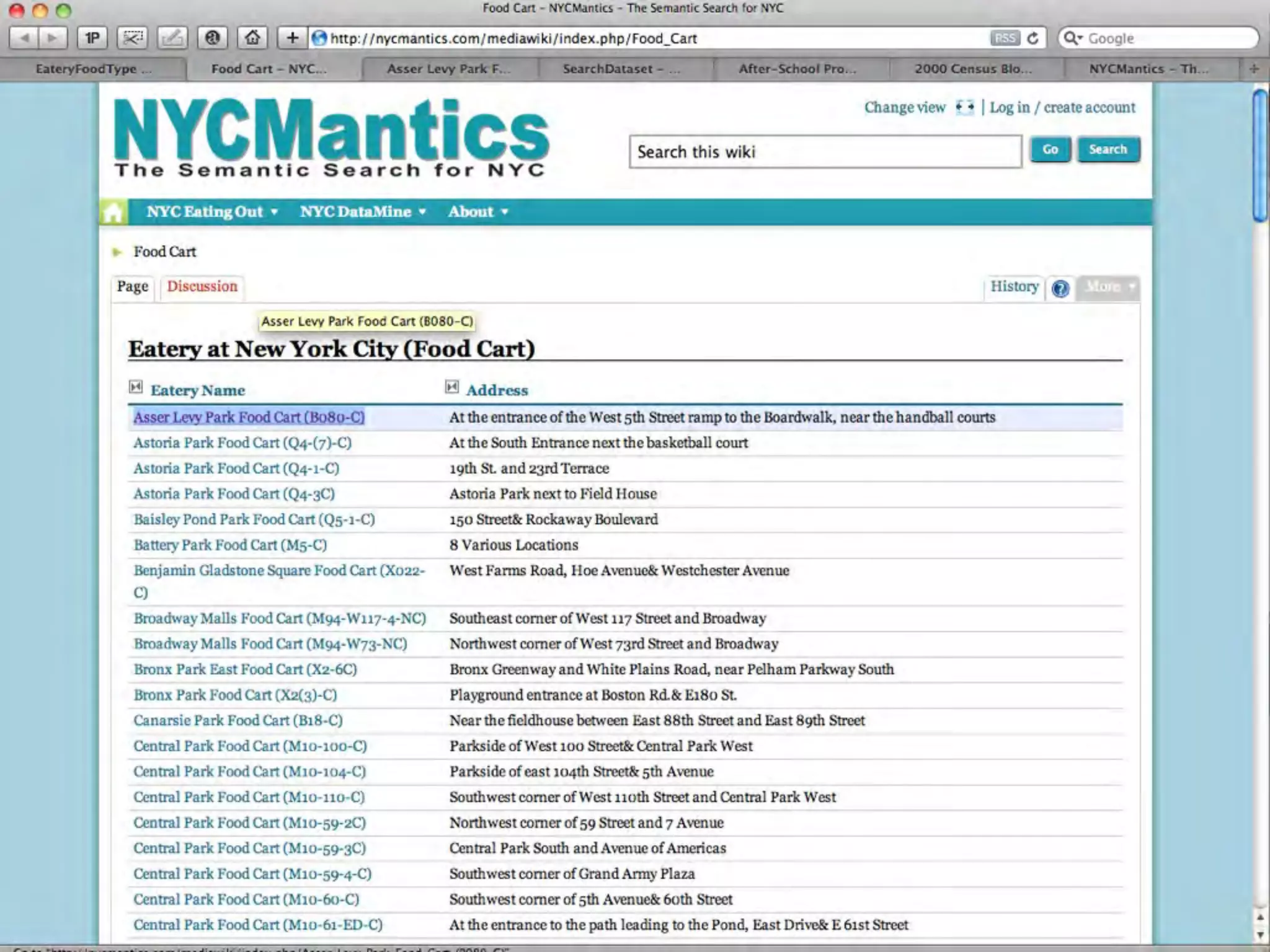
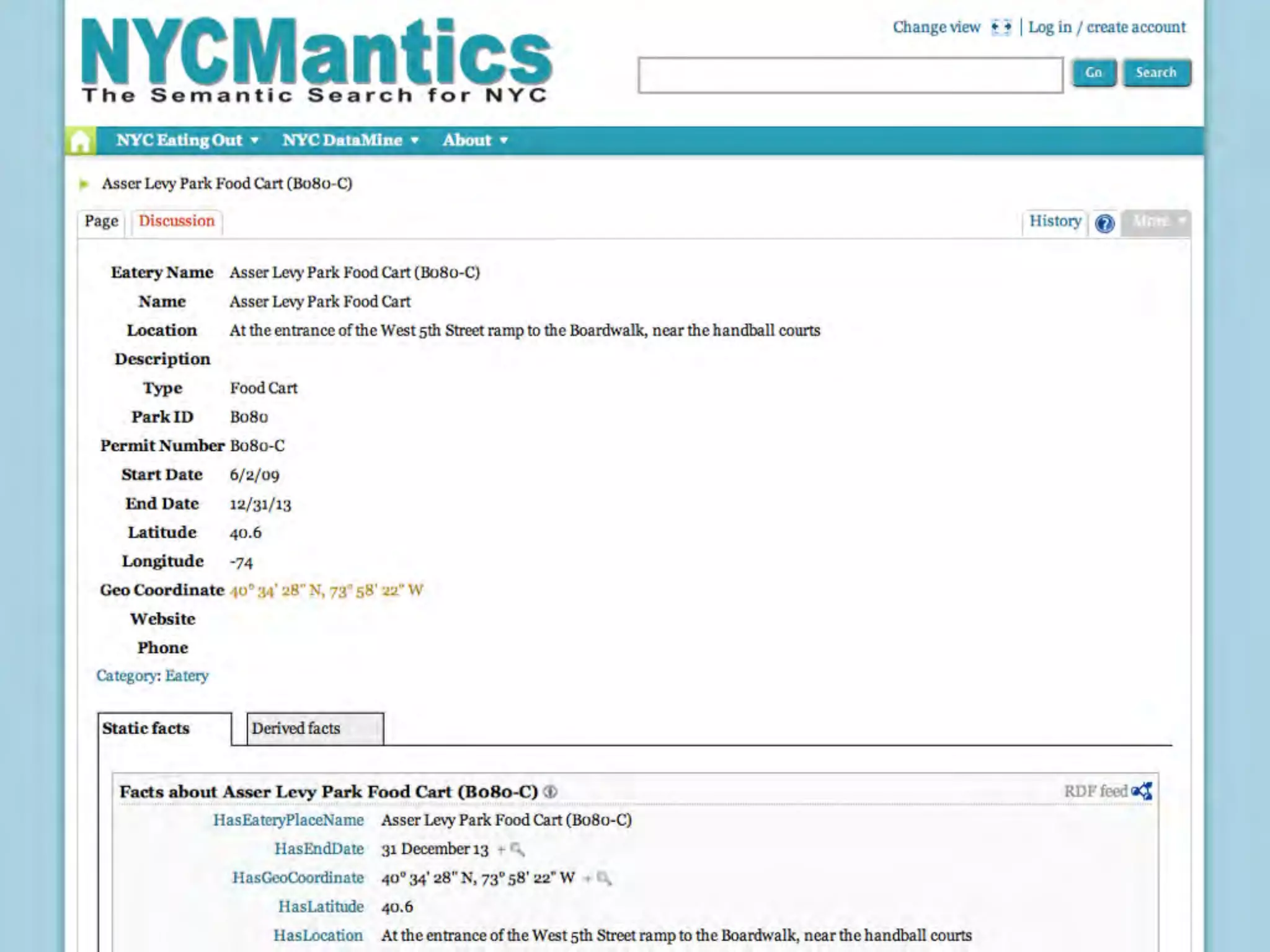
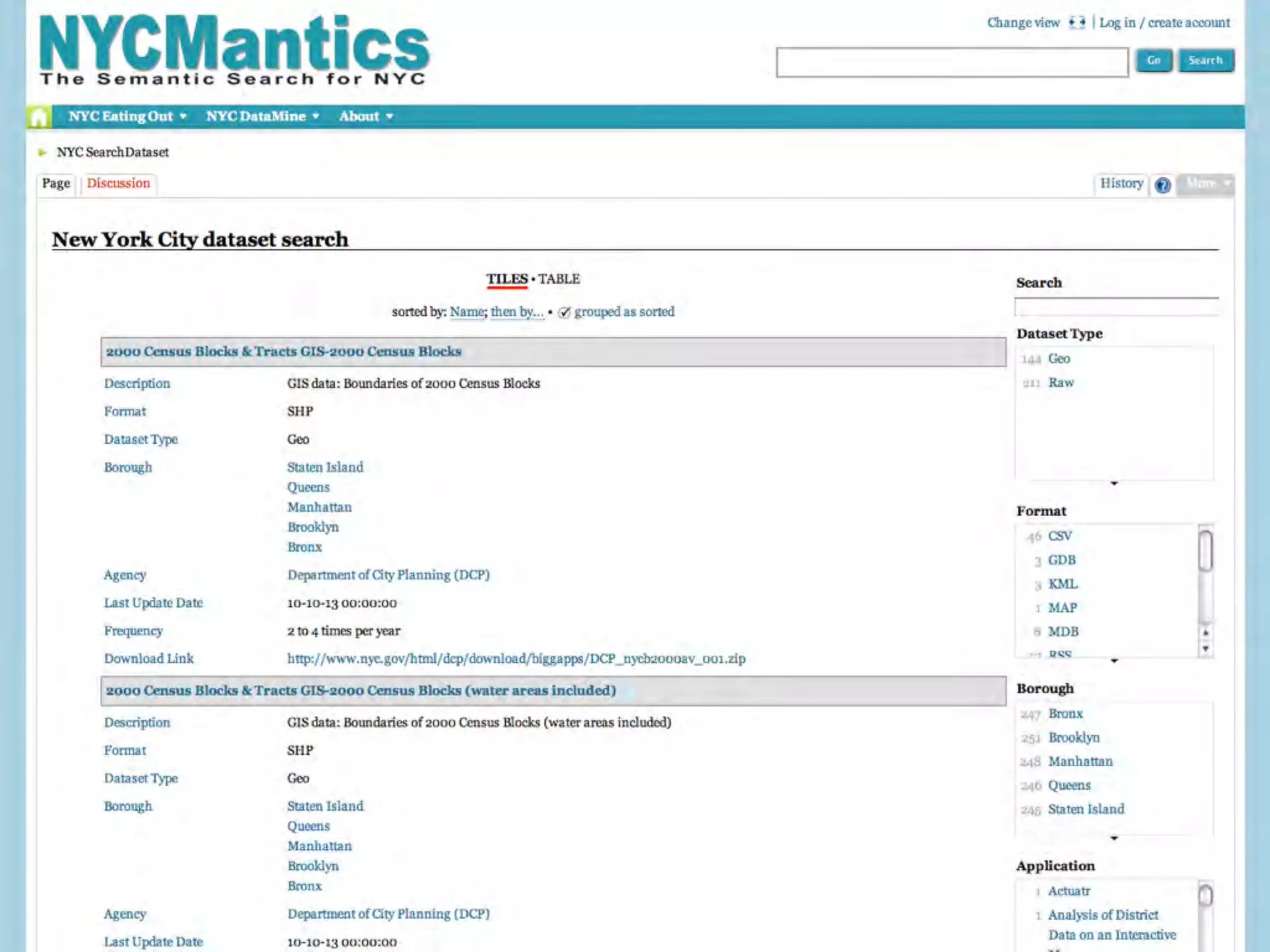
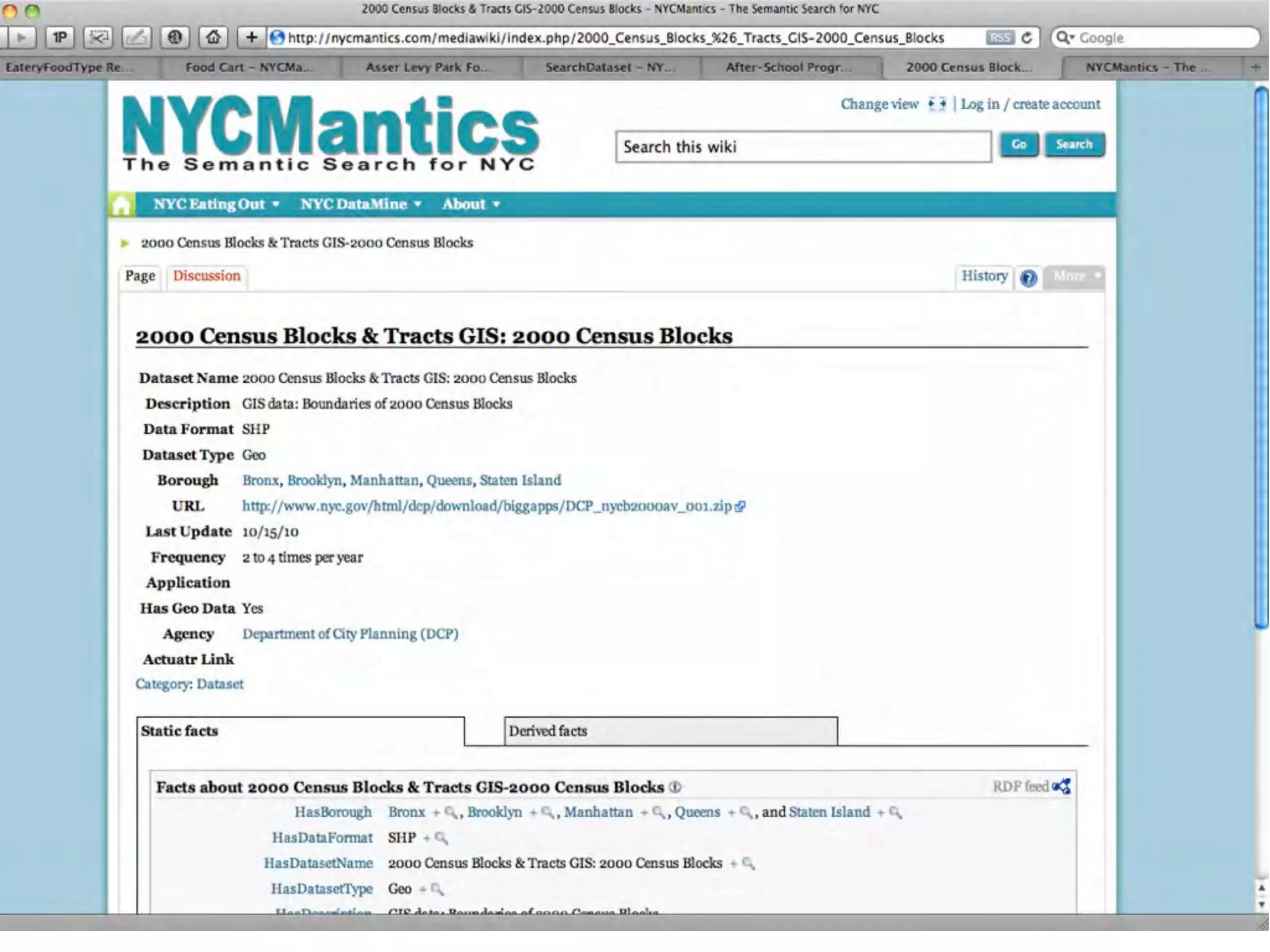

















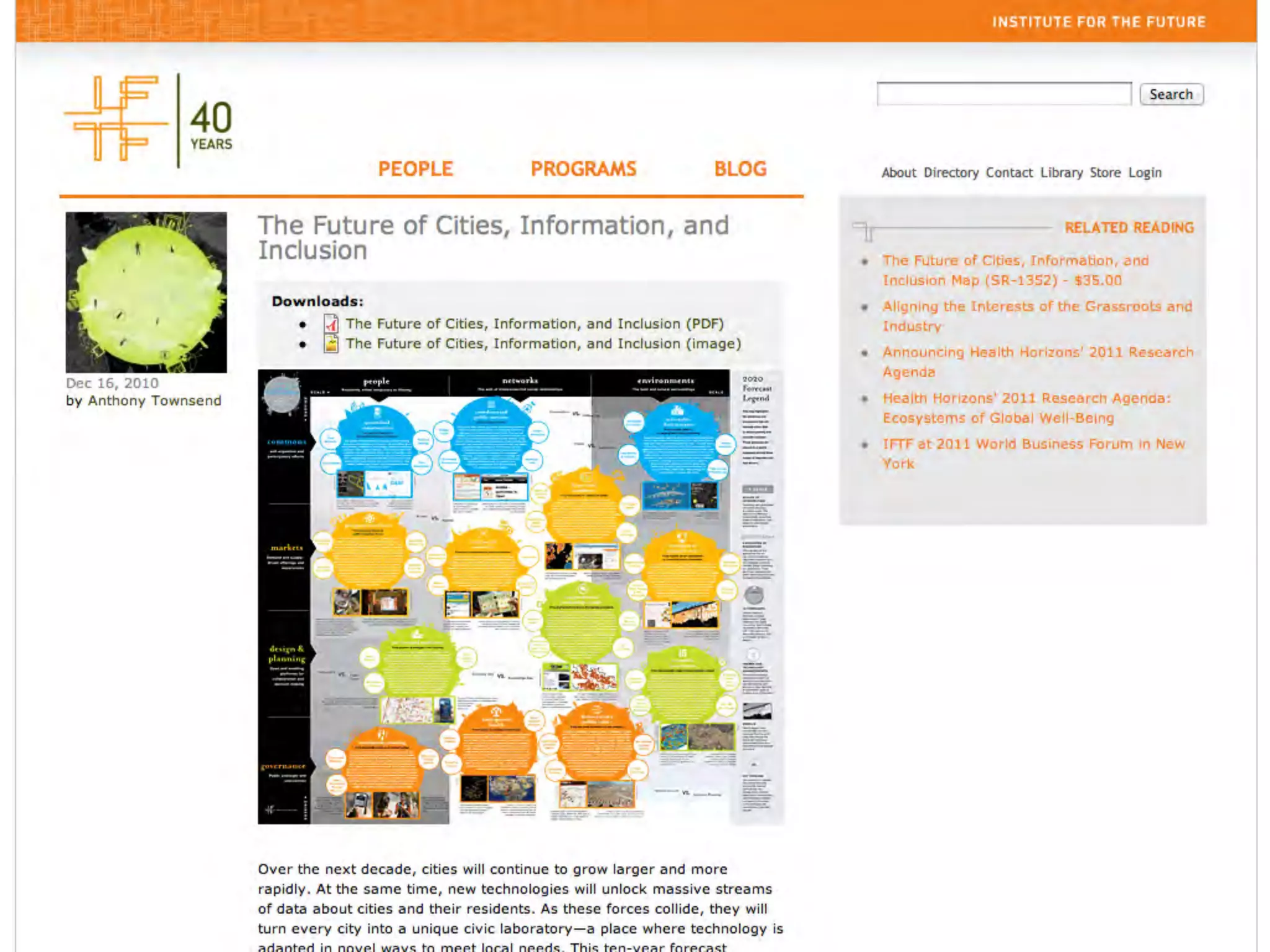


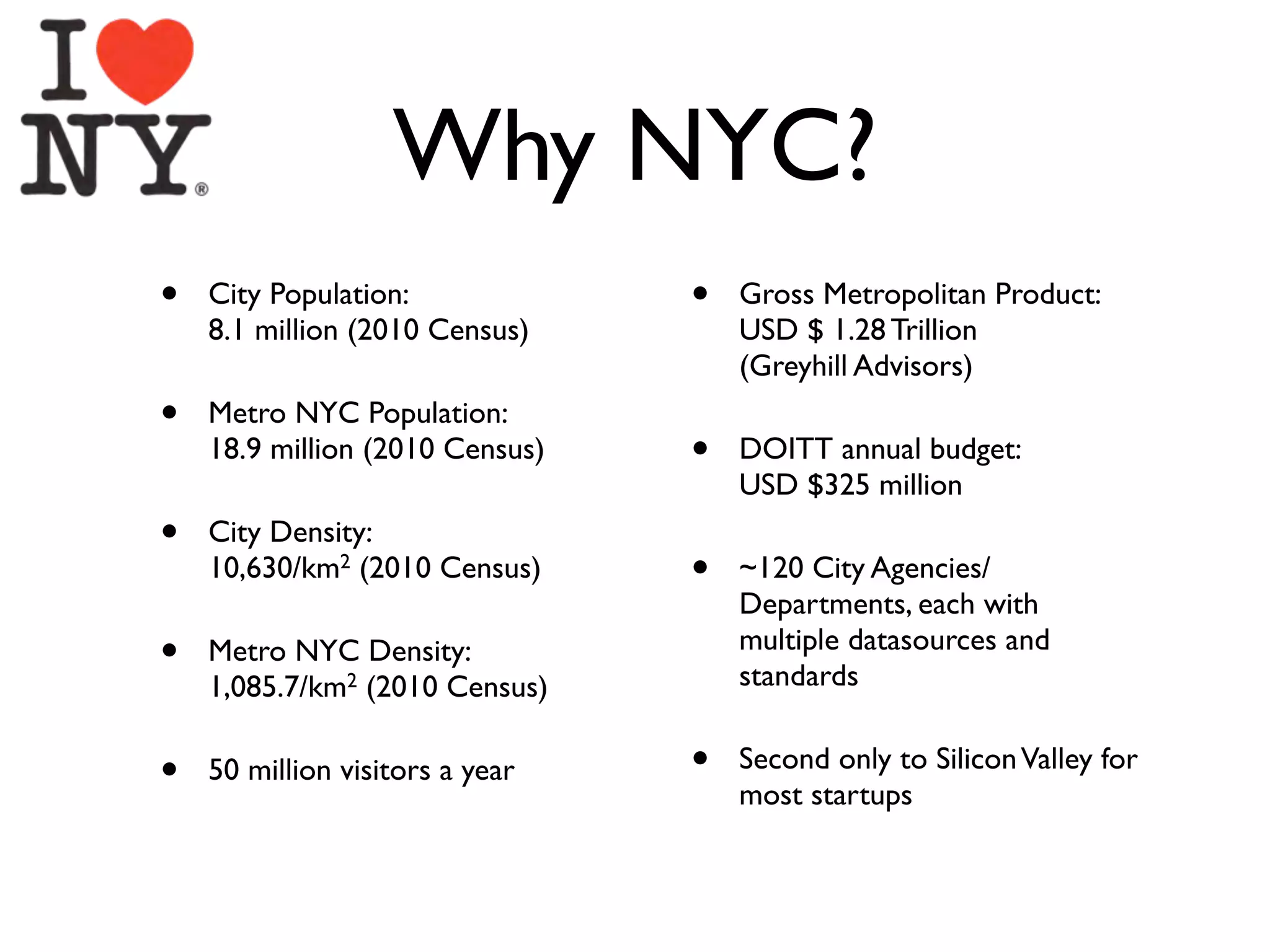









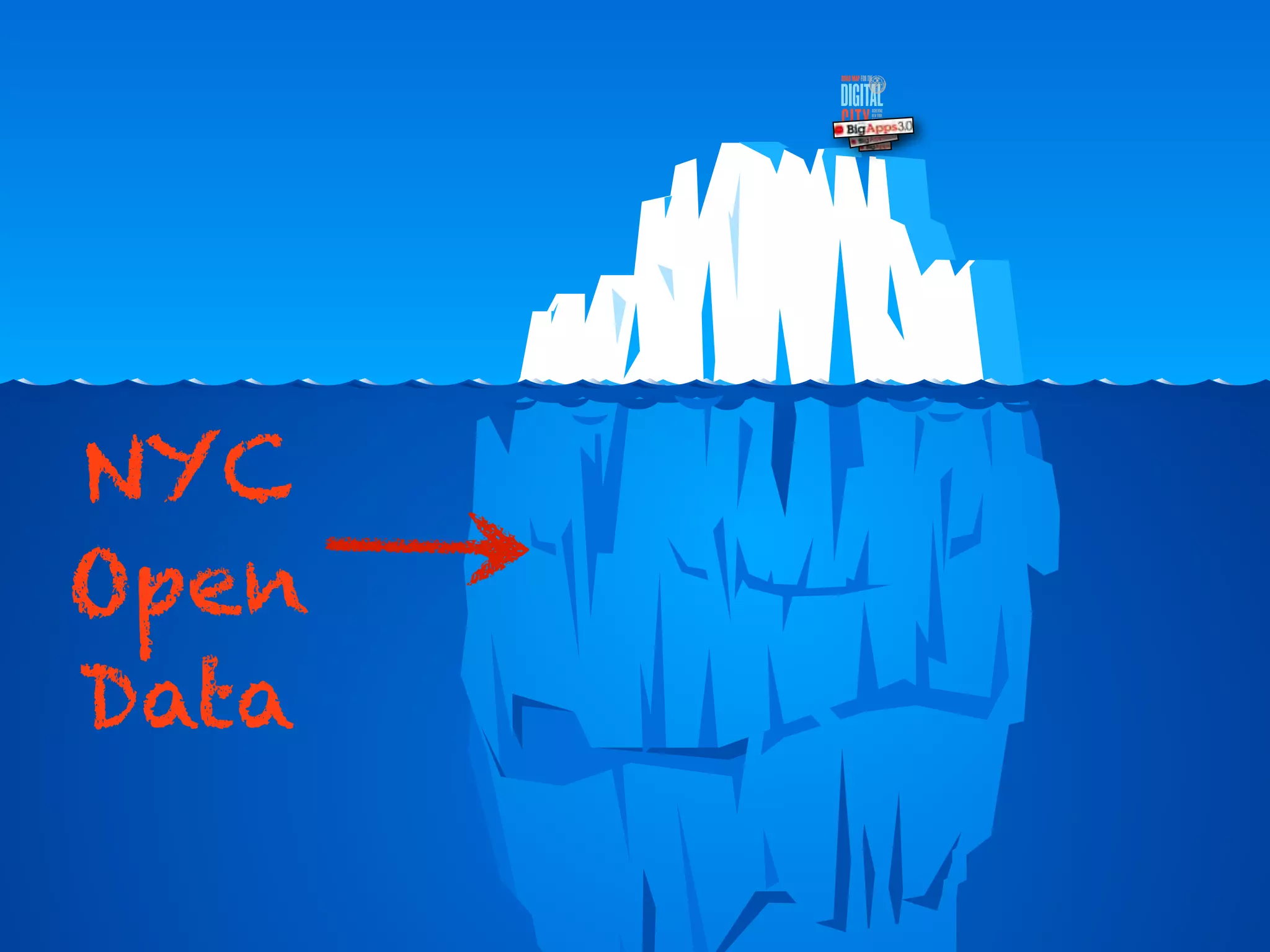







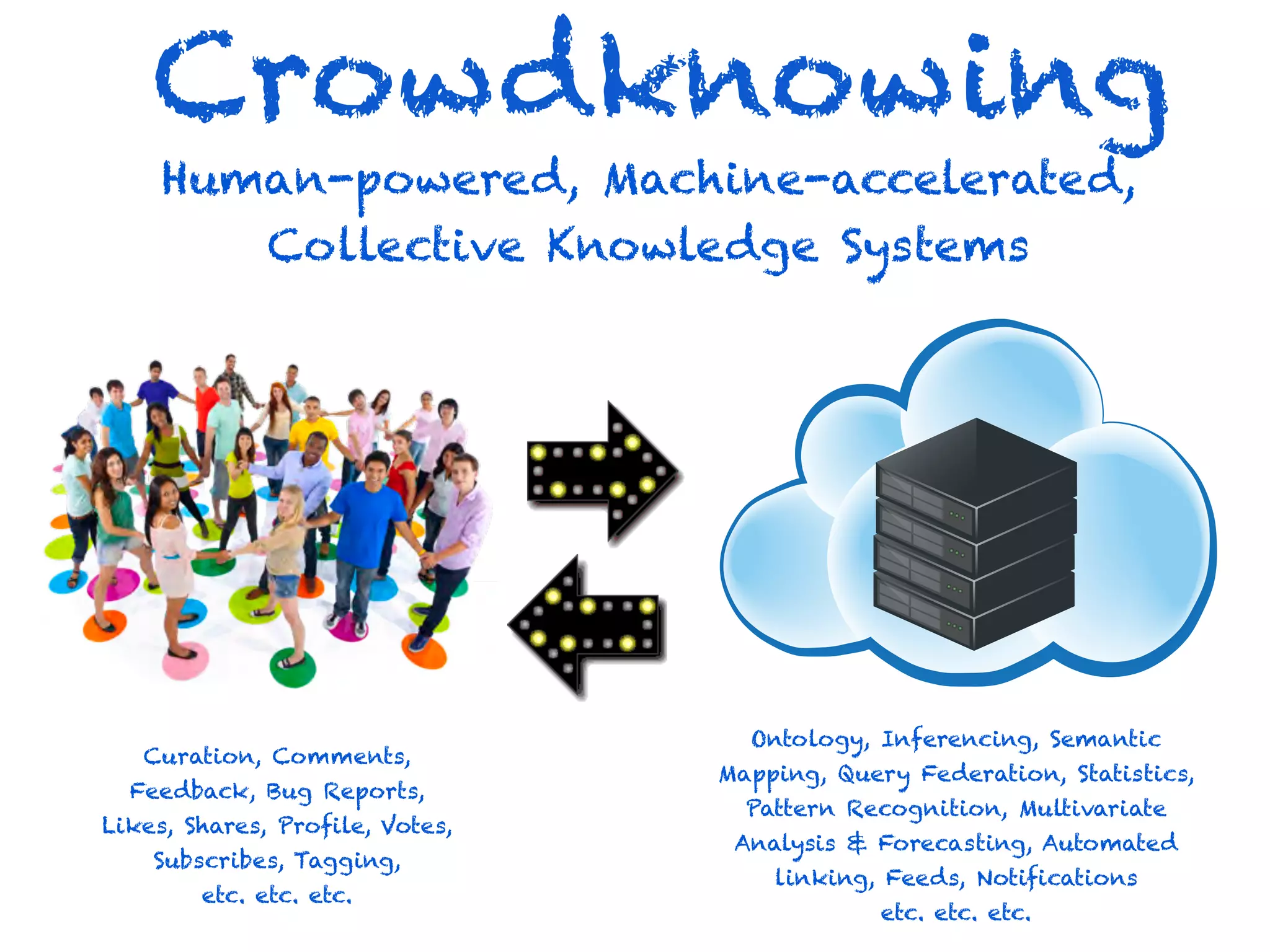


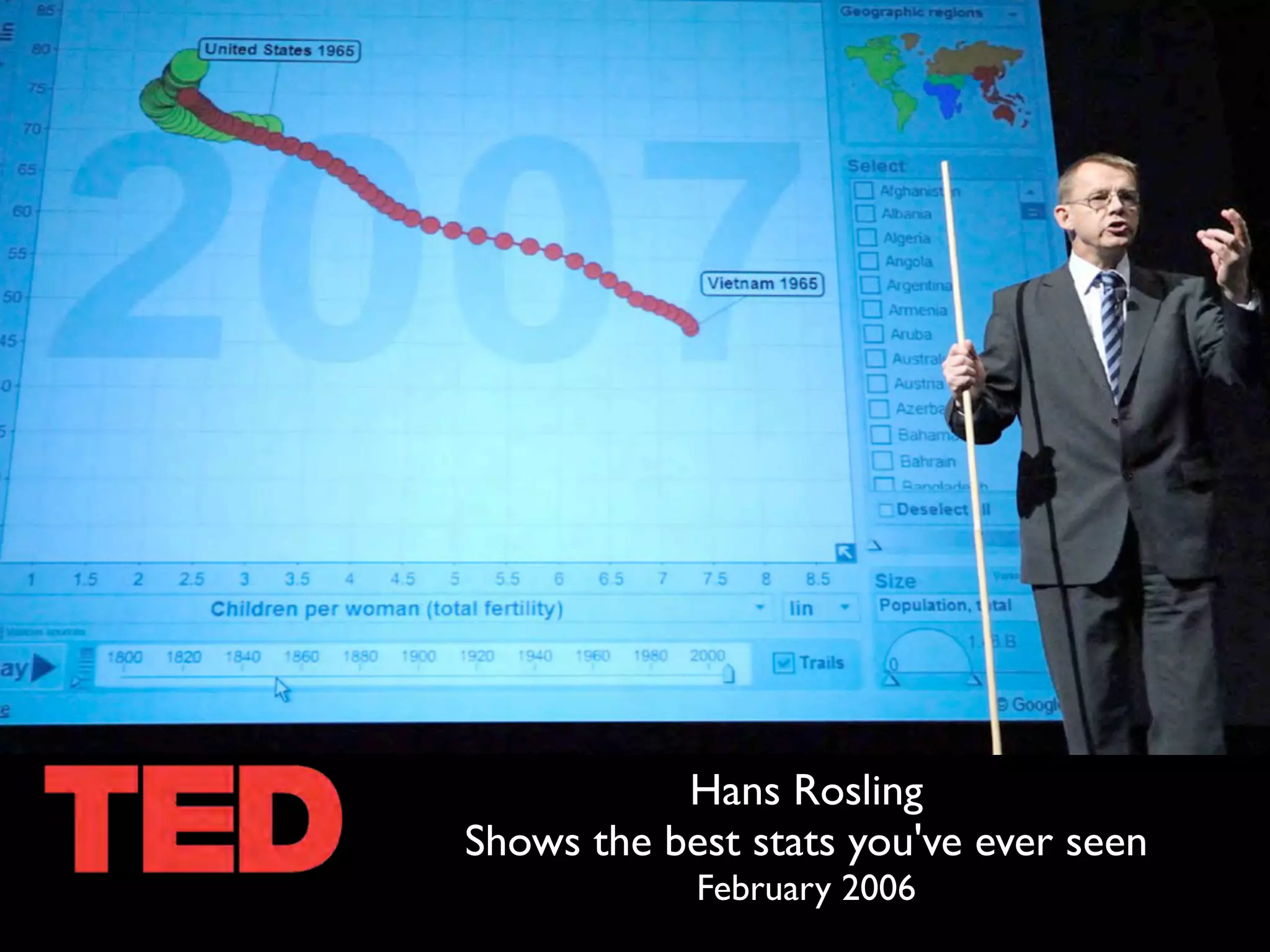

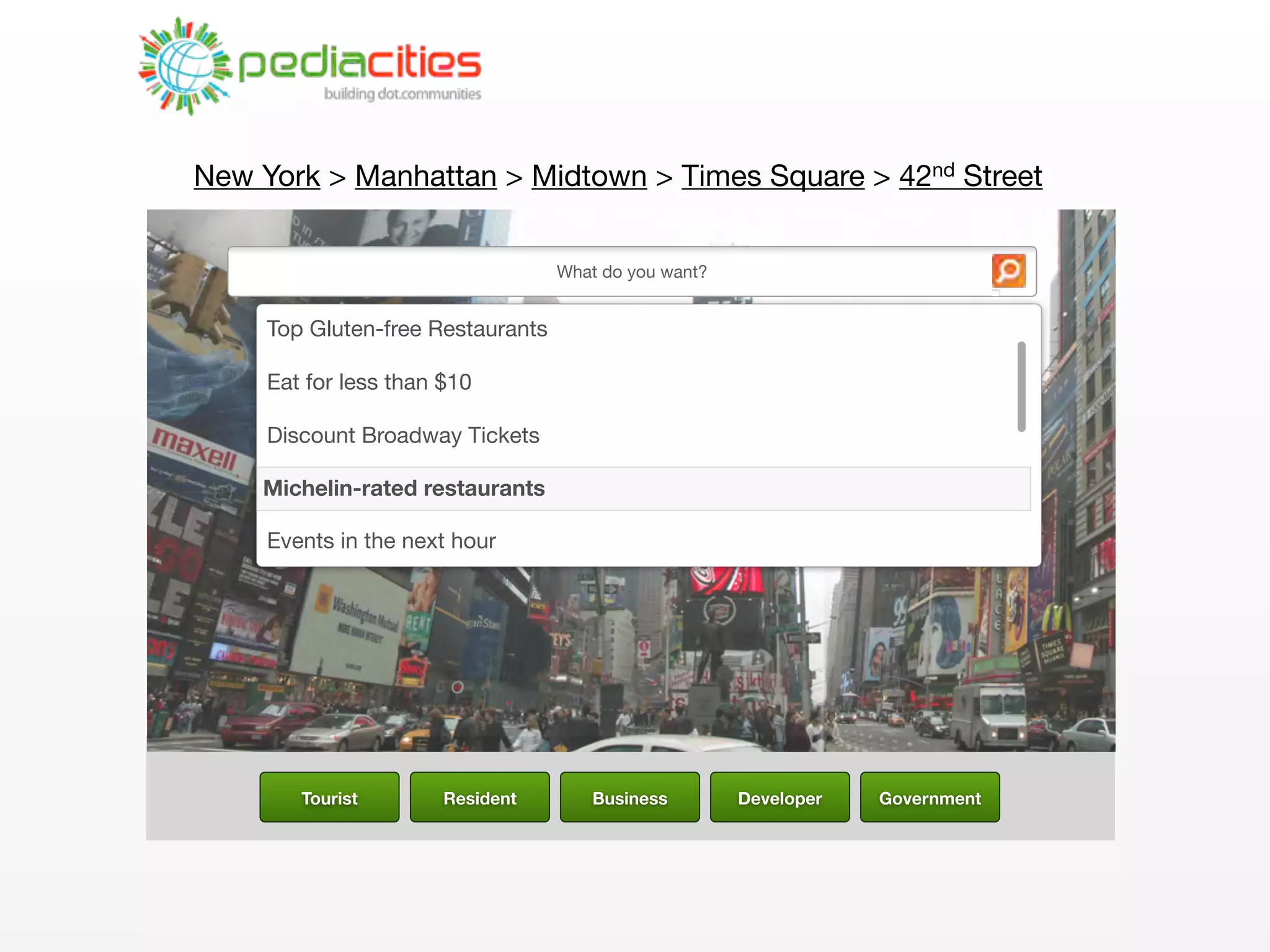






This document discusses smart cities, open data, and semantic mediawiki (SMW). It provides an overview of a conference on these topics held in Carlsbad, CA in 2012. It discusses the goals of using open data and SMW to stimulate app development, encourage innovation, and create new intellectual property. It also provides examples of how crowdsourcing and incentivized competitions can drive innovation.










































![[BDD 2025 - Full-Stack Development] Agentic AI Architecture: Redefining Syste...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-agenticaiarchitectureredefiningsystemcommunication-251124030838-e6c70cc2-thumbnail.jpg?width=640&height=640&fit=bounds)





![[BDD 2025 - Full-Stack Development] Digital Accessibility: Why Developers nee...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-digitalaccessibilitywhydevelopersneedtoknowandcarein2025-251127011019-0674441d-thumbnail.jpg?width=640&height=640&fit=bounds)







![[BDD 2025 - Mobile Development] Crafting Immersive UI with E2E and AGSL Shade...](https://cdn.slidesharecdn.com/ss_thumbnails/md-craftingimmersiveuiwithe2eandagslshaderveronicaputrianggraini-251124030840-0c677f44-thumbnail.jpg?width=640&height=640&fit=bounds)


