Česko-slovenský paralelný korpus určený pre preklad medzi blízkymi jazykmi
1.
Česko-slovenský paralelný korpusurčený
pre preklad medzi blízkymi jazykmi
Petra Galuščáková a Ondřej Bojar
{galuscakova,bojar}@ufal.mff.cuni.cz
Univerzita Karlova v Praze
Matematicko-fyzikální fakulta
Ústav formální a aplikované lingvistiky
2.
20. 10. 20112
Obsah prezentácie
● Vytvorenie korpusu – postup a použité nástroje
● Možné zdroje paralelného korpusu
● Aplikácia korpusu
3.
20. 10. 20113
Úvod
● Väčšie množstvo zdrojov pre češtinu
● Čeština a slovenčina sú veľmi príbuzné
● Čeština ako pivotný jazyk
● Česko-slovenský paralelný korpus
● Trénovanie automatického prekladu
● Vyhodnotenie automatického prekladu
CS
SK
EN PL
...
4.
20. 10. 20114
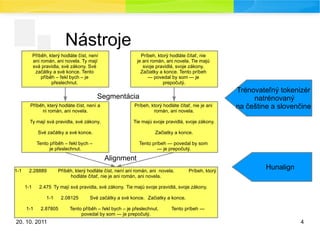
Nástroje
Příběh, který hodláte číst, není
ani román, ani novela. Ty mají
svá pravidla, své zákony. Své
začátky a své konce. Tento
příběh – řekl bych – je
přeslechnut.
Příběh, který hodláte číst, není a
ni román, ani novela.
Ty mají svá pravidla, své zákony.
Své začátky a své konce.
Tento příběh – řekl bych –
je přeslechnut.
1-1 2.28889 Příběh, který hodláte číst, není ani román, ani novela. Príbeh, ktorý
hodláte čítať, nie je ani román, ani novela.
1-1 2.475 Ty mají svá pravidla, své zákony. Tie majú svoje pravidlá, svoje zákony.
1-1 2.08125 Své začátky a své konce. Začiatky a konce.
1-1 2.87805 Tento příběh – řekl bych – je přeslechnut. Tento príbeh —
povedal by som — je prepočutý.
Segmentácia
Alignment
Trénovateľný tokenizér
natrénovaný
na češtine a slovenčine
Hunalign
Príbeh, ktorý hodláte čítať, nie
je ani román, ani novela. Tie majú
svoje pravidlá, svoje zákony.
Začiatky a konce. Tento príbeh
— povedal by som — je
prepočutý.
Príbeh, ktorý hodláte čítať, nie je ani
román, ani novela.
Tie majú svoje pravidlá, svoje zákony.
Začiatky a konce.
Tento príbeh — povedal by som
— je prepočutý.
5.
20. 10. 20115
Problémy
● Segmentácia je podstatná pri alignmente
● Problém v prípade, že česká segmentácia pracuje inak ako
slovenská
Alignment Česká veta Slovenská veta
2 - 1
"Pryč ode mne, vy zloto!
<s> Co vám udělaly ty
kačátka?
„Preč odo mňa, vy lotri! čo
vám urobili tie kačičky?
2 - 1
— <s> Viktor nevnímal
hovor a zmatek ve vagónu.
Viktor nevnímal vravu a
zmätok vo vagóne.
1 - 2 Stáří 23 let. Zoolingvistka.
Vek dvadsaťtri rokov. <s>
Zoolingvistka.
1 - 2 II/ MODLITBA II <s> MODLITBA
<s> označuje rozdelenie na vety
6.
20. 10. 20116
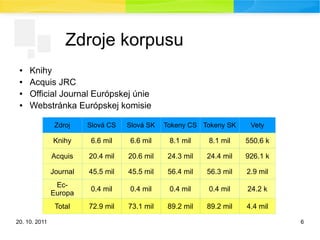
Zdroje korpusu
● Knihy
● Acquis JRC
● Official Journal Európskej únie
● Webstránka Európskej komisie
Zdroj Slová CS Slová SK Tokeny CS Tokeny SK Vety
Knihy 6.6 mil 6.6 mil 8.1 mil 8.1 mil 550.6 k
Acquis 20.4 mil 20.6 mil 24.3 mil 24.4 mil 926.1 k
Journal 45.5 mil 45.5 mil 56.4 mil 56.3 mil 2.9 mil
Ec-
Europa
0.4 mil 0.4 mil 0.4 mil 0.4 mil 24.2 k
Total 72.9 mil 73.1 mil 89.2 mil 89.2 mil 4.4 mil
7.
20. 10. 20117
Zdroje korpusu I - knihy
● Pripravený SAV
● Veľmi dobrý zdroj dát pre MT, problematický môže byť
alignment (málo štrukturované texty)
● 118 kníh (cs->sk, sk->cs a en->cs,sk), vlastný alignment
● Problém získať takýto zdroj, limitované použitie
8.
20. 10. 20118
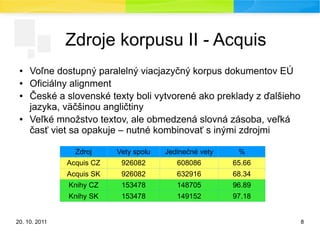
Zdroje korpusu II - Acquis
● Voľne dostupný paralelný viacjazyčný korpus dokumentov EÚ
● Oficiálny alignment
● České a slovenské texty boli vytvorené ako preklady z ďalšieho
jazyka, väčšinou angličtiny
● Veľké množstvo textov, ale obmedzená slovná zásoba, veľká
časť viet sa opakuje – nutné kombinovať s inými zdrojmi
Zdroj Vety spolu Jedinečné vety %
Acquis CZ 926082 608086 65.66
Acquis SK 926082 632916 68.34
Knihy CZ 153478 148705 96.89
Knihy SK 153478 149152 97.18
9.
20. 10. 20119
Zdroje korpusu III – Official
Journal
● Opäť dokumenty EU, v 23 jazykoch
● Podobné dáta ako Acquis, podobné problémy
● Oficiálny alignment aj na úrovni viet
10.
20. 10. 201110
Zdroje korpusu IV – Stránka
European Commision
● Rôzne jazykové varianty tej istej stránky, ktoré sa líšia príponou
v URL
● Slovenské a české texty vznikli najčastejšie ako preklad z
angličtiny
● Veľa nepreložených odstavcov v českých a slovenských
stránkach
● Na sťahovanie stránok bol implementovaný špeciálny web
crawler
● Stiahnuté stránky boli ďalej prečistené od html kódu a
deduplikované
20. 10. 201112
Automatický preklad
● Acquis a knihy boli použité pri trénovaní, ladení a testovaní
nástroja na automatický preklad Moses
● Celkom 6 prípadov (Acquis/Acquis, Acquis/Knihy, Knihy/Acquis,
Knihy/Knihy, Acquis+Knihy/Acquis, Acquis+Knihy/Knihy)
● Testovacia sada – 3860 náhodne vybraných riadkov z kníh
13.
20. 10. 201113
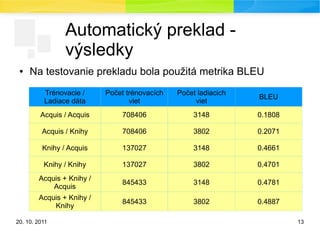
Automatický preklad -
výsledky
● Na testovanie prekladu bola použitá metrika BLEU
Trénovacie /
Ladiace dáta
Počet trénovacích
viet
Počet ladiacich
viet
BLEU
Acquis / Acquis 708406 3148 0.1808
Acquis / Knihy 708406 3802 0.2071
Knihy / Acquis 137027 3148 0.4661
Knihy / Knihy 137027 3802 0.4701
Acquis + Knihy /
Acquis
845433 3148 0.4781
Acquis + Knihy /
Knihy
845433 3802 0.4887
14.
20. 10. 201114
Automatický preklad – ukážky
výstupu
Originál
"Tak vidějí, vašnosti, dali jsme jim tu radu lacino," řekli pes s
kočičkou, "zrovna jsme si něco takového na zub přáli.
Acquis/Acquis
"tak vidějí, vašnosti, dali jsme im tu radu lacino," řekli pes s kočičkou,
"zrovna jsme si něco takéhoto na zub přáli.
Acquis/Knihy
"tak vidějí, vašnosti, dali jsme im tu radu lacino," řekli predvedenie
identifikácie psa s kočičkou, "zrovna si jsme inak takéhoto na zub
přáli.
Knihy/Acquis
„ nuž vidíte, pán veľkomožný, dali sme im tú radu lacno, “ povedali
pes s mačičkou, „ akurát sme si niečo takého na zub želali.
Knihy/Knihy
„ nuž vidíte, pán veľkomožný, dali sme im tú radu lacno, “ povedali
pes s mačičkou, „ práve sme si také čosi na zub želali.
Acquis+Knihy
/Acquis
„nuž vidíte, pán veľkomožný, dali sme im tú radu lacno,“ povedali pes
a mačička, „akurát sme si také čosi na zub želali.
Acquis+Knihy
/Knihy
„nuž vidíte, pán veľkomožný, dali sme im tú radu lacno,“ povedali pes
s mačičkou, „práve sme si také čosi na zub želali.
15.
20. 10. 201115
Automatický preklad –
diskusia
● Pri natrénovaní na knihách je dosiahnuté skóre podstatne
vyššie ako pri natrénovaní na Acquise, hoci veľkosť trénovacích
dát je 5x nižšia
● Slovná zásoba z testovacej sady vybranej z kníh sa môže
nachádzať v trénovacích dátach
● Knihy vznikli na rozdiel od Acquisu vo väčšine ako preklad
cs->sk a sk->cs
● Knihy zlepšia výsledky aj v prípade, že sa použijú ako ladiaca
množina
● Pri spojení kníh a Acquisu nedochádza k výraznému zlepšeniu
výsledkov, ktoré boli dosiahnuté pri tréningu iba na knihách
16.
20. 10. 201116
Záver
● Bol vytvorený česko-slovenský paralelný
korpus z niekoľkých zdrojov
● Korpus bol využitý pri automatickom preklade
● Pri preklade hrá dôležitú úlohu to, z akého
zdroja trénovacie dáta pochádzajú
● Stačí menšie množstvo dát, ktoré sú
rôznorodejšie
17.
20. 10. 201117
Odkazy
● Acquis JRC
http://optima.jrc.it/Acquis
● Stránka Európskej komisie
http://ec.europa.eu
● Official Journal
http://eurlex.europa.eu/JOIndex.do
● Trénovateľný tokenizér
Klyueva N., Bojar O. (2008). UMC 0.1: Czech-Russian-English Multilingual Corpus. In
Proceedings of International Conference Corpus Linguistics, pages 188–195.
● Hunalign
http://mokk.bme.hu/resources/hunalign
● Moses
http://www.statmt.org/moses