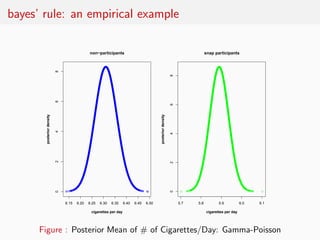
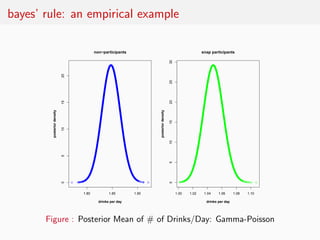
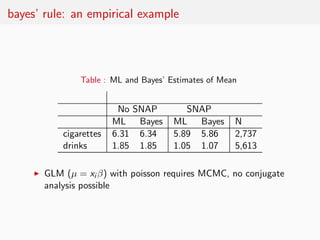
This document summarizes key points from Nate Silver's book "The Signal and the Noise" regarding predictive modeling and forecasting. It discusses how Bayesian reasoning using priors can improve predictions by explicitly incorporating uncertainty. Examples are given where rating agencies, economists, and pundits made poor predictions by failing to account for factors outside their models. The document advocates applying Bayesian methods to statistical models to estimate parameters and improve predictions.