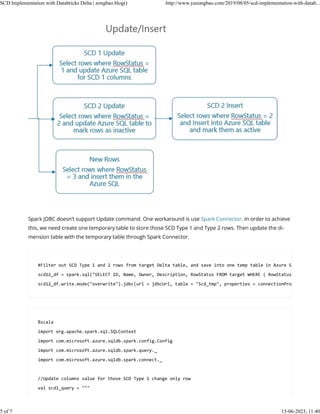
The document describes implementing slowly changing dimensions (SCD) with Databricks Delta. It loads source and target data into Delta tables, performs a MERGE to update SCD type 1 and 2 rows in the target table, filters the updated rows into a temporary table, and then runs queries to update the rows in the final database table to reflect the SCD changes.