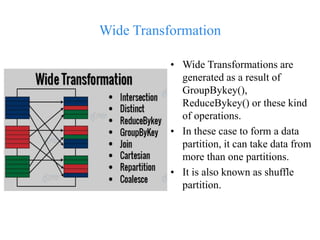
This document discusses RDD transformations in Spark. It defines RDD as a resilient distributed dataset, which are fault-tolerant collections of elements that can be operated on in parallel. There are two types of RDD operations: transformations and actions. Transformations are lazy operations that take an RDD as input and return one or more RDDs as output, without changing the original RDD. Transformations are either narrow, operating only on a single partition, or wide, taking data from multiple partitions and shuffling the data.