Downloaded 2,426 times



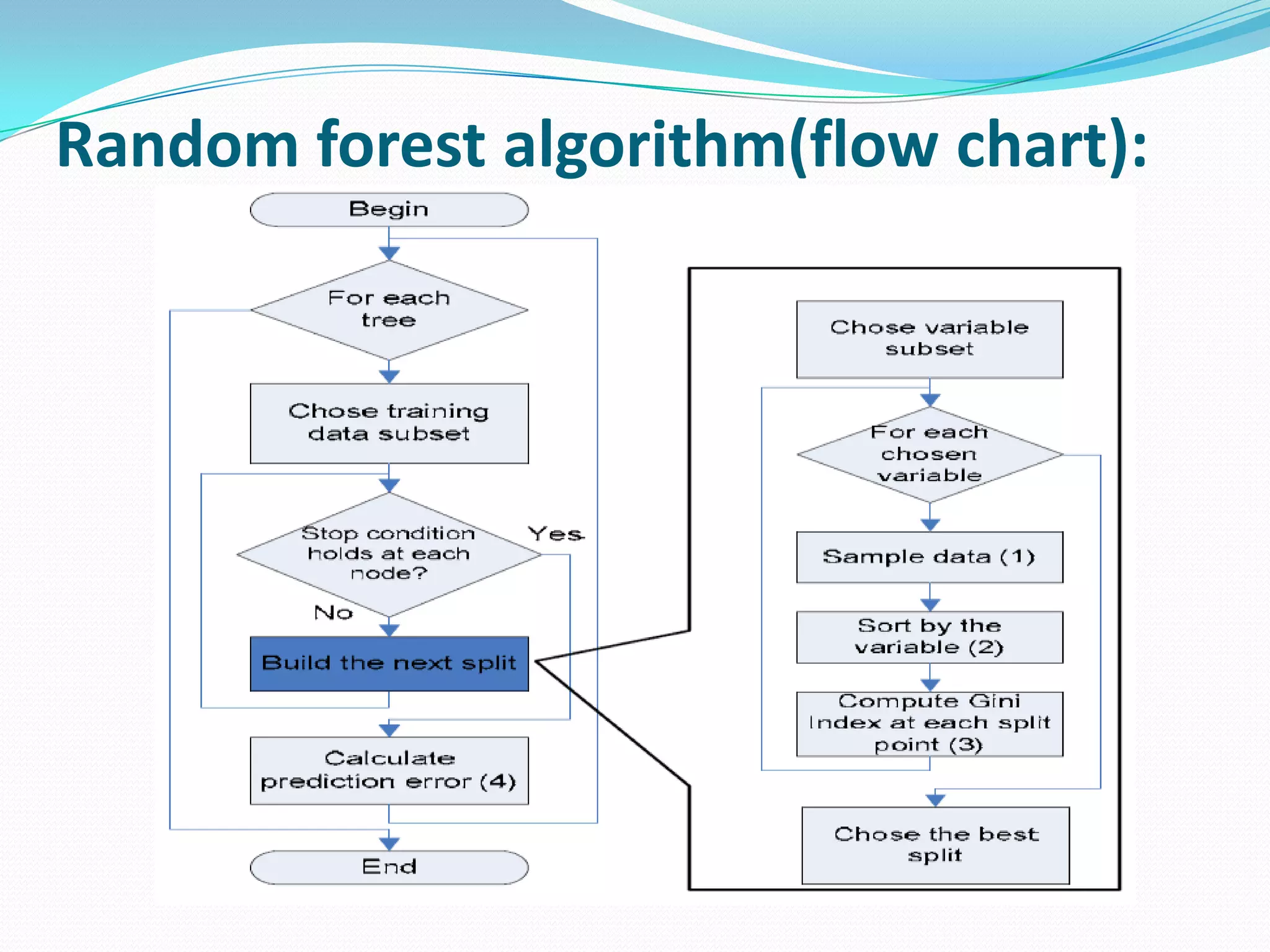






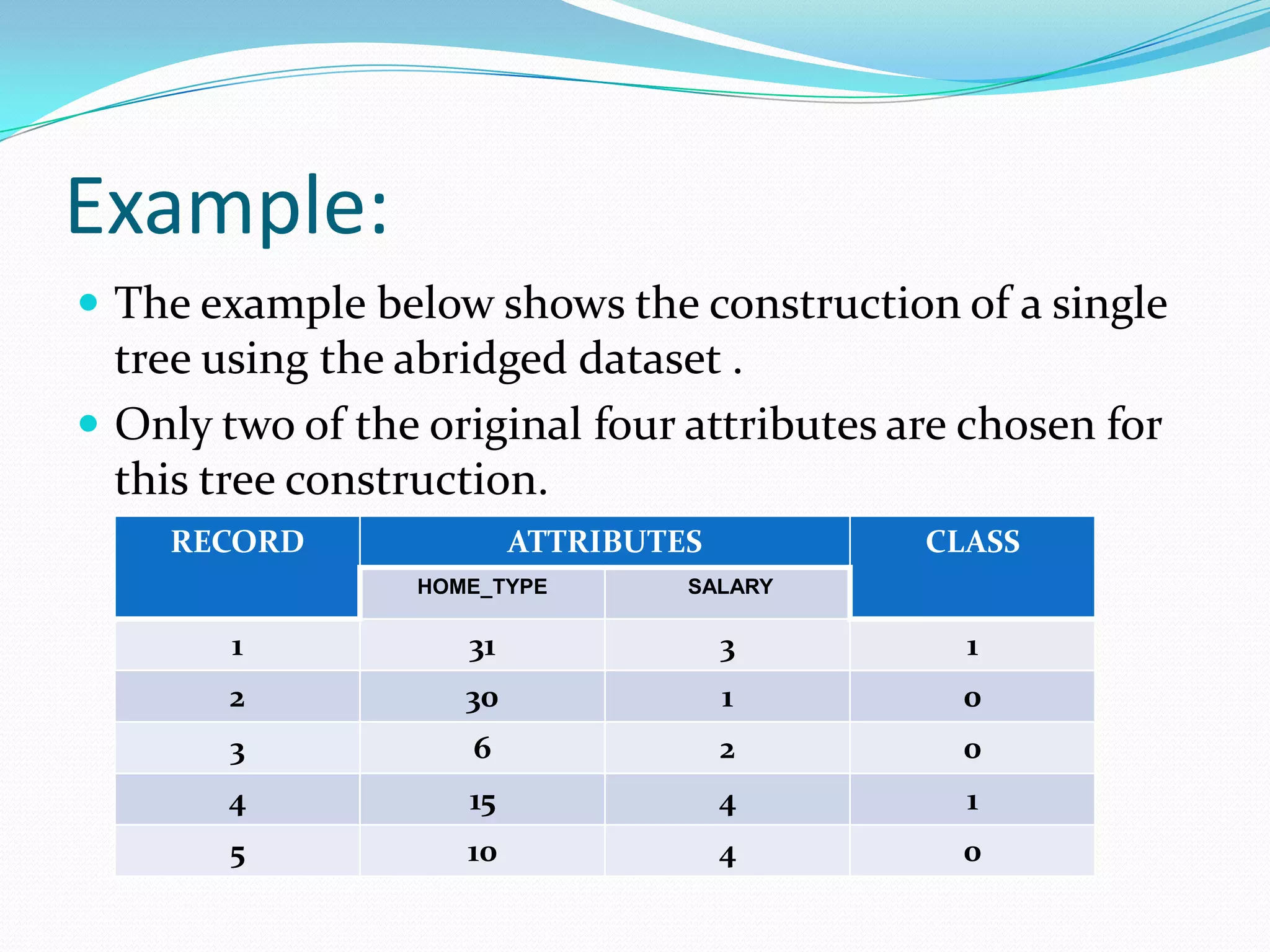








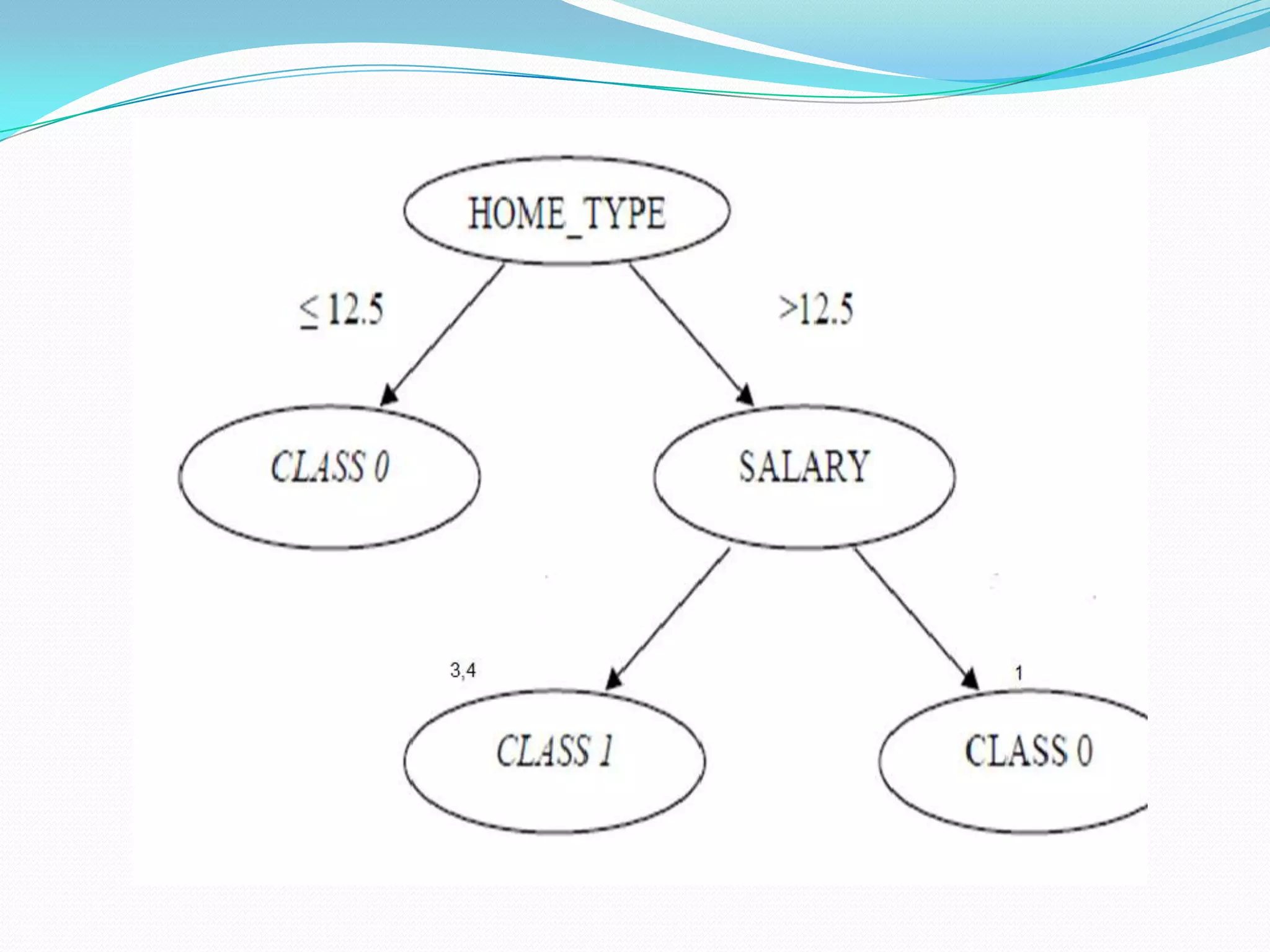




Random forests are an ensemble learning method that constructs multiple decision trees during training and outputs the class that is the mode of the classes of the individual trees. It improves upon decision trees by reducing variance. The algorithm works by: 1) Randomly sampling cases and variables to grow each tree. 2) Splitting nodes using the gini index or information gain on the randomly selected variables. 3) Growing each tree fully without pruning. 4) Aggregating the predictions of all trees using a majority vote. This reduces variance compared to a single decision tree.















































