
![Implementazione
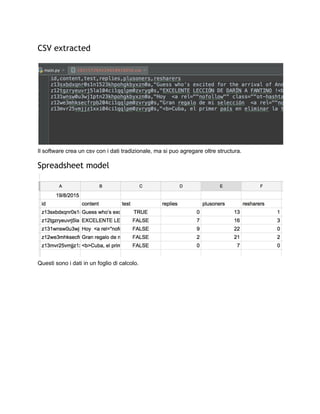
La colonna #test rappresenta la possibilità di analisi sopra un dizionario di parole, con questo
esplorare se l' ambiente sociale della persona utilizza lo stesso per la loro #post.
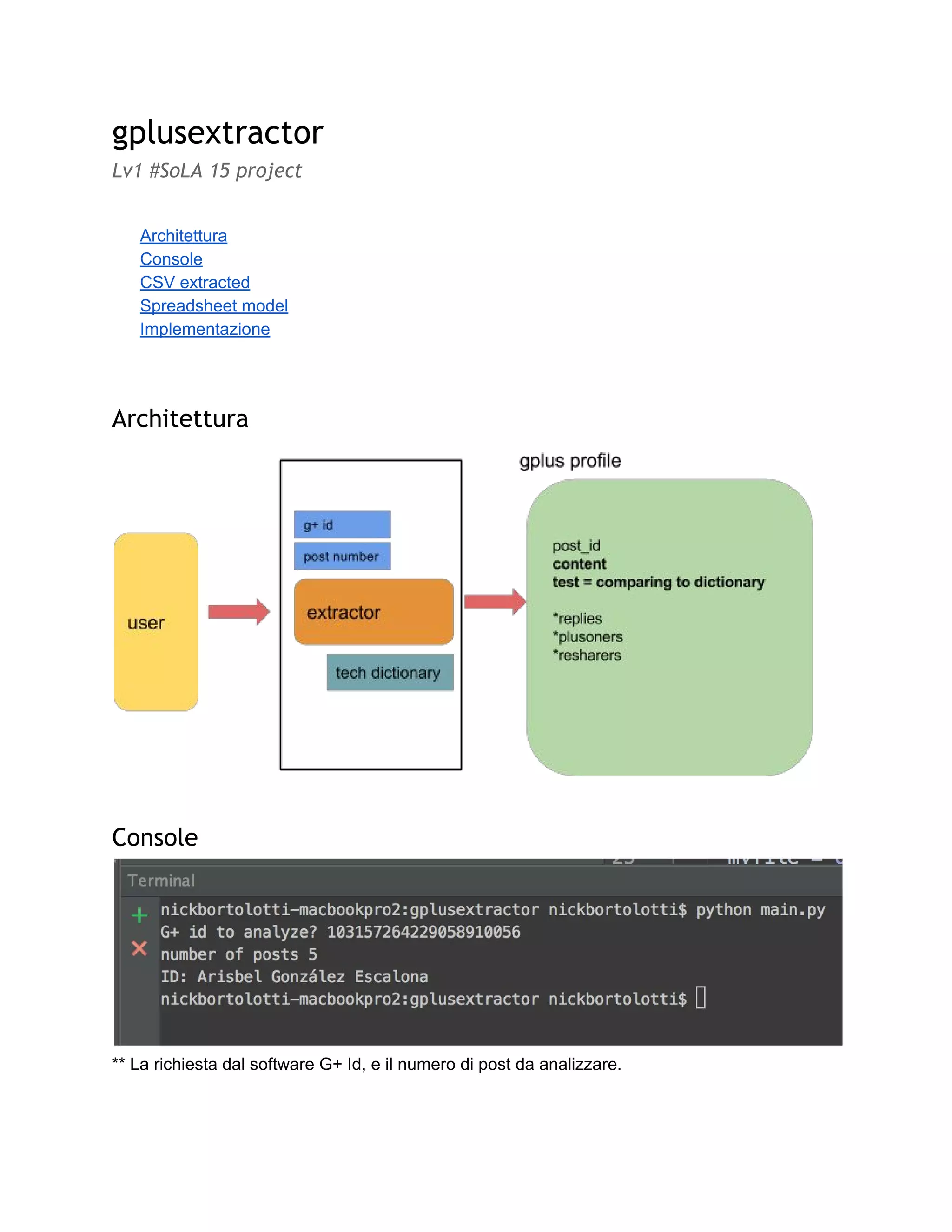
importsys
importcsv
importargparse
fromoauth2clientimportclient
fromapiclientimportsample_tools
Importazioni tipici al utilizzare
la G+ API e alcuni elementi
per la transizione verso #CSV
dal contenuto sociale.
argparser=argparse.ArgumentParser(add_help=False)
argparser.add_argument("-p","--parameters",nargs='+',
type=str,default=["android","polymer"],help="adding
parameters")
Passaggio di parametri [serie
di parole], per confrontare
con il corpo dal post.
people=raw_input('G+idtoanalyze?:')
postnumers=int(raw_input('numberofposts:'))
service,flags=sample_tools.init(
argv,'plus','v1',__doc__,__file__,
parents=[argparser],
scope='https://www.googleapis.com/auth/plus.me')
Le informazioni sull'account
da esaminare, poi viene
ricevuto il numero post to
analizare.
Il servizio di integrazione è
anche costruito.
person=service.people().get(userId=people).execute()
print'ID:%s'%person['displayName']
tech=flags.parameters
print'Parametersused:%s'%tech
request=service.activities().list(userId=person['id'],
collection='public',maxResults='1')
myfile=open(people+'.csv','wb')
i dati degli utenti sono
ottenuti, alcuni valori sono
mostrati
post sono richiesti.
anche si apre l'accesso al
csv.
try:
writer=csv.writer(myfile)
writer.writerow(('id','content','test','replies',
'plusoners','resharers'))
#Informationfromactivities
count=0
while(count<postnumers):
activities_document=request.execute()
if'items'inactivities_document:
foractivityinactivities_document['items']:
id=activity['id']
content=
activity['object']['content'].encode("utf-8")
test=any(xincontent.split()forxin
tech)
noi iniziamo a scrivere l’
schema into il CSV.
Dopo raccogliamo tutte le
informazioni dall'ambiente
sociale.](https://image.slidesharecdn.com/publicgplusextractorlv1sola15projectitaliano-151128204351-lva1-app6891/85/Public-gplusextractor-Social-italian-3-320.jpg)
![replies
=activity['object']['replies']['totalItems']
plusoners
=activity['object']['plusoners']['totalItems']
resharers=
activity['object']['resharers']['totalItems']
writer.writerow((id,content,test,replies,
plusoners,resharers))
count=count+1
request=service.activities().list_next(request,
activities_document)](https://image.slidesharecdn.com/publicgplusextractorlv1sola15projectitaliano-151128204351-lva1-app6891/85/Public-gplusextractor-Social-italian-4-320.jpg)

Il documento descrive un software che estrae dati da Google+ per analizzare post e interazioni sociali, creando un file CSV con informazioni dettagliate. Attraverso parametri specificati, il programma può aggregare e analizzare contenuti relativi a parole chiave fornite. La struttura include richieste per accedere a informazioni degli utenti e raccogliere dati sociali attraverso un ciclo di elaborazione.



![[Public] GDS versión 2 - reviews template](https://cdn.slidesharecdn.com/ss_thumbnails/publicgds-reviewstemplate-151128224030-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)

















![Biac hackathon Excellency Awards [Lightning talk ]](https://cdn.slidesharecdn.com/ss_thumbnails/biachackathon-excellencyawards-160620193024-thumbnail.jpg?width=640&height=640&fit=bounds)
![Launchpad Buenos Aires - Season I #16 [mobile analysis]](https://cdn.slidesharecdn.com/ss_thumbnails/publiclaunchpadbuenosairesseasoni16mobileanalysis-160509173417-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Public] GDS Metodología de Revisión #2015](https://cdn.slidesharecdn.com/ss_thumbnails/publicgdsreviewmethodology2015-151218212200-thumbnail.jpg?width=640&height=640&fit=bounds)
![[public] Android Material design - #7arquetipos15 [español]](https://cdn.slidesharecdn.com/ss_thumbnails/publicandroiddemo-materialdesignlv1sola15project-151205173718-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Public] polymer demo - #7arquetipos15 [español]](https://cdn.slidesharecdn.com/ss_thumbnails/publicpolymerdemo-lv1sola15projectespanol-151205172925-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Public] gplusextractor #7arquetipos15 [español]](https://cdn.slidesharecdn.com/ss_thumbnails/publicgplusextractorlv1sola15projectespanol-151205111732-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Public] firebase demo - #7arquetipos15 [español]](https://cdn.slidesharecdn.com/ss_thumbnails/publicfirebasedemolv1sola15projectespanol-151205110651-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Public] between two worlds native&no-native experiences](https://cdn.slidesharecdn.com/ss_thumbnails/publicbetweentwoworlds-nativeno-nativeexperiences-151128224530-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Public] 7 arquetipos de la tecnología moderna [españa]](https://cdn.slidesharecdn.com/ss_thumbnails/public7arquetiposdelatecnologiamodernaespana-151127162045-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Public] 7 archetipi della tecnologia moderna [italy]](https://cdn.slidesharecdn.com/ss_thumbnails/public7archetipidellatecnologiamodernaitaly-151127154944-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)