La tesi di Pieredoardo Gabutti propone la creazione di un'interfaccia web interattiva per la selezione automatica di espressioni regolari, migliorando l'estrazione di testi in base ad esempi forniti dall'utente. Utilizzando un metodo di apprendimento attivo, l'interfaccia interagisce con un back end per ottimizzare la selezione delle espressioni, offrendo un sistema intuitivo e rapido per l'utente. Il sistema è sviluppato presso il machine learning lab dell'Università di Trieste e utilizza tecnologie web come HTML, CSS e JavaScript.





![2) Progettazione del sistema: facendo riferimento a risultati già ottenuti in [1,2,3],
vengono definite nel dettaglio le varie fasi della procedura iterativa di estrazione,
selezione query e risposta a query, oltre ai criteri di f-measure, tokenizzazione e
uncertainty sampling utilizzati all’interno di queste fasi.
3) Descrizione dell’interfaccia: viene descritto l’aspetto grafico dell’interfaccia e il
funzionamento di tutti i componenti realizzati per la stessa. Vengono inoltre fornite
delle istruzioni per l’esecuzione corretta di una ricerca.
4) Documentazione: viene fornita una descrizione dell’architettura con cui è stata
realizzata l’applicazione e la definizione delle variabili e delle funzioni principali
create per la stessa. Si può trovare anche una spiegazione su come sostituire l’attuale
back end di stub con altro codice scritto esternamente.
5) Esperimenti: vengono descritti gli esperimenti effettuati per testare le funzionalità
dell’interfaccia ed analizzati i risultati ottenuti alla fine dei test.
Il capitolo Conclusioni, infine, contiene le considerazioni finali sul lavoro svolto.
5](https://image.slidesharecdn.com/ddfngnmurbmpar9s1uam-signature-eb193adc27afcfe570f2abe236be18a89434659cc3996a48ffab04871b7d0b6a-poli-180703094831/75/Progetto-e-realizzazione-di-un-interfaccia-web-interattiva-per-un-sistema-di-generazione-automatica-di-espressioni-regolari-6-2048.jpg)




![nessuna di esse oppure la cui sottostringa si sovrappone o coincide a sottostringhe presenti in . LeXu
estrazioni di tipo false negative sono quelle la cui sottostringa è presente in ma non lo è inXm
nessuna delle estrazioni di . I delimitatori indicano che ci si riferisce alla cardinalità delE | }{ · |
relativo insieme di estrazioni.
Una volta ricavati i valori di precision e recall, si può ricavare la F-measure come media
armonica di questi due risultati:
F = 2 ·
precision · recall
precision + recall
Fase di selezione query
La seconda fase della procedura iterativa consiste nel costruire una possibile estrazione dal
testo , chiamata query, da mostrare all’utente per ottenerne una risposta.xq
Questa fase è suddivisa in due sotto-fasi differenti di cui viene fornita la descrizione già formulata in
[1]:
Figura 3: Schema della fase di selezione query. Il con valore assegnato più vicino allo 0 vieneokent c
selezionato come .xq
10](https://image.slidesharecdn.com/ddfngnmurbmpar9s1uam-signature-eb193adc27afcfe570f2abe236be18a89434659cc3996a48ffab04871b7d0b6a-poli-180703094831/75/Progetto-e-realizzazione-di-un-interfaccia-web-interattiva-per-un-sistema-di-generazione-automatica-di-espressioni-regolari-11-2048.jpg)
![1) Una fase di tokenizzazione del testo, nella quale viene partizionato in pezzi chiamati tokens
separati da dei delimitatori i quali vengono determinati sfruttando come informazioni le
sottostringhe presenti in .Xm
2) Una fase di classificazione dei token di testo ottenuti, assegnando un punteggio a ciascunoc
di essi mediante il criterio di uncertainty sampling, che sfrutta come informazioni gli insiemi
di estrazioni dei primi estrattori ricavati e ordinati durante la fase di estrazione.X 0n = 1 E
Questo punteggio definisce il grado di incertezza sull'estrazione o meno del token da parte
degli estrattori selezionati.
A questo punto viene selezionato come query il token con punteggio assegnato il più vicino
possibile allo 0 (quindi con il grado di incertezza più elevato) che non si sovrapponga in alcun modo a
nessuna sottostringa di o .Xm
Xu
Tokenizzazione del testo
Figura 4: esempio di tokenizzazione del testo.
La procedura di tokenizzazione [1] è necessaria perché non si può affermare con certezza
assoluta che i migliori token candidabili come query si ottengano spezzando il testo semplicemente in
parole, linee, frasi o costrutti di questo tipo. La suddivisione deve essere fatta usando delimitatori
particolari e adatti all’istanza del problema in esame.
L’obiettivo di questa procedura è ricavare un insieme di caratteri che agiscano daS
separatori fra i token del testo. Per fare ciò si costruisce un insieme che includa ogni carattere cheS0
sia immediatamente precedente o successivo nel testo rispetto a ciascuna sottostringa contenuta in Xm
ad una certa iterazione. Successivamente si ordina in ordine decrescente per numero di apparizioniS0
di ogni singolo carattere. A questo punto si iterano i passi successivi partendo da : (I) sii = 1
costruisce l’insieme dei primi caratteri di ; (II) si costruisce l’insieme dei token ottenutiSi i S0 Ti
applicando in i delimitatori contenuti in . Infine si definisce dove è l’insieme ches Si =S : Si* Si*
contiene il maggior numero di token che siano anche sottostringhe presenti in , quindiXm
. In caso di pareggio, viene selezionato il valore di più piccolo.rg max |T |i* = a i i ⋂ Xm
i
11](https://image.slidesharecdn.com/ddfngnmurbmpar9s1uam-signature-eb193adc27afcfe570f2abe236be18a89434659cc3996a48ffab04871b7d0b6a-poli-180703094831/75/Progetto-e-realizzazione-di-un-interfaccia-web-interattiva-per-un-sistema-di-generazione-automatica-di-espressioni-regolari-12-2048.jpg)
![Uncertainty sampling
Il criterio di uncertainty sampling[1] dà la possibilità di classificare i token ricavati dal testo
in base al livello di incertezza che hanno gli estrattori di estrarre o meno quel determinato token.
Il metodo per assegnare il punteggio al token è il seguente: inizialmente ad ogni token vienet
associato un punteggio , dopodiché per ognuno degli estrattori selezionati si verifica se ilc = 0 n E
token è contenuto o meno nell’insieme di estrazioni relativo . Se il token coincide esattamente conX
una delle estrazioni contenute in il punteggio del token viene incrementato di 1 , altrimentiX t )( ∈ X
viene decrementato di 1 . Infine si ricava il punteggio medio dividendo il valore ottenuto dit ∈ )( / X
per ; in questo modo si ottiene un valore .c n − 1 ≤ c ≤ 1
Il valore assoluto fornisce il livello di incertezza ricercato per il token . Più questo valorec|| t
è vicino allo zero, più il grado di incertezza è elevato e il token è adeguato per essere selezionato
come query .xq
Fase di risposta query
L’ultima fase della procedura iterativa consiste nel dare la possibilità all’utente di fornire una
risposta di tipo yes, no oppure edit alla query selezionata ed aggiornare gli insiemi e dixq Xm
Xu
conseguenza.
Una risposta di tipo binario (yes/no) viene risolta semplicemente aggiungendo il contenuto di
in in caso di risposta positiva, in in caso di risposta negativa.xq Xm
Xu
Una risposta di tipo edit, invece, non aggiorna in alcun modo il contenuto di e maXm
Xu
concede all’utente di modificare il contenuto di selezionando direttamente dal testo una qualsiasixq
nuova sottostringa. Questa nuova sottostringa viene automaticamente selezionata come query nellaxq
successiva iterazione della procedura, saltando di fatto sia le fasi di estrazione (superflua dato che non
ci sono nuove informazioni in e ) che di selezione query (in quanto la query è già stataXm
Xu
selezionata). L’utente a questo punto ha la possibilità di rispondere alla così generata sia con unaxq
risposta binaria che nuovamente con una di tipo edit.
12](https://image.slidesharecdn.com/ddfngnmurbmpar9s1uam-signature-eb193adc27afcfe570f2abe236be18a89434659cc3996a48ffab04871b7d0b6a-poli-180703094831/75/Progetto-e-realizzazione-di-un-interfaccia-web-interattiva-per-un-sistema-di-generazione-automatica-di-espressioni-regolari-13-2048.jpg)




![Codice importato
● AngularJS 1.6.6 - framework di AngularJS.
● JQuery 3.2.1 - libreria di JQuery.
● Bootstrap 3.3.7 - framework di Bootstrap 3.
● UI Bootstrap 2.5.0 - direttive AngularJS per Bootstrap 3.
● Angular-bind-html-compile - direttiva angularJS per compilare contenuti dinamici
contenenti direttive.
Tipi di oggetti definiti
Substring
Definizione: una sottostringa del testo definita dagli indici dei caratteri di inizio e di fine all’internos
del testo stesso.
Proprietà:
- int start: indice del primo carattere della sottostringa in .s
- int end: indice del carattere successivo all’ultimo della sottostringa in .s
Extraction
Definizione: una estrazione del testo definita dalla sottostringa estratta e da un valore di confidenza.s
Proprietà:
- Substring substring: oggetto di tipo Substring indicante la sottostringa estratta
dal testo.
- float confidence: numero reale compreso tra -1 e 1 indicante il valore di confidenza
della relativa estrazione.
Extractor
Definizione: un oggetto che contiene un estrattore, che nel caso di questa interfaccia è un’espressione
regolare, e l’insieme di estrazioni da di quel determinato estrattore.s
Proprietà:
- RegExp extractor: estrattore (espressione regolare) eseguito per le estrazioni dal testo.
- Extraction[ ] extractions: insieme contenente tutte le estrazioni dal testo ottenute
eseguendo l’estrattore (espressione regolare) sul testo.
20](https://image.slidesharecdn.com/ddfngnmurbmpar9s1uam-signature-eb193adc27afcfe570f2abe236be18a89434659cc3996a48ffab04871b7d0b6a-poli-180703094831/75/Progetto-e-realizzazione-di-un-interfaccia-web-interattiva-per-un-sistema-di-generazione-automatica-di-espressioni-regolari-21-2048.jpg)
![Variabili principali definite
Text
Tipo: String.
Descrizione: il testo di un’istanza del problema.s
Extractors
Tipo: Extractor[ ].
Descrizione: insieme di oggetti di tipo Extractor corrispondenti a (e relativo ) nellaE X
procedura iterativa.
Queries
Tipo: Extraction[ ].
Descrizione: insieme di oggetti di tipo Extraction corrispondenti a candidati per nellaxq
procedura iterativa.
Desired
Tipo: Substring[ ].
Descrizione: insieme corrispondente a di oggetti di tipo Substring.Xm
Undesired
Tipo: Substring[ ].
Descrizione: insieme corrispondente a di oggetti di tipo Substring.Xu
Rgx
Tipo: RegExp[ ].
Descrizione: variabile creata per lo stub del back end. Insieme di espressioni regolari utilizzato dallo
stub.
To show
Tipo: String.
Descrizione: testo formattato con le dovute evidenziazioni e sottolineature e mostrato sullo schermo
all’utente.
21](https://image.slidesharecdn.com/ddfngnmurbmpar9s1uam-signature-eb193adc27afcfe570f2abe236be18a89434659cc3996a48ffab04871b7d0b6a-poli-180703094831/75/Progetto-e-realizzazione-di-un-interfaccia-web-interattiva-per-un-sistema-di-generazione-automatica-di-espressioni-regolari-22-2048.jpg)


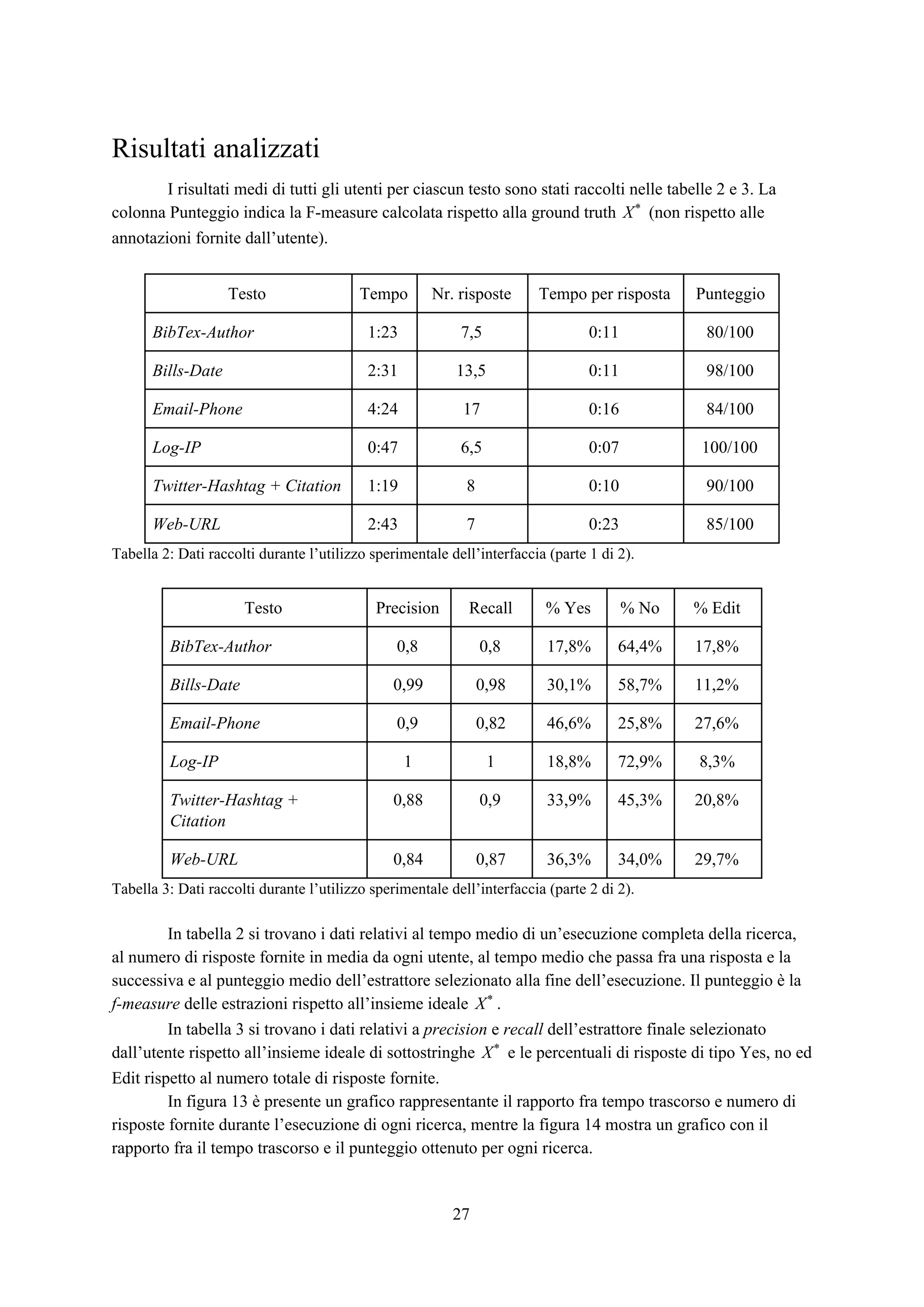
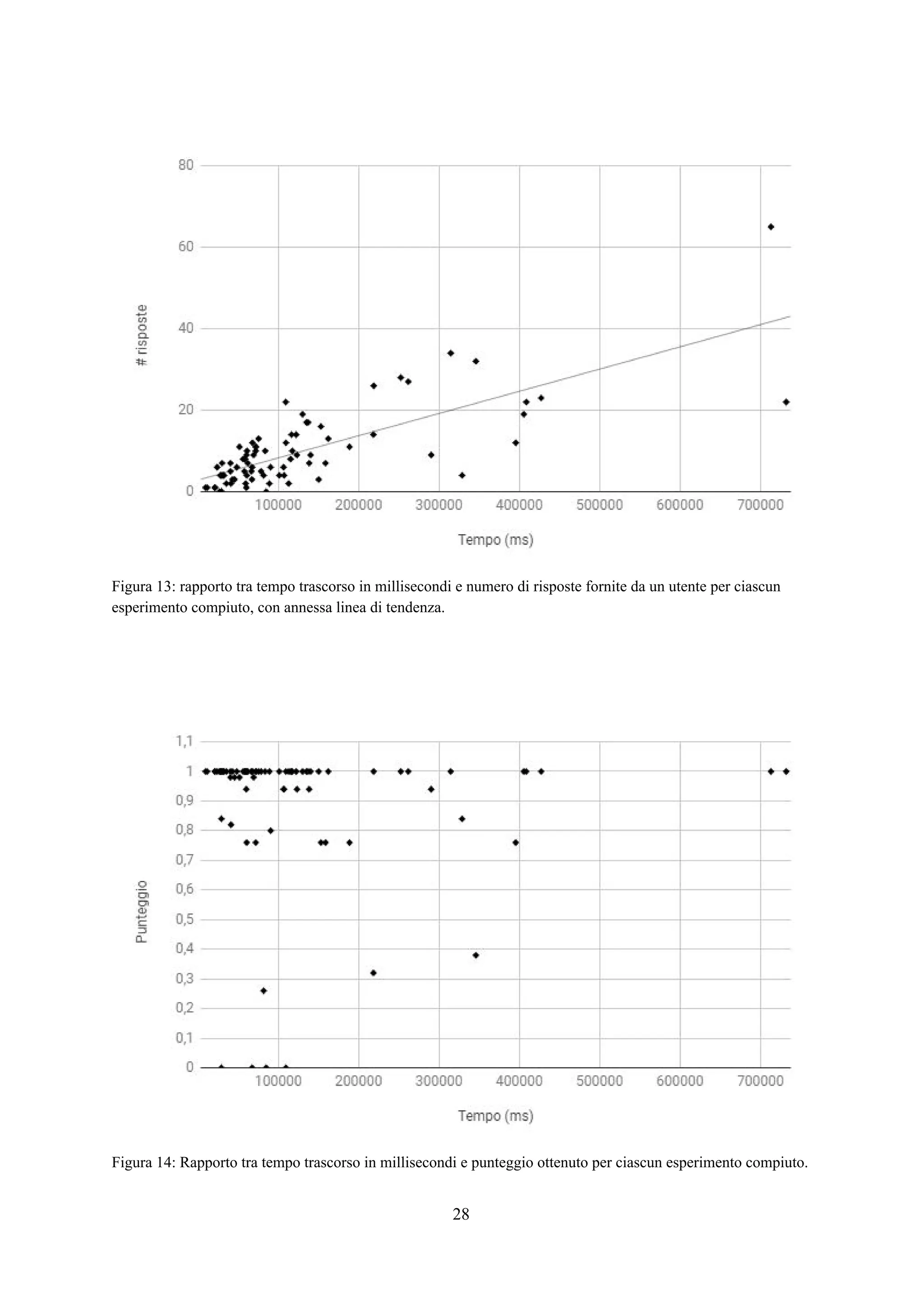
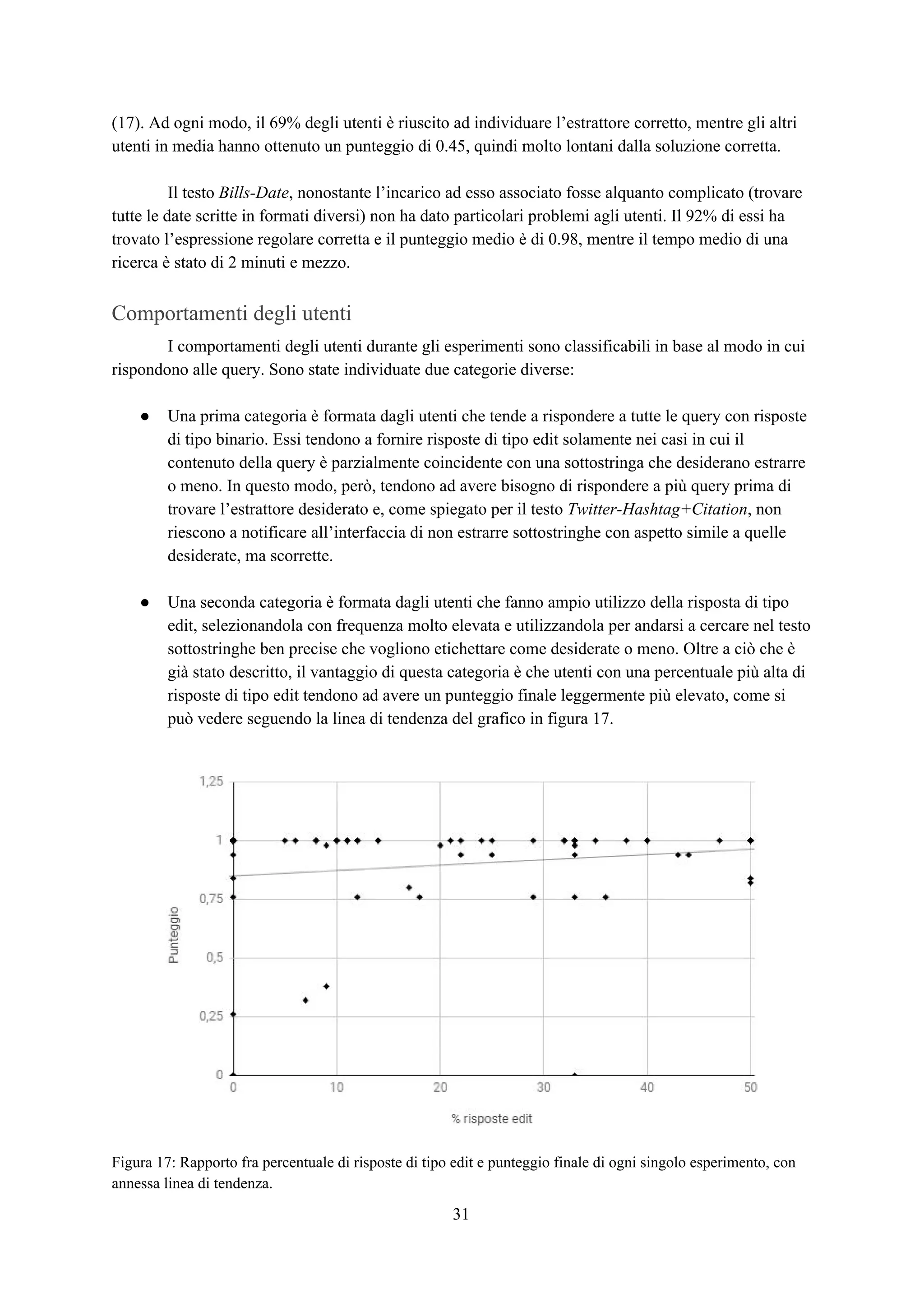
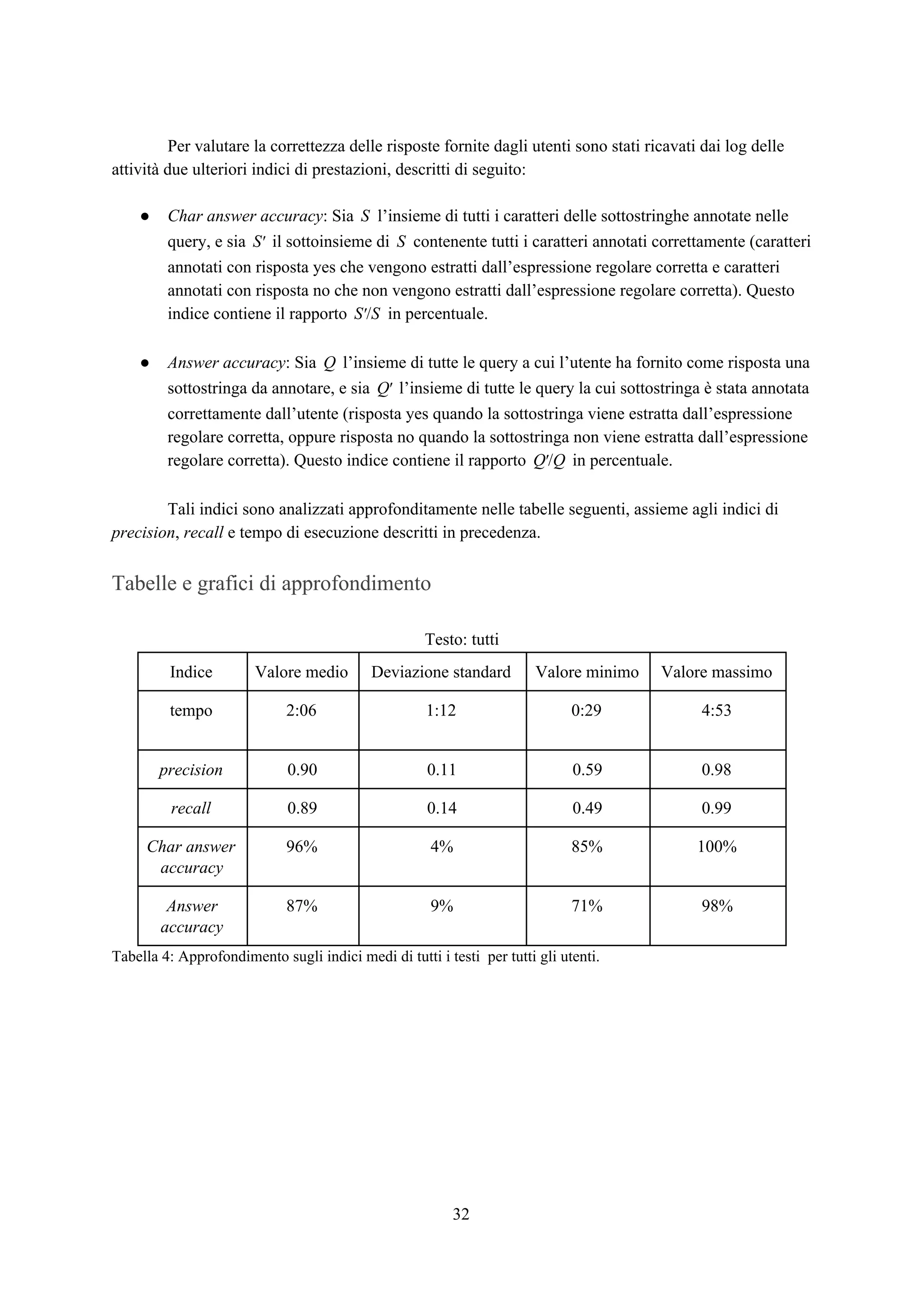
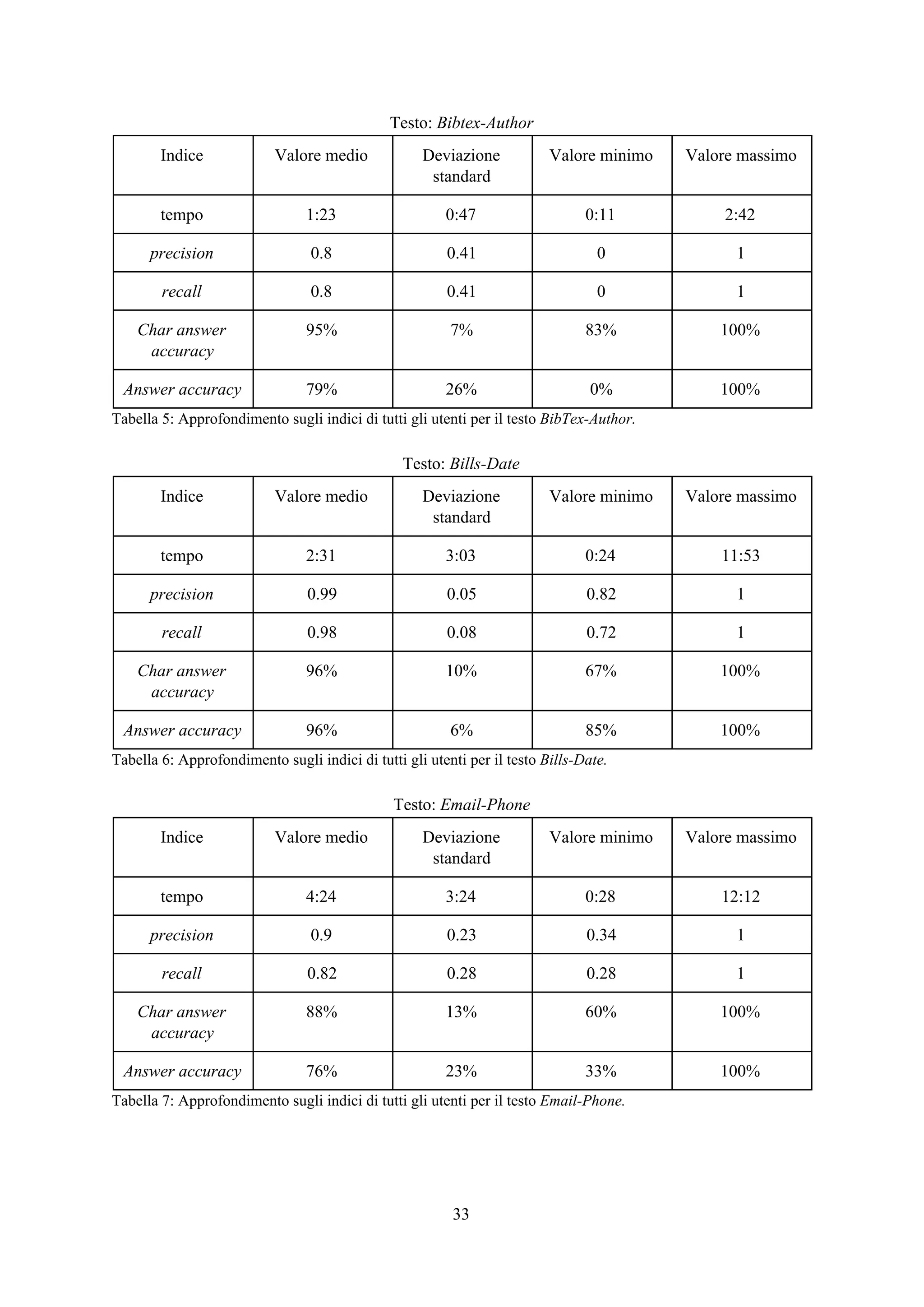
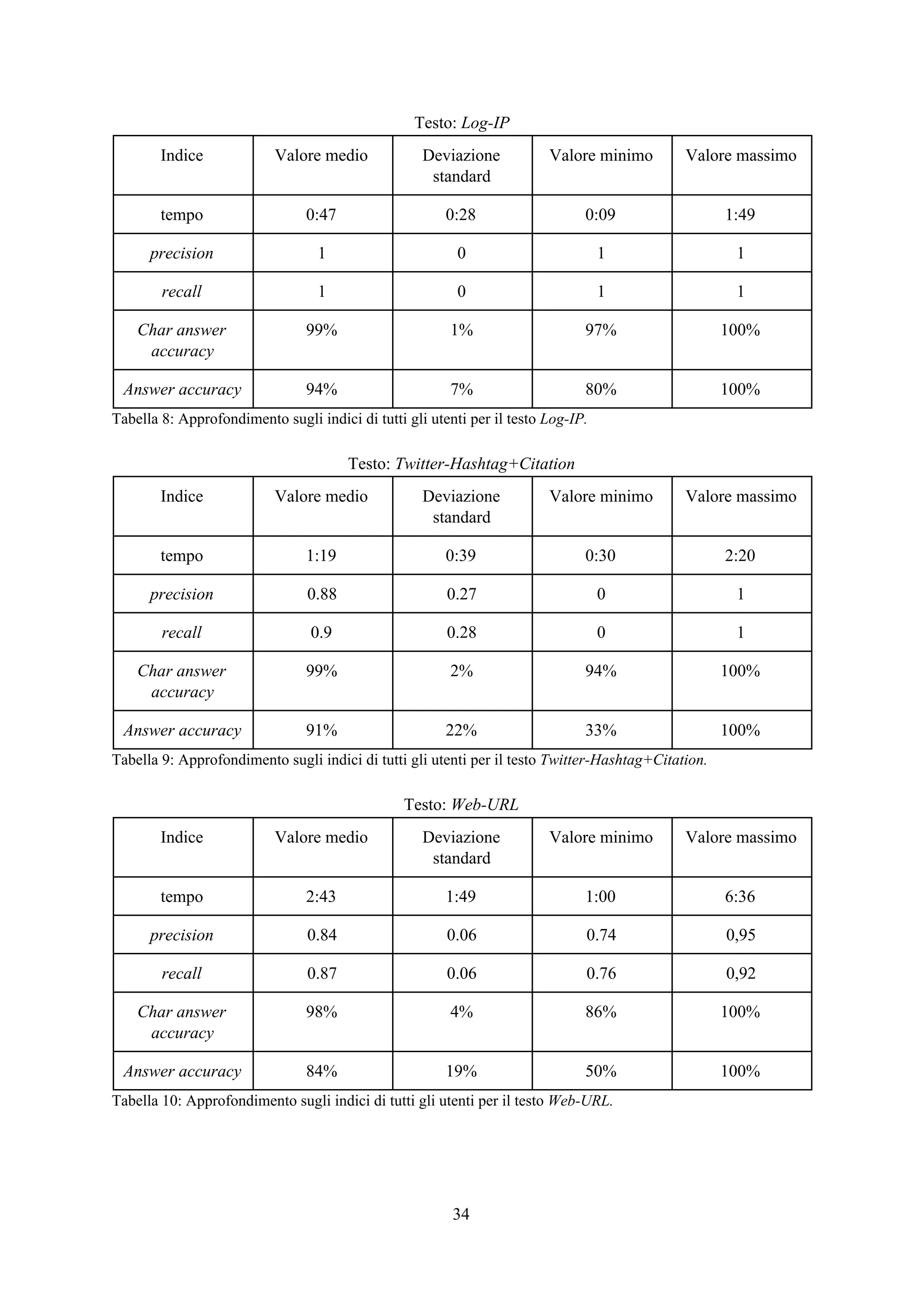
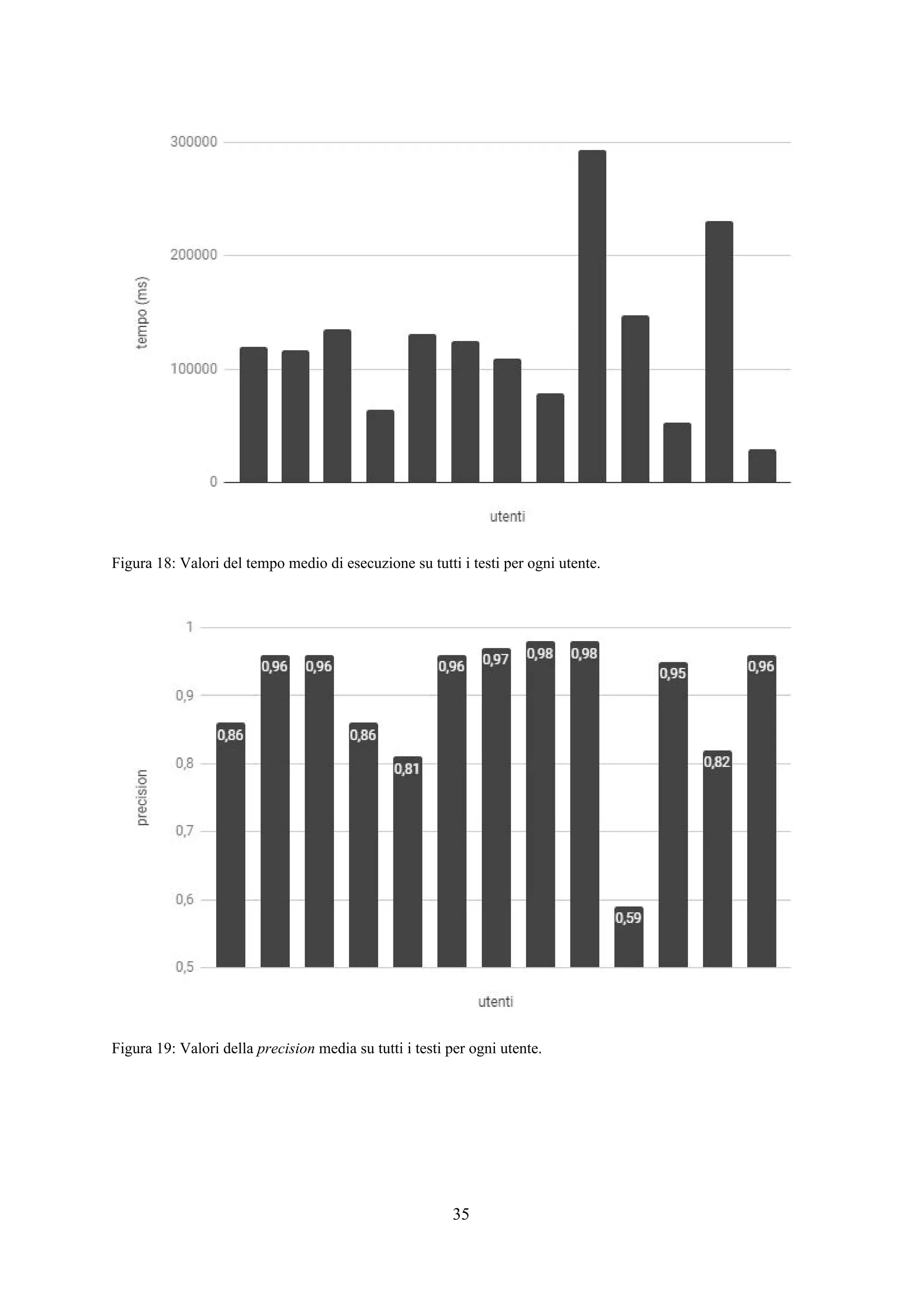
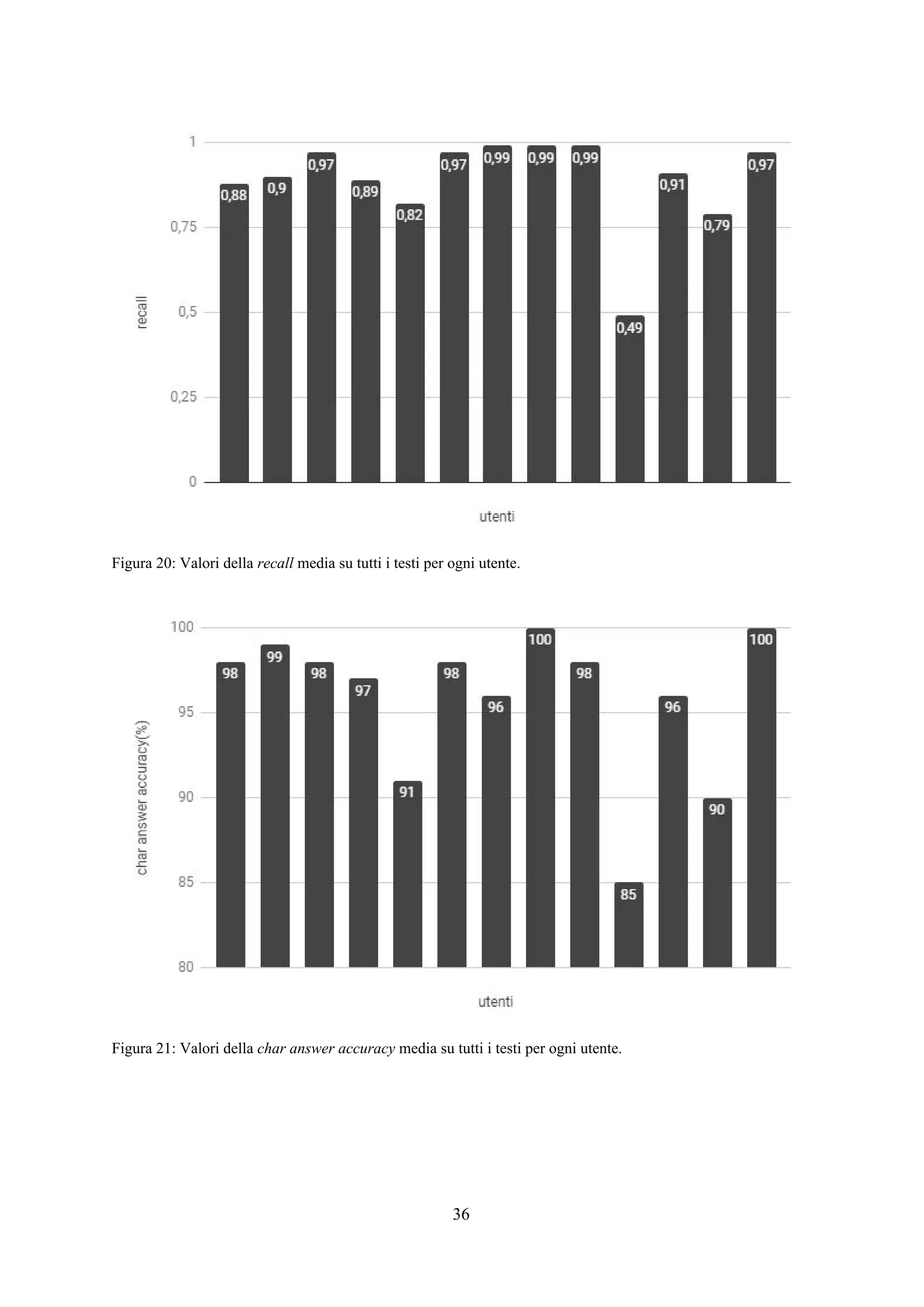
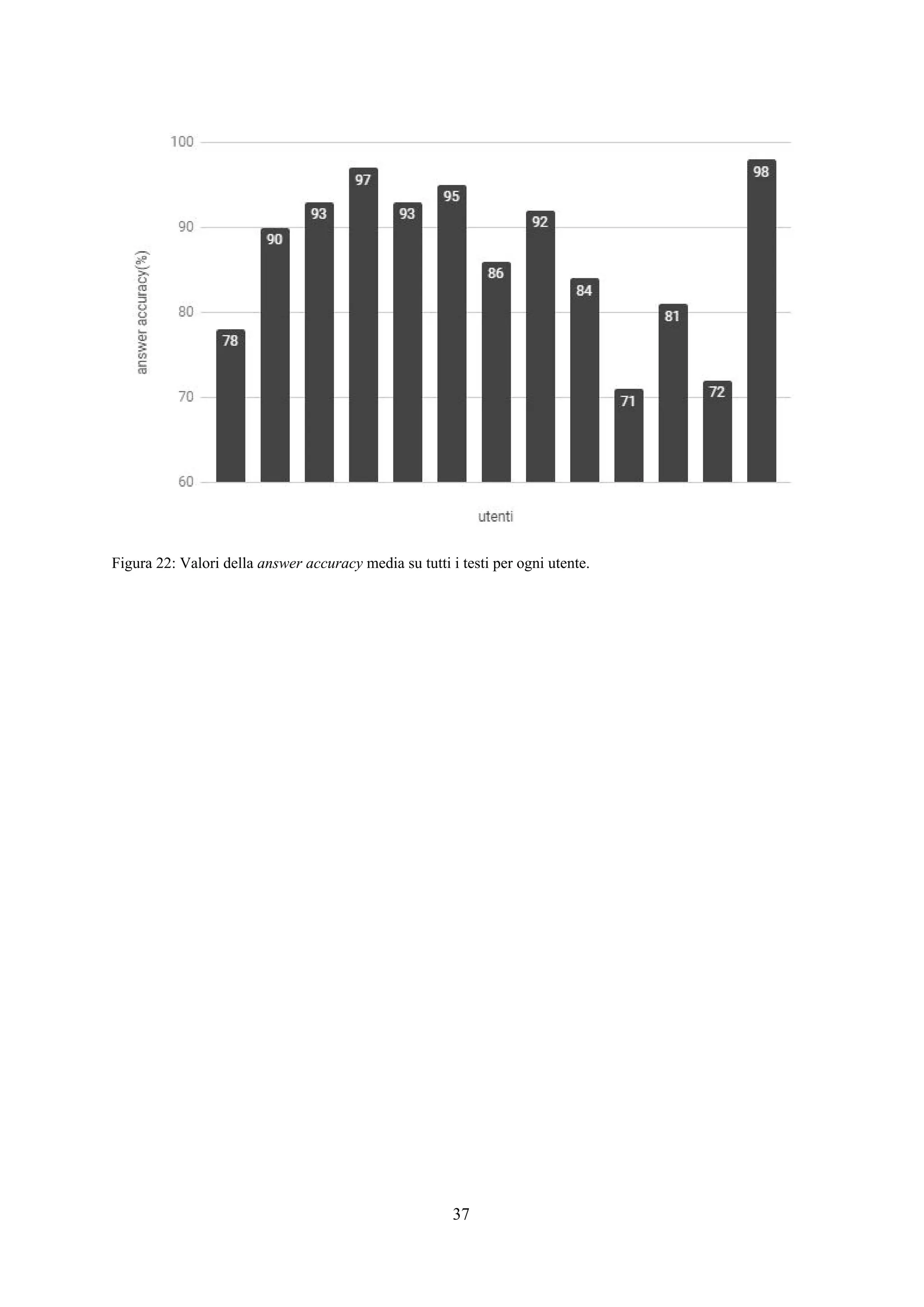
![Esperimenti
Panoramica
Lo scopo degli esperimenti è verificare l’efficacia e la rapidità dell’applicazione web così
costruita nel trovare tutte e sole le sottostringhe appartenenti all’insieme ideale . Per fare ciò,X*
l’interfaccia è stata affidata ad alcuni utenti per l’utilizzo con l’incarico di trovare da alcuni testi
prefissati dei frammenti che seguono un pattern specifico e fissato in modo univoco per ogni testo.
Per ogni attività di un singolo utente su un singolo testo è stato memorizzato un file di log
contenente informazioni su ogni passo iterativo effettuato riguardo il tempo trascorso, la query
selezionata dall’applicazione, la risposta fornita dall’utente e i valori di precision e recall del primo
estrattore classificato dall’applicazione calcolati per ricavare la f-measure come descritto nel capitolo
relativo alla progettazione del sistema. Alla fine della procedura iterativa viene memorizzata
l’espressione regolare finale selezionata dall’utente.
Testi e utenti
In fase di sperimentazione sono stati utilizzati 6 diversi testi preventivamente selezionati da
un dataset fornito dal Machine Learning Lab dell’Università di Trieste (presenti in [4,5,6]) ed adattati
in modo che per ciascuno di essi l’insieme di sottostringhe ideale contenesse esattamente 25X*
elementi (26 per BibTex-Author). Per ognuno di questi testi è presente una espressione regolare
nell’insieme delle disponibili che estrae le sottostringhe di con valori di precision e recall di 1. IX*
testi sono brevemente descritti di seguito. In tabella 1 sono fornite alcune delle informazioni più
importanti relative ai testi descritti. è la lunghezza media di una sottostringa desiderata dal(x )*
estrarre, è il rapporto tra il numero di caratteri estratti e il numero di caratteri totali e è laρ (s)l
lunghezza del testo tagliato e utilizzato per l’applicazione.
Testo l(x )* ρ (s)l
BibTex-Author 15.5 0.17 2423
Bills-Date 10.6 0.02 12484
Email-Phone 13.2 0.04 9385
Log-IP 12.9 0.24 1414
Twitter-Hashtag + Citation 11.2 0.11 3004
Web-URL 52.2 0.04 57268
Tabella 1: Tabella dei testi utilizzabili e di informazioni relative.
25](https://image.slidesharecdn.com/ddfngnmurbmpar9s1uam-signature-eb193adc27afcfe570f2abe236be18a89434659cc3996a48ffab04871b7d0b6a-poli-180703094831/75/Progetto-e-realizzazione-di-un-interfaccia-web-interattiva-per-un-sistema-di-generazione-automatica-di-espressioni-regolari-26-2048.jpg)
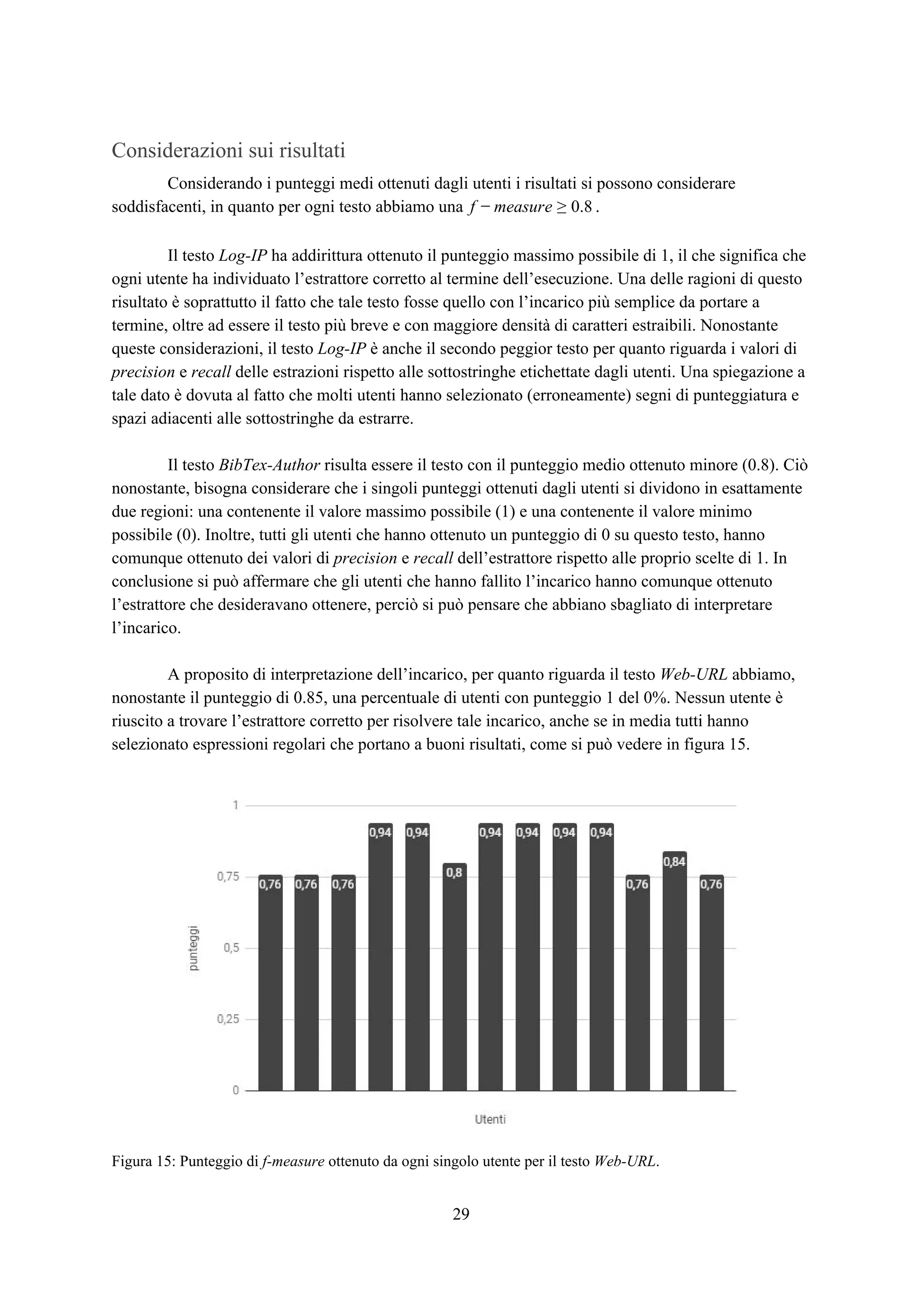
![● BibTex-Author: Un insieme di entrate bibtex in cui l’incarico è di trovare tutti i nomi
individuali completi all’interno dei campi autore. L’espressione regolare corretta per ottenere
èX*
(?<=author {0,3}= {0,3}{[^n]{0,300}?)([A-Z.{d'"()][A-Z
.a-z{}d'"-,()]*?)(?=(?= and )|(?=},s*[a-z])|n).
● Bills-Date: Un insieme di fatture in cui l’incarico è di trovare tutte le date, che possono avere
diversi formati. L’espressione regolare corretta per ottenere èX*
((?:[12]?d{1,3}s*[-./]s*[012]?ds*[-./]s*[12]?d{1,3})|(?:d{1
,2},s*[A-Z][a-z]+s+[12]d{3})|(?:[A-Z][a-z]+s+d{1,2},s+[12]d{3}))
.
● Email-Phone: Un insieme di estratti di email in cui l’incarico è di trovare tutti i numeri di
telefono. L’espressione regolare corretta per ottenere èX*
(?<=W|^)((?:[0-9](?: |-|.))?(?:(?[0-9]{3})?|[0-9]{3})(?:|/|
|-|.)?(?:[0-9]{3}(?: |-|.)[0-9]{4})).
● Log-IP: Un insieme di entrate di log per il software di un firewall in cui l’incarico è di trovare
tutti gli indirizzi IP. L’espressione regolare corretta per ottenere èX*
b(?:d{1,3}.){3}d{1,3}b.
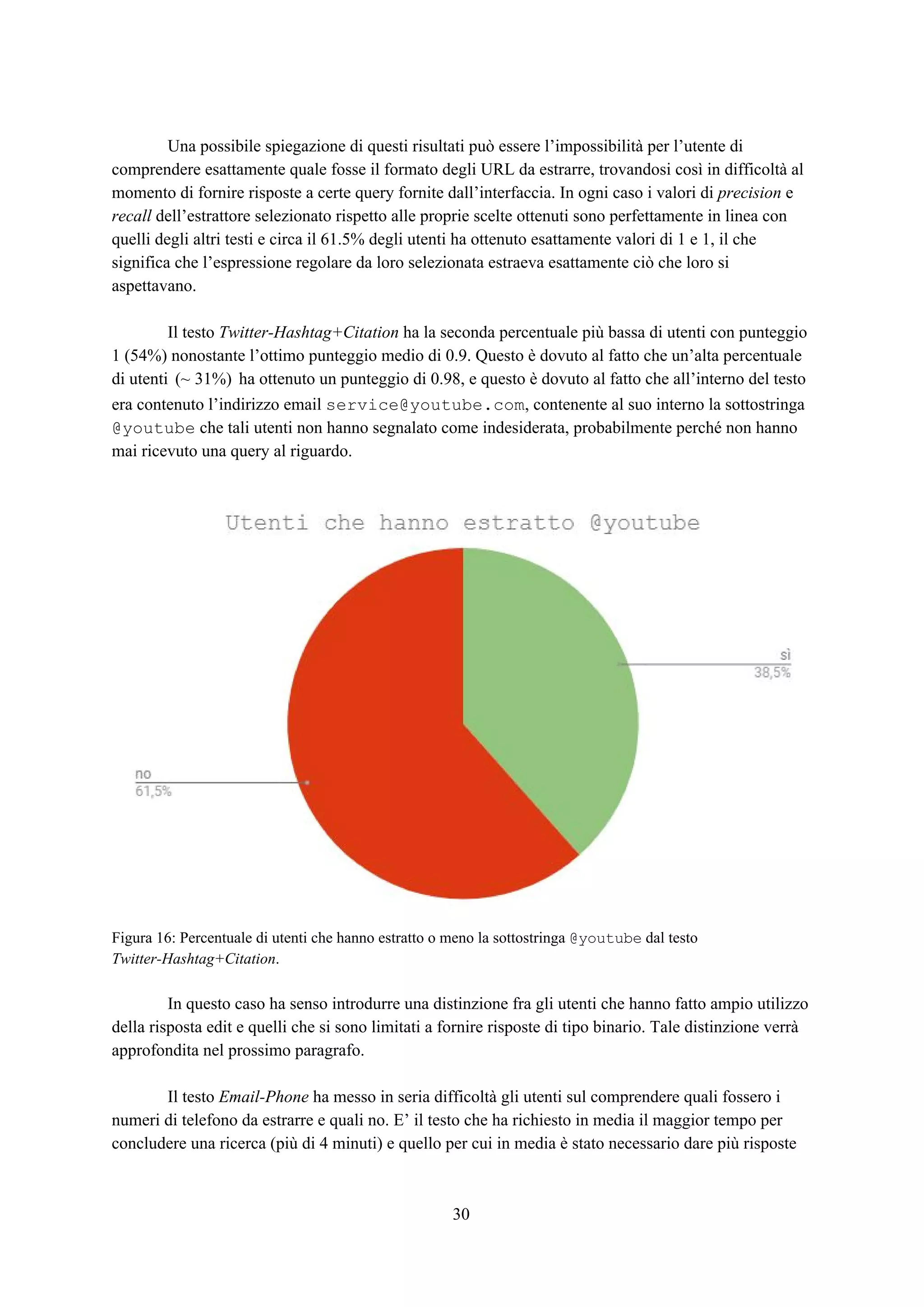
● Twitter-Hashtag+Citation: Un insieme di post di Twitter in cui l’incarico è di trovare tutti gli
hashtag (#machinelearning) e le citazioni (@MaleLabTs). L’espressione regolare
corretta per ottenere èX*
(?<=W|^)((?:@[A-Za-z0-9_]+)|(?:#[w]+(?<!#d{0,120}))).
● Web-URL: Un insieme di pagine web in HTML in cui l’incarico è di estrarre tutti gli URL.
L’espressione regolare corretta per ottenere èX*
(?<=^|b|W)((?:(https?|s?ftps?|smb|mailto)://)(?:[a-zA-Z0-9][^s:]+@
)?(?:(?:[a-zA-Z0-9-.:]+.[a-zA-Z]{2,3})|(?:[0-9]{1,3}(?:.[0-9]{1,3})
{3}))(?::d{1,5})?(?:[A-Za-z0-9.-$+!*'(),~_+%=&#/?@%;:]*)?(?<![.()=]+)
).
Gli esperimenti sono stati affidati ad un gruppo di 13 utenti dotati di diverse competenze in
ambito di espressioni regolari. Ad ognuno di essi è stato spiegato il funzionamento dell’interfaccia e
lasciata libertà di utilizzarla come preferissero per completare ciascuno dei 6 incarichi disponibili.
26](https://image.slidesharecdn.com/ddfngnmurbmpar9s1uam-signature-eb193adc27afcfe570f2abe236be18a89434659cc3996a48ffab04871b7d0b6a-poli-180703094831/75/Progetto-e-realizzazione-di-un-interfaccia-web-interattiva-per-un-sistema-di-generazione-automatica-di-espressioni-regolari-27-2048.jpg)

![Bibliografia
[1] Alberto Bartoli, Andrea De Lorenzo, Eric Medvet, Fabiano Tarlao. Interactive Example-Based
Finding of Text Items. 2018. [citato a p. 18]
[2] Alberto Bartoli, Andrea De Lorenzo, Eric Medvet, Fabiano Tarlao. Active Learning of Regular
Expressions for Entity Extraction. 2017.
[3] Alberto Bartoli, Andrea De Lorenzo, Eric Medvet, Fabiano Tarlao. Inference of Regular
Expressions for Text Extraction from Examples. 2016.
[4] Alberto Bartoli, Andrea De Lorenzo, Eric Medvet, and Fabiano Tarlao. Active learning
approaches for learning regular expressions with genetic programming. 2016. [citato a p. 25]
[5] Alberto Bartoli, Andrea De Lorenzo, Eric Medvet, and Fabiano Tarlao. Learning text patterns
using separate-and-conquer genetic programming. 2015. [citato a p. 25]
[6] Alberto Bartoli, Giorgio Davanzo, Andrea De Lorenzo, Eric Medvet, and Enrico Sorio. Automatic
Synthesis of Regular Expressions from Examples. 2014. [citato a p. 25]
[7] Sonal Gupta, Christopher D. Manning. SPIED: Stanford Pattern-based Information Extraction and
Diagnostics.
[8] Thomas Rebele, Katerina Tzompanaki, Fabian Suchanek. Visualizing the addition of missing
words to regular expressions.
[9] Burr Settles. Active Learning Literature Survey. Computer Sciences Technical Report 1648. 2009.
39](https://image.slidesharecdn.com/ddfngnmurbmpar9s1uam-signature-eb193adc27afcfe570f2abe236be18a89434659cc3996a48ffab04871b7d0b6a-poli-180703094831/75/Progetto-e-realizzazione-di-un-interfaccia-web-interattiva-per-un-sistema-di-generazione-automatica-di-espressioni-regolari-40-2048.jpg)



























