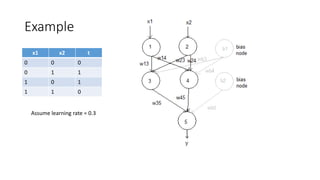
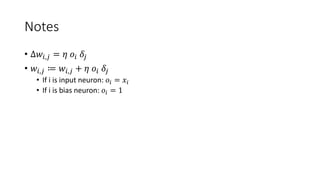This document describes the steps of backpropagation in a multi-layer perceptron neural network. It details the forward and backward passes for each training pattern in an epoch, including calculating the output, error, deltas, and updating the weights. An example is provided to demonstrate the process for one full epoch on a sample dataset with 4 patterns to classify.