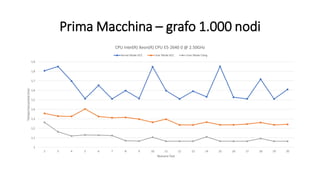
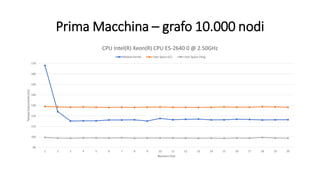
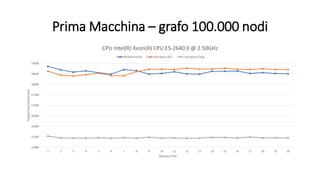
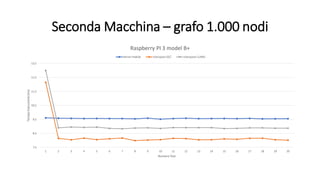
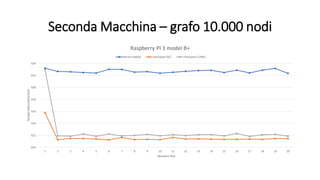
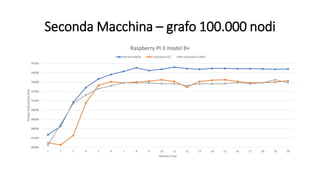
La tesi analizza le prestazioni dell'algoritmo di Dijkstra su Linux, confrontando le modalità utente e kernel. Sono state implementate due versioni dell'algoritmo, utilizzando due macchine diverse per eseguire benchmark su grafi di varie dimensioni. I risultati indicano che non ci sono miglioramenti significativi nelle prestazioni in modalità kernel, influenzate da vari fattori come il processore e il compilatore utilizzato.