Download to read offline

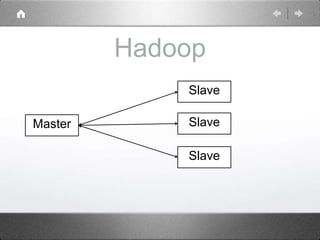
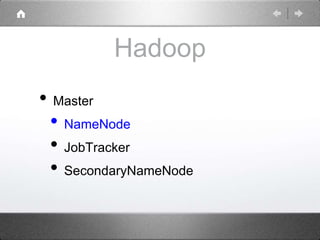

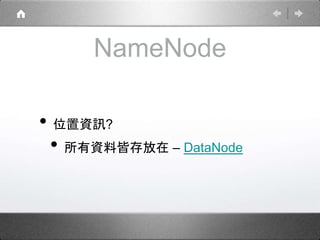

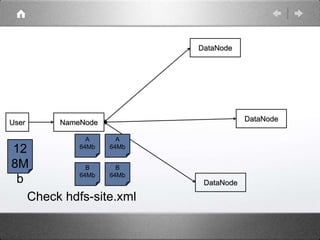
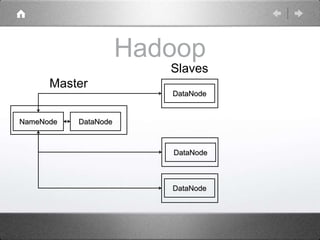
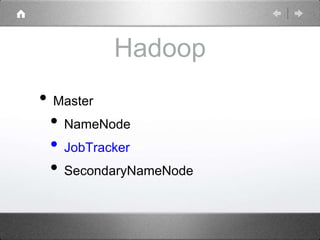


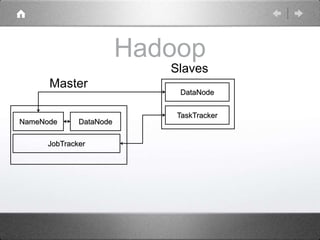


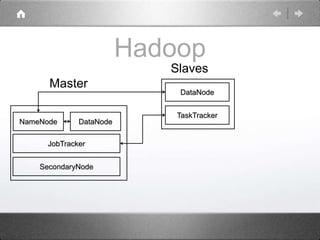
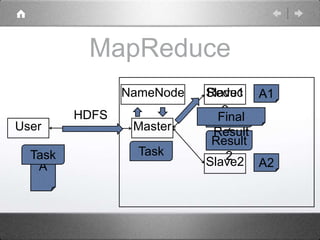


Hadoop is a distributed processing framework that operates on a master-slave architecture. The master node runs the NameNode, JobTracker, and SecondaryNameNode processes. The NameNode manages the file system metadata and location information for data stored across the DataNodes on slave nodes. The JobTracker manages job scheduling and coordination, assigning tasks to TaskTrackers on slaves. The SecondaryNameNode provides backup support in case the NameNode fails. Hadoop uses MapReduce as a programming model where user code is run as Maps on data subsets and the outputs are aggregated by Reduces.


























































