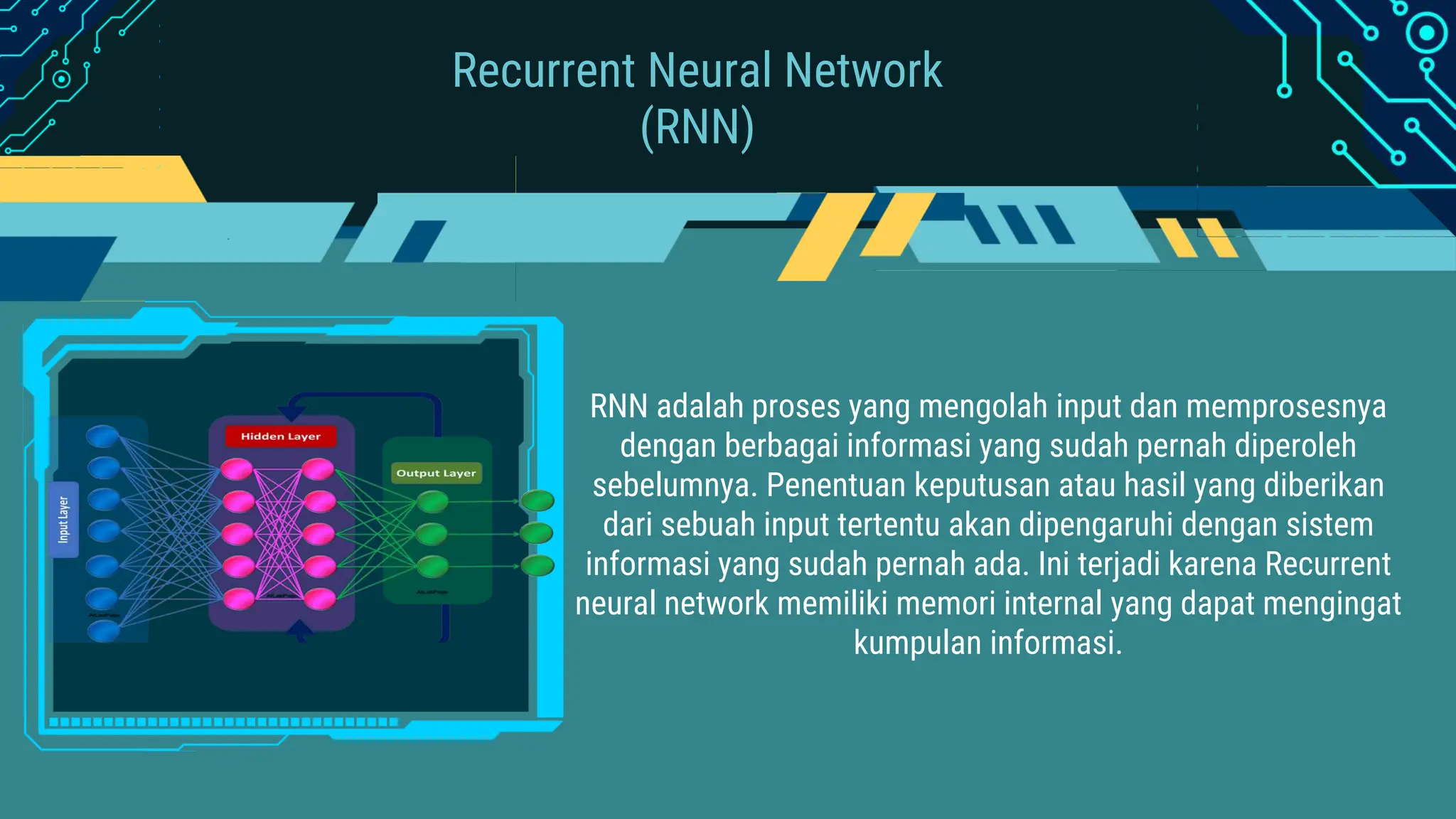
Dokumen tersebut membahas beberapa topik analisis seri waktu seperti model autoregresif, autokorelasi, dekomposisi seri waktu, jaringan saraf rekuren, dan memori jangka pendek dan panjang (LSTM). Topik-topik ini dielaborasi dengan contoh dan penjelasan tentang cara kerja, implementasi, dan perbedaan antara RNN dan LSTM.