Download to read offline





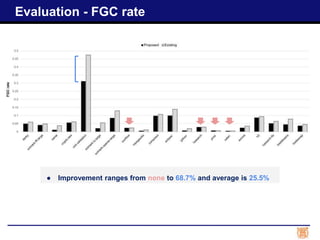
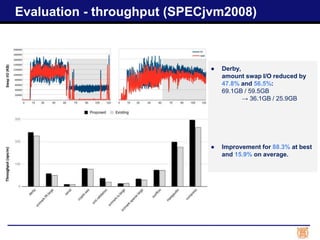
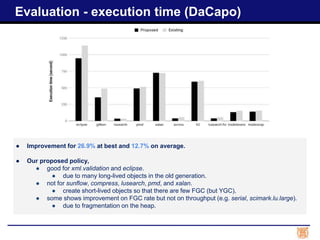


The progress report discusses advancements in garbage collection for the Java Virtual Machine using swap I/O optimization, detailing completed tasks and planned evaluations. It highlights performance improvements in terms of garbage collection rates, throughput, and execution time across industry-standard benchmarks. Future work includes optimizing kernel APIs and implementing fine-grained compaction to address fragmentation issues.









































![20260201 [FOSDEM] gomodjail - library sandboxing for Go modules.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/20260201fosdemgomodjail-librarysandboxingforgomodules-260201225659-76609ec4-thumbnail.jpg?width=640&height=640&fit=bounds)





![谷歌留痕技术教程[ 𝙩𝙤𝙥 𝟮𝟯𝟯. 𝙘 𝙤𝙢 ]](https://cdn.slidesharecdn.com/ss_thumbnails/top233-260130173900-2eb784f9-thumbnail.jpg?width=640&height=640&fit=bounds)







