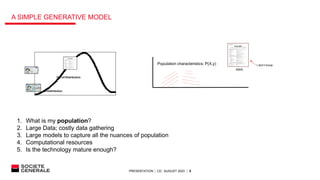
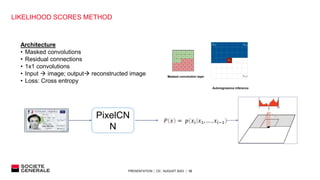
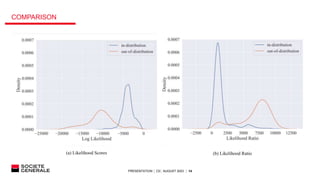
The document presents research on out-of-distribution detection for AI models. It discusses how most AI models are overconfident and not robust when facing out-of-distribution data. Several discriminative and generative approaches for out-of-distribution detection are surveyed from literature, including likelihood ratios, softmax scores, and conformal prediction. Experiments on a document classification task find that a likelihood-based approach performs best at distinguishing in-distribution documents from out-of-distribution ones like images, with a high true positive rate and low false positive rate. Future work to improve industrialization of the model is discussed.






![PRESENTATION │ C0│ AUGUST 2023 │ 8
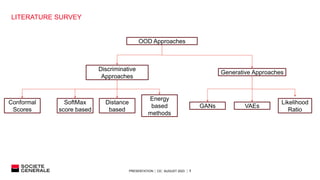
SUMMARY OF LITERATURE SURVEY
Two types of approaches: Discriminative and Generative
Classifier based approaches:
1. OOD inputs tend to have lower Soft-max scores (P(y|x)) than in-distribution data [Hendrycks & Gimpel]
2. High entropy of the predicted class distribution, and therefore a high predictive uncertainty, which suggests that the input may be
OOD.
3. The ODIN method proposed by Liang et al. (2017). ODIN uses temperature scaling (Guo et al., 2017), adds small perturbations to
the input, and applies a threshold to the resulting predicted class to distinguish in- and out-of- distribution inputs. This method is an
improvement over Hendrycks & Gimpel
4. The Mahalanobis distance of the input to the nearest class-conditional Gaussian distribution estimated from the in-distribution data.
Lee et al. (2018) fit class-conditional Gaussian distributions to the activations from the last layer of the neural network.
5. The classifier-based ensemble method that uses the average of the predictions from multiple independently trained models with
random initialization of network parameters and random shuffling of training inputs (Lakshminarayanan et al., 2017).
6. The log-odds of a binary classifier trained to distinguish between in-distribution inputs from all classes as one class and randomly
perturbed in-distribution inputs as the other.
7. The maximum class probability over K in-distribution classes of a (K +1)-class classifier where the additional class is perturbed in-
distribution.
Generative model based approaches
1. Auto-regressive models: PixelCNN (likelihood ratio)
2. VAE
3. GAN](https://image.slidesharecdn.com/oodppt-230829072209-015e3967/85/OOD_PPT-pptx-8-320.jpg)




























![[243] turning data into value](https://cdn.slidesharecdn.com/ss_thumbnails/234turningdataintovalue-150915052705-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
















![7.__Developing_a_Research_Proposal[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/7-260131073037-df92dd7d-thumbnail.jpg?width=640&height=640&fit=bounds)










