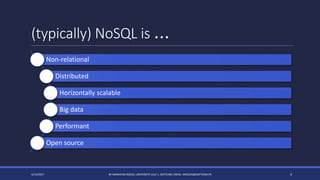
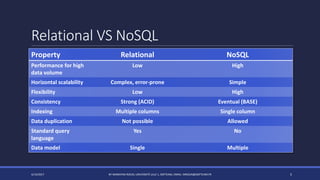
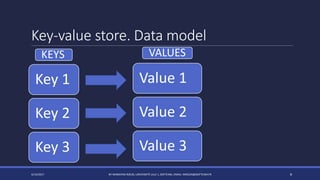
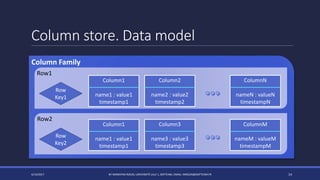
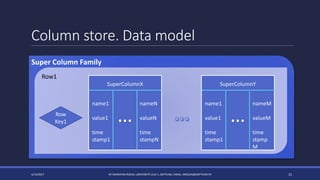
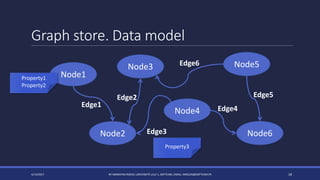
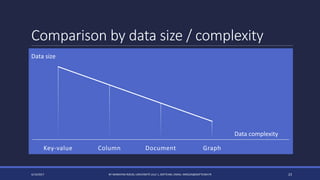
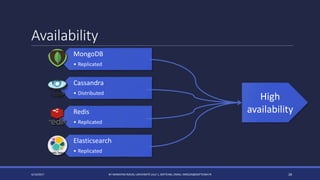
The document discusses NoSQL databases and their advantages over SQL databases. It describes the main NoSQL database models - key-value, document, columnar, and graph - and provides examples of implementations for each. The document also compares some popular NoSQL databases like MongoDB, Cassandra, Redis and Elasticsearch based on factors like data model, consistency, availability, scalability and querying capabilities. Finally, it discusses solutions for working with geospatial data in NoSQL databases.