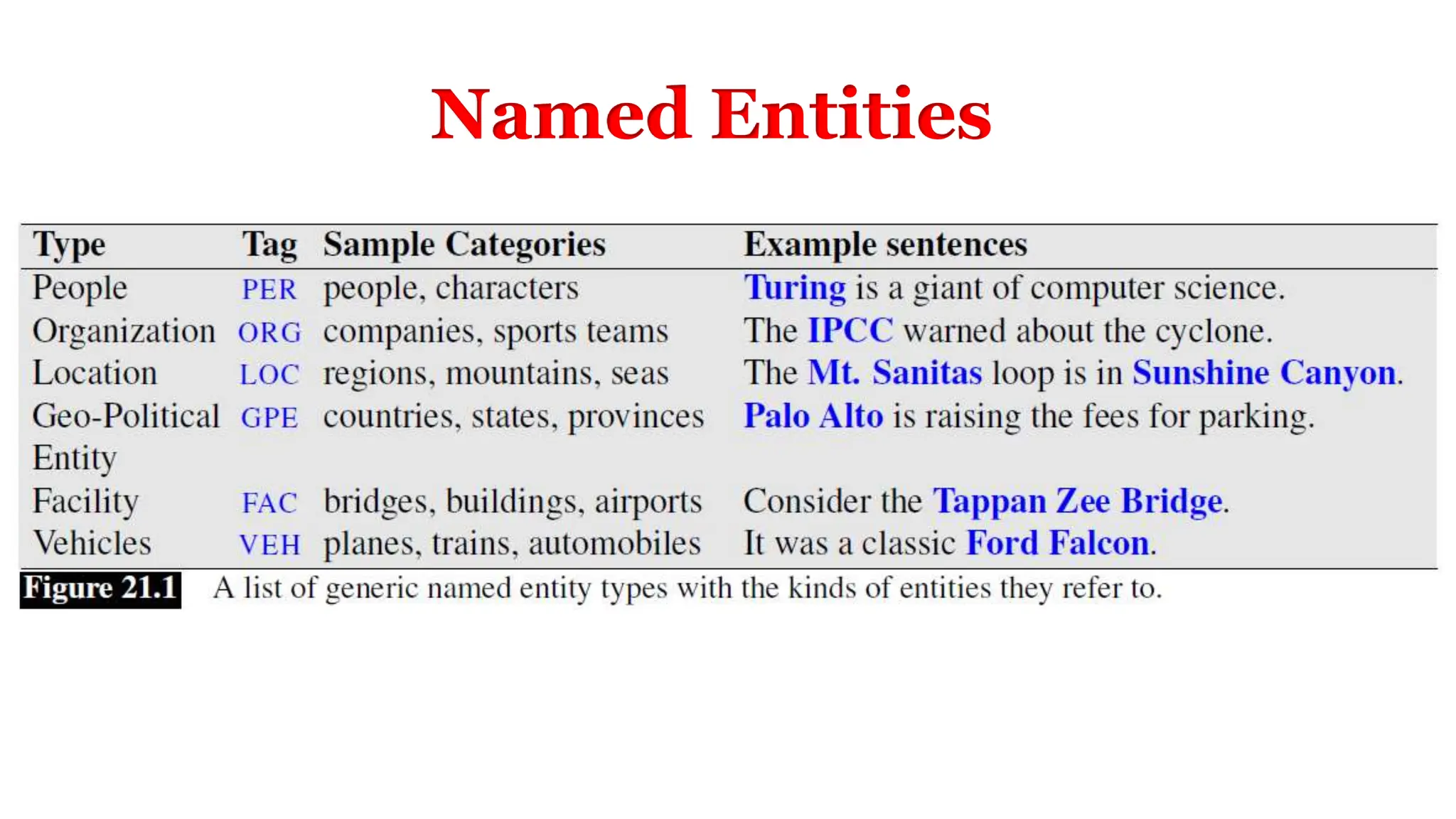
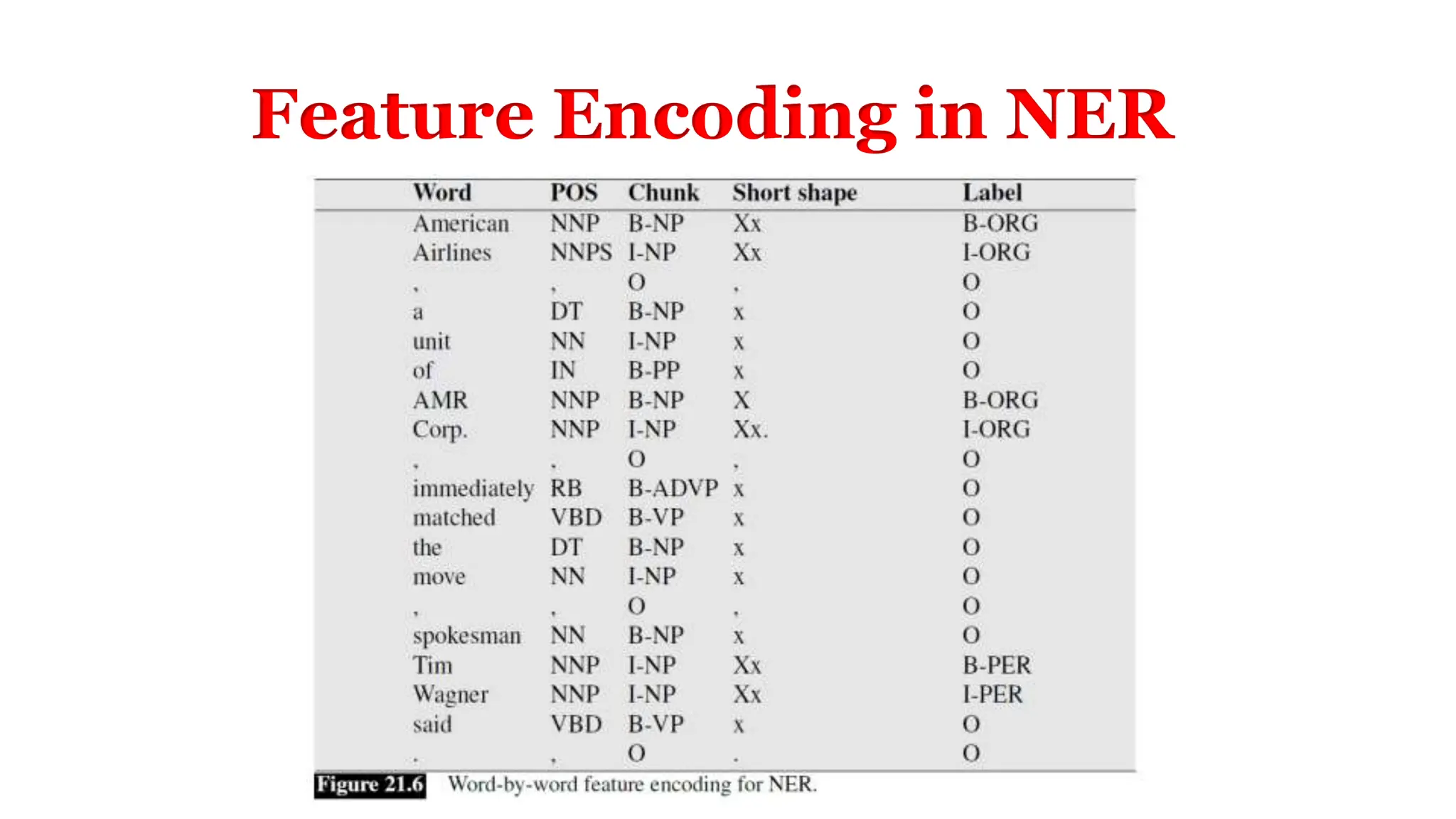
Information extraction involves extracting structured information from unstructured or semi-structured text sources. This includes identifying entities like people, locations, and organizations, as well as times and events. Named entity recognition is the task of identifying entity mentions in text and classifying them into predefined types. It involves segmenting text into entity mentions and then classifying each mention. Features like capitalization, adjacent words, and lists can help with classification.




![Named Entity Recognition (NER)
• Segmentation
– Which words belong to a named entity?
– Brazilian football legend Pele's condition has improved, according to
a Thursday evening statement from a Sao Paulo hospital.
• Classification
– What type of named entity is it?
– Use gazetteers, spelling, adjacent words, etc.
– Brazilian football legend [PERSON Pele]'s condition has improved,
according to a [TIME Thursday evening] statement from a [LOCATION
Sao Paulo] hospital.](https://image.slidesharecdn.com/namedentityrecognitionandinformationextraction-240110122003-f60412fd/75/Named-Entity-Recognition-and-Information-Extraction-pptx-5-2048.jpg)
![NER, Time, and Event extraction
• Brazilian football legend [PERSON Pele]'s condition has
improved, according to a [TIME Thursday evening]
statement from a [LOCATION Sao Paulo] hospital.
• There had been earlier concerns about Pele's health after
[ORG Albert Einstein Hospital] issued a release that said
his condition was "unstable.“
• [TIME Thursday night]'s release said [EVENT Pele was
relocated] to the intensive care unit because a kidney
dialysis machine he needed was in ICU.](https://image.slidesharecdn.com/namedentityrecognitionandinformationextraction-240110122003-f60412fd/75/Named-Entity-Recognition-and-Information-Extraction-pptx-6-2048.jpg)


















![Biomedical example
• Gene labeling
• Sentence:
– [GENE BRCA1] and [GENE BRCA2] are human genes
that produce tumor suppressor proteins](https://image.slidesharecdn.com/namedentityrecognitionandinformationextraction-240110122003-f60412fd/75/Named-Entity-Recognition-and-Information-Extraction-pptx-27-2048.jpg)


![Perl Regular Expressions
^ beginning of string; complement inside []
$ end of string
. any character except newline
* match 0 or more times
+ match 1 or more times
? match 0 or 1 times
| alternatives
( ) grouping and memory
[ ] set of characters
{ } repetition modifier
special symbol](https://image.slidesharecdn.com/namedentityrecognitionandinformationextraction-240110122003-f60412fd/75/Named-Entity-Recognition-and-Information-Extraction-pptx-30-2048.jpg)

![Perl Regular Expressions
t tab
n newline
r carriage return (CR)
* asterisk
? question mark
. period
xhh hexadecimal character
w Matches one alphanumeric (or ‘_’) character
W matches the complement of w
s space, tab, newline
S complement of s
d same as [0-9]
D complement of d
b “word” boundary
B complement of b
[x-y] inclusive range from x to y](https://image.slidesharecdn.com/namedentityrecognitionandinformationextraction-240110122003-f60412fd/75/Named-Entity-Recognition-and-Information-Extraction-pptx-32-2048.jpg)
![Sample Patterns
• Price (e.g., $14,000.00)
– $[0-9,]+(.[0-9]{2})?
• Date (e.g., 2015-02-01)
– ^(19|20)dd[- /.](0[1-9]|1[012])[- /.](0[1-9]|[12][0-9]|3[01])$
• Email
– ^[_a-z0-9-]+(.[_a-z0-9-]+)*@[a-z0-9-]+(.[a-z0-9-]+)*(.[a-z]{2,4})$
• Person
• May include HTML code
• May include POS information
• May include Wordnet information](https://image.slidesharecdn.com/namedentityrecognitionandinformationextraction-240110122003-f60412fd/75/Named-Entity-Recognition-and-Information-Extraction-pptx-33-2048.jpg)





























![[DSC Europe 25] Jovan Bogicevic - Legacy to AI-Driven Defense: Transforming D...](https://cdn.slidesharecdn.com/ss_thumbnails/rsarluadt563hntyfc8q-3-251211083849-3e7bc4c0-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Tatevik Maytesyan - How to actually use AI in marketing: gett...](https://cdn.slidesharecdn.com/ss_thumbnails/tjo626lsqdgfntbgl2mw-4-251216103155-e36cd239-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Miodrag Pesovic & Vladislav Radonjic - Federated Data Archite...](https://cdn.slidesharecdn.com/ss_thumbnails/gsbe3y5it5uhndi4e08e-1-251212103249-f1008e0c-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Bassam Maharmeh - Artificial Intelligence: Opportunities and ...](https://cdn.slidesharecdn.com/ss_thumbnails/thhfmr2fqpawzj7hsjpg-5-251211083048-2c23204f-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Branko Dzakula - From Defense to Attack: How AI Redefines Cyb...](https://cdn.slidesharecdn.com/ss_thumbnails/80bdzdxpr3ky2g0qvyk9-8-251211083048-ce5fc1ee-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Ivan Peric - Intelligence Swarm Logic and Techno-Functional M...](https://cdn.slidesharecdn.com/ss_thumbnails/7my7c97fsduiccadgavw-2-251212103249-5a03f7c6-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Uros Pesic - The Reality of AI in Marketing.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/rtkodnmtycovsllvzsyn-9-251215095918-b0c6bfe3-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Dunja Adzic Jovanovic - AI and Cybersecurity: Defending Data ...](https://cdn.slidesharecdn.com/ss_thumbnails/o1zylpbhrtwnixxq2xj8-7-251211083048-185086f6-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Behzad Hosseini - AI Agents in the Wild: Deploying Models tha...](https://cdn.slidesharecdn.com/ss_thumbnails/3qtejajvsjqrzwfept2c-10-251212103250-7f2b1068-thumbnail.jpg?width=640&height=640&fit=bounds)
