This document presents the estimation of parameters in a spatial regressive-autoregressive model using Ord's eigenvalue method, detailing the statistical background and methodologies implemented in R. It reviews global spatial regression models, weight matrices for spatial interactions, and demonstrates the application of the method to Columbus, Ohio crime data from 1980. The work includes theoretical foundations, mathematical formulations, and practical examples of spatial regression analysis.



![The Models of Whittle, Bartlett, and Besag (cont.)
Bartlett (1966, 1971) and Besag (1972) considered the following conditional model:
E[Yi | Yj = yj , j ∈ J(i) ] = α + ρ
k∈J(i)
wik yk (i = 1, . . . , n). (2)
The following lemma shows the relationship between models (1) and (2):
Lemma
(a) If equations (1) and (2) hold, then
E[εi | Yj = yj , j ∈ J(i)] = 0 (i = 1, . . . , n). (3)
(b) If equations (1) and (3) hold, then equation (2) holds as well.
Sajib Tonmoy (UNLV) Global spatial regression M.S. thesis defense, 2018 4 / 42](https://image.slidesharecdn.com/mypresentationslides3-181129192659/85/My-presentation-slides-3-4-320.jpg)










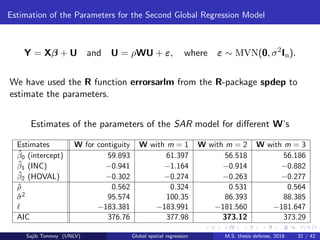
![Equations for the MLEs of the Parameters in a Global Spatial Regression Model
Theorem
Assume ε ∼ MVN(0, σ2I) and Y = Xβ + ρWY + ε. Then the MLEs of
the parameters β, σ2, and ρ satisfy the following equations:
ˆβ = (X X)−1
X (I − ˆρW)y,
ˆσ2 =
1
n
y (I − ˆρW) (I − H)(I − ˆρW)y,
and − ˆσ2
Tr[(I − ˆρW)−1
W] + y Wy − ˆρ y W Wy − ˆβ X Wy = 0.
Here, I − H is symmetric and idempotent, where H = X(X X)−1X is
the usual hat matrix in linear regression.
Sajib Tonmoy (UNLV) Global spatial regression M.S. thesis defense, 2018 16 / 42](https://image.slidesharecdn.com/mypresentationslides3-181129192659/85/My-presentation-slides-3-16-320.jpg)
![Properties of the Determinant of the Matrix I − ρW
Lemma
If W has (possibly complex) eigenvalues λ1, λ2, . . . , λn, then
det(I − ρW) =
n
i=1
(1 − ρλi ),
and
∂ ln det(I − ρW)
∂ρ
= Tr[(I − ρW)−1
W] = −
n
i=1
λi
1 − ρλi
.
The first equality of the second equation follows from Jacobi’s formula
for the derivative of the determinant of a square matrix.
Sajib Tonmoy (UNLV) Global spatial regression M.S. thesis defense, 2018 17 / 42](https://image.slidesharecdn.com/mypresentationslides3-181129192659/85/My-presentation-slides-3-17-320.jpg)
![Equation for the MLE of ρ
Theorem
Assume ε ∼ MVN(0, σ2
I) and Y = Xβ + ρWY + ε. The MLE of the parameter
ρ satisfies the following equation:
−
ˆρ2
n
[h1
n
i=1
λi
1 − ˆρλi
] + ˆρ [−h1 +
2h2
n
n
i=1
λi
1 − ˆρλi
] + [h2 −
h3
n
n
i=1
λi
1 − ˆρλi
] = 0,
where λ1, . . . , λn are the eigenvalues of W and
h1 = y [W (I − H)W]y;
h2 = y [W (I − H)]y;
h3 = y (I − H)y.
To find a solution for ˆρ from the above equation, we used the R function
uniroot.
Sajib Tonmoy (UNLV) Global spatial regression M.S. thesis defense, 2018 18 / 42](https://image.slidesharecdn.com/mypresentationslides3-181129192659/85/My-presentation-slides-3-18-320.jpg)
![Log-likelihood Equation
Remark
For the mixed regressive-autoregressive model, the log-likelihood equation has the
following form:
(β, σ2
, ρ; y) = ln (det(I − ρW)) −
n
2
ln(2πσ2
)
−
1
2σ2
[y (I − ρW) (I − ρW)y − 2β X (I − ρW)y + β X Xβ].
Sajib Tonmoy (UNLV) Global spatial regression M.S. thesis defense, 2018 19 / 42](https://image.slidesharecdn.com/mypresentationslides3-181129192659/85/My-presentation-slides-3-19-320.jpg)