Download to read offline
































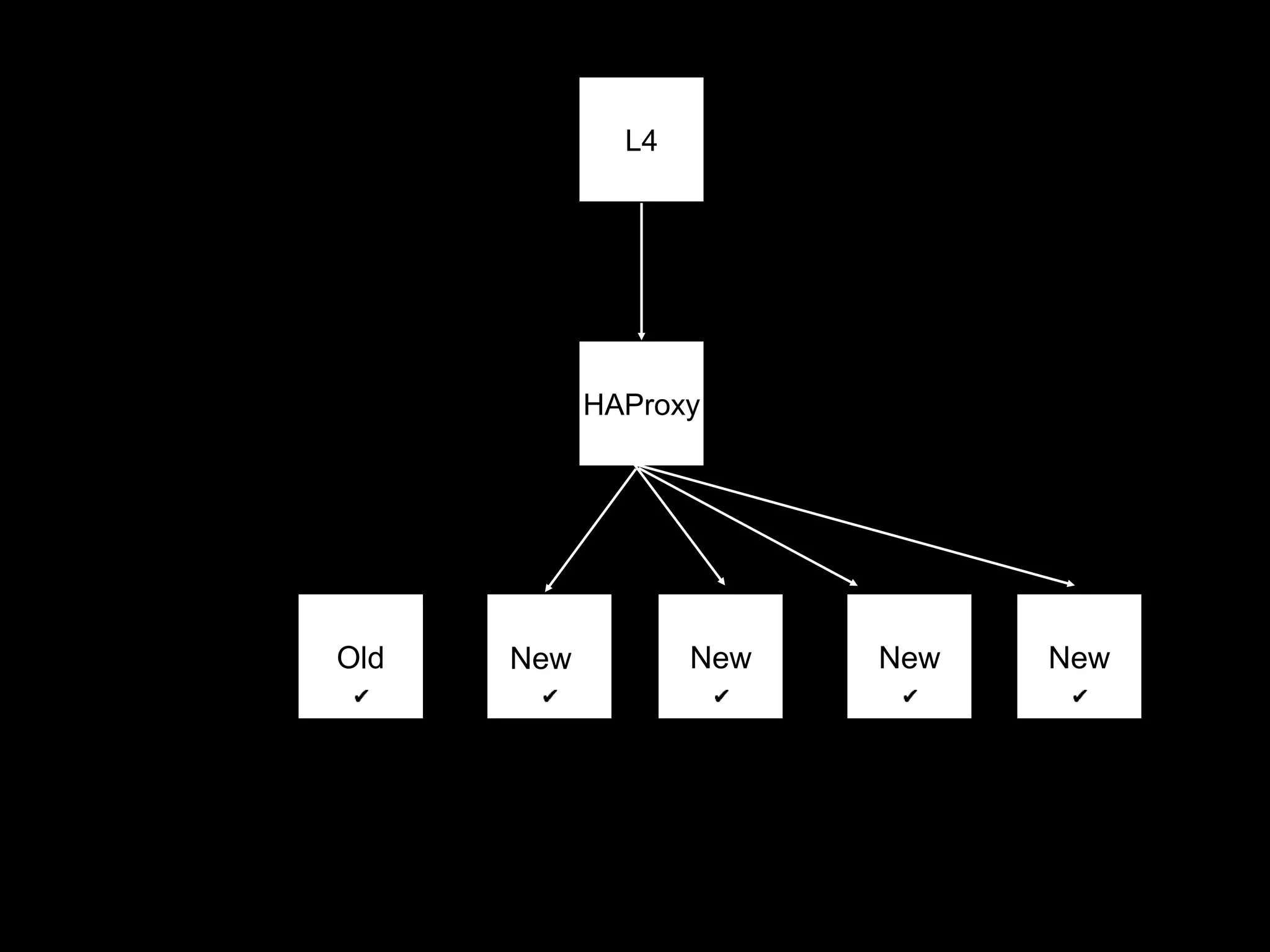









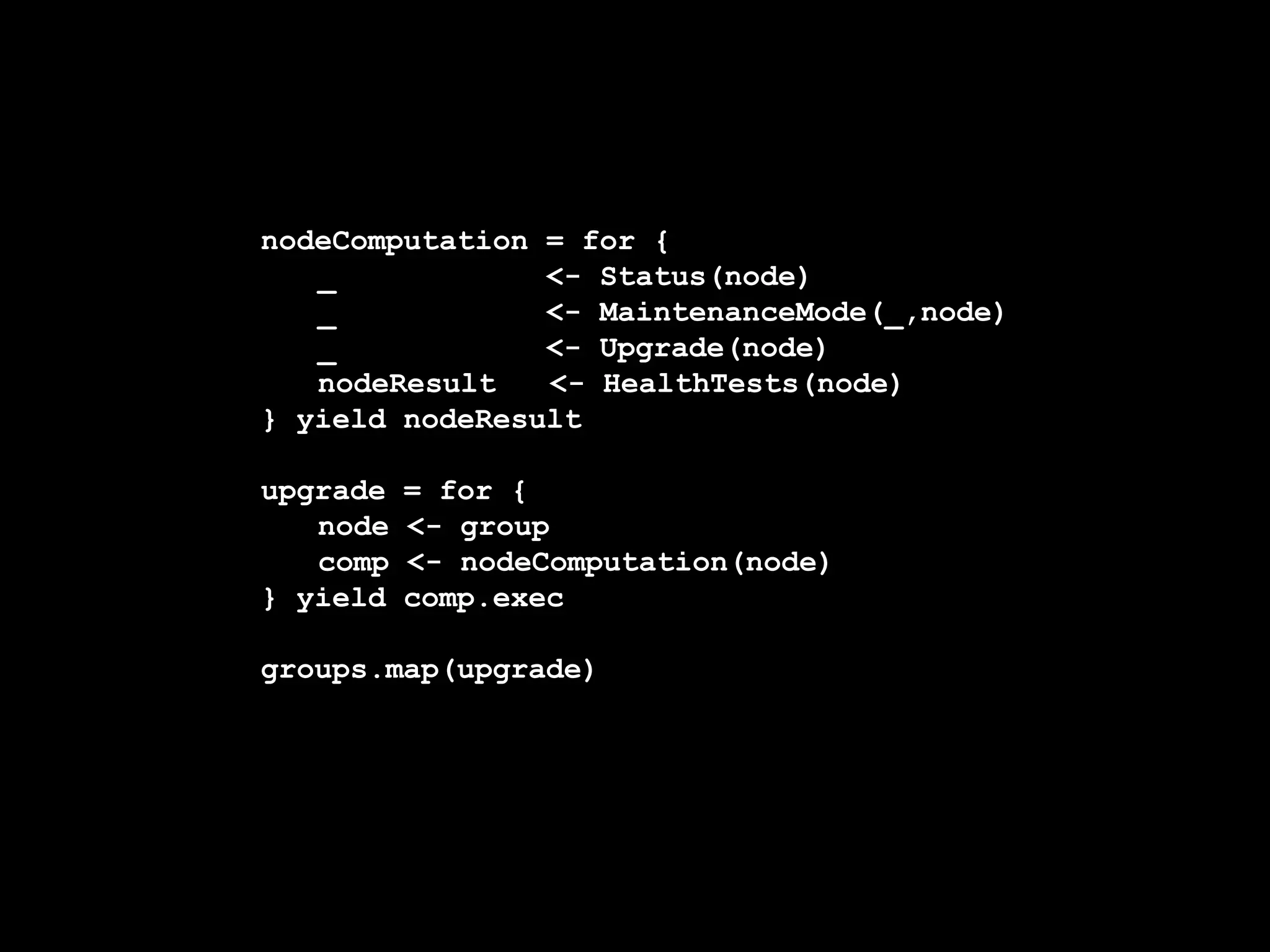
![for node in nodes:
if info[node]['instance']:
if Status(node).run().wait() == AVAILBLE_FOR_MAINTENANCE:
MaintenanceMode(node).run().wait()
Upgrade(node).run().wait()
Health = HealthTests(node).run.wait()
UpdateStatus(node, health).run.wait()](https://image.slidesharecdn.com/movingforward02-160922235826/75/Moving-forward-under-the-weight-of-all-that-state-61-2048.jpg)
![all_good = True
host = self.cdh.get_host(self.host_map[self.node_name])
if host.healthSummary != 'GOOD':
all_good = False
# Look up the host by its roles
for c in self.cdh.get_all_clusters():
for s in c.get_all_services():
for r in s.get_all_roles():
h = r.hostRef
if h.hostId == self.host_map[self.node_name]:
if r.healthSummary != 'GOOD':
all_good = False
return all_good](https://image.slidesharecdn.com/movingforward02-160922235826/75/Moving-forward-under-the-weight-of-all-that-state-62-2048.jpg)
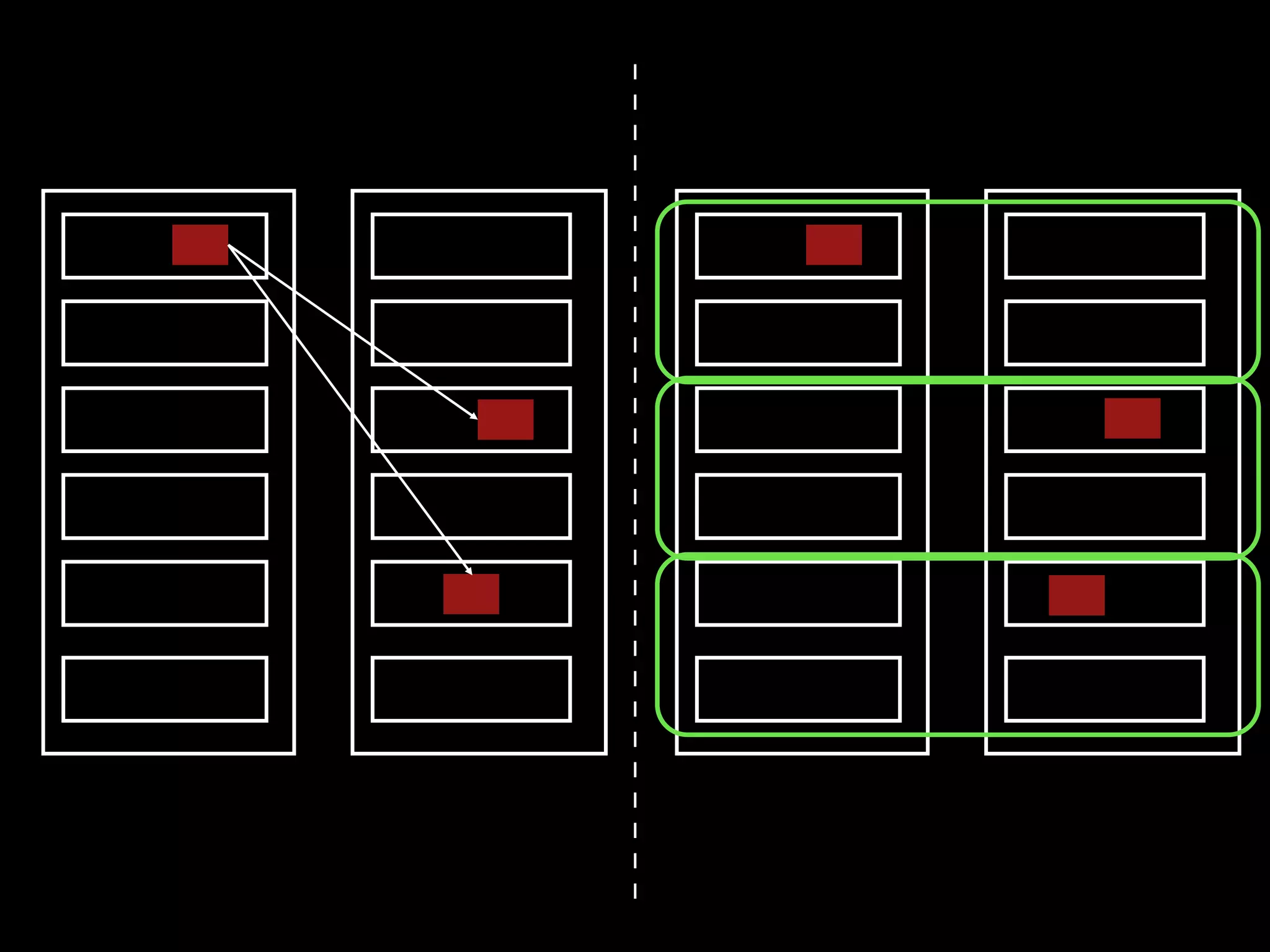
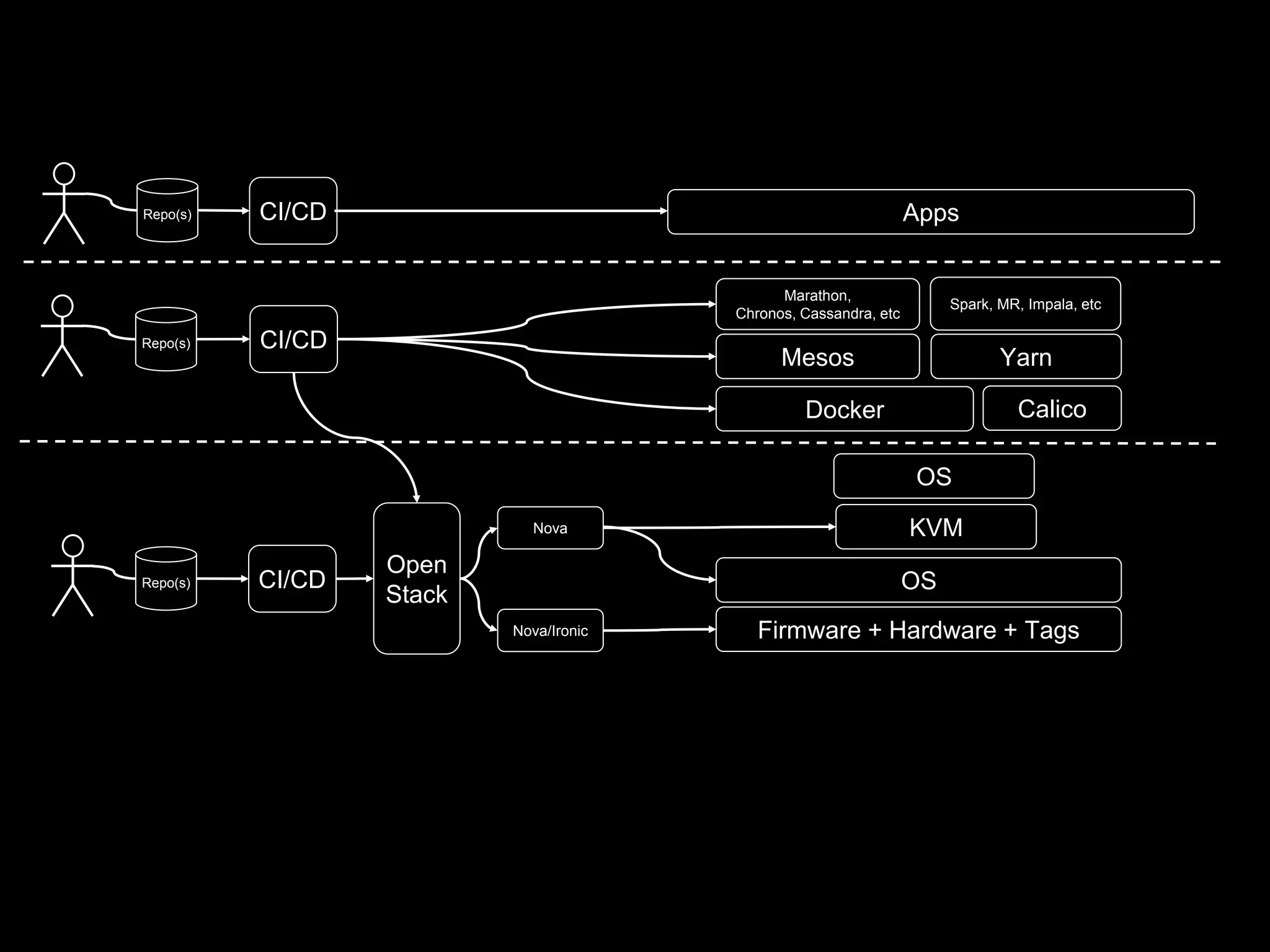

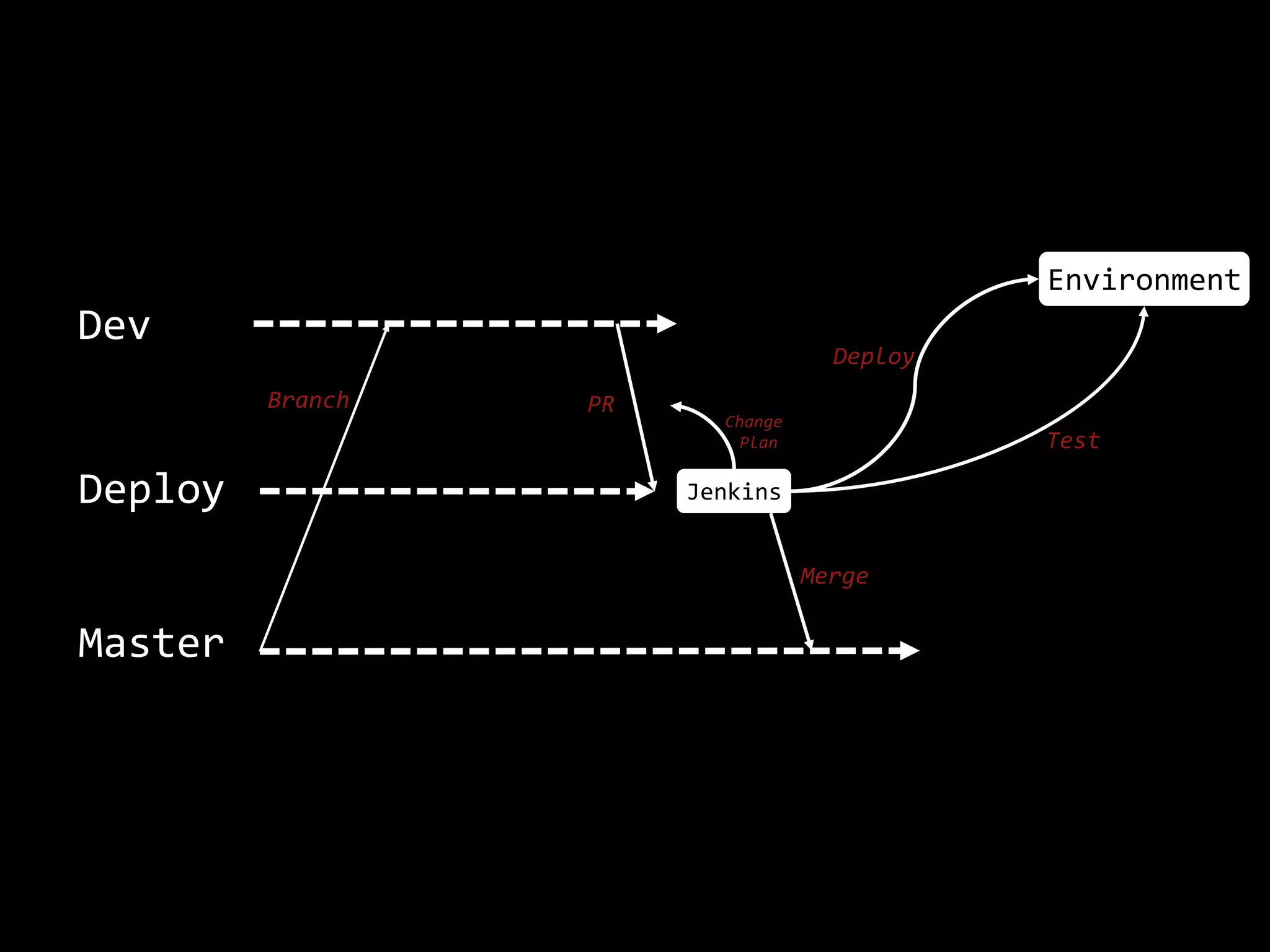








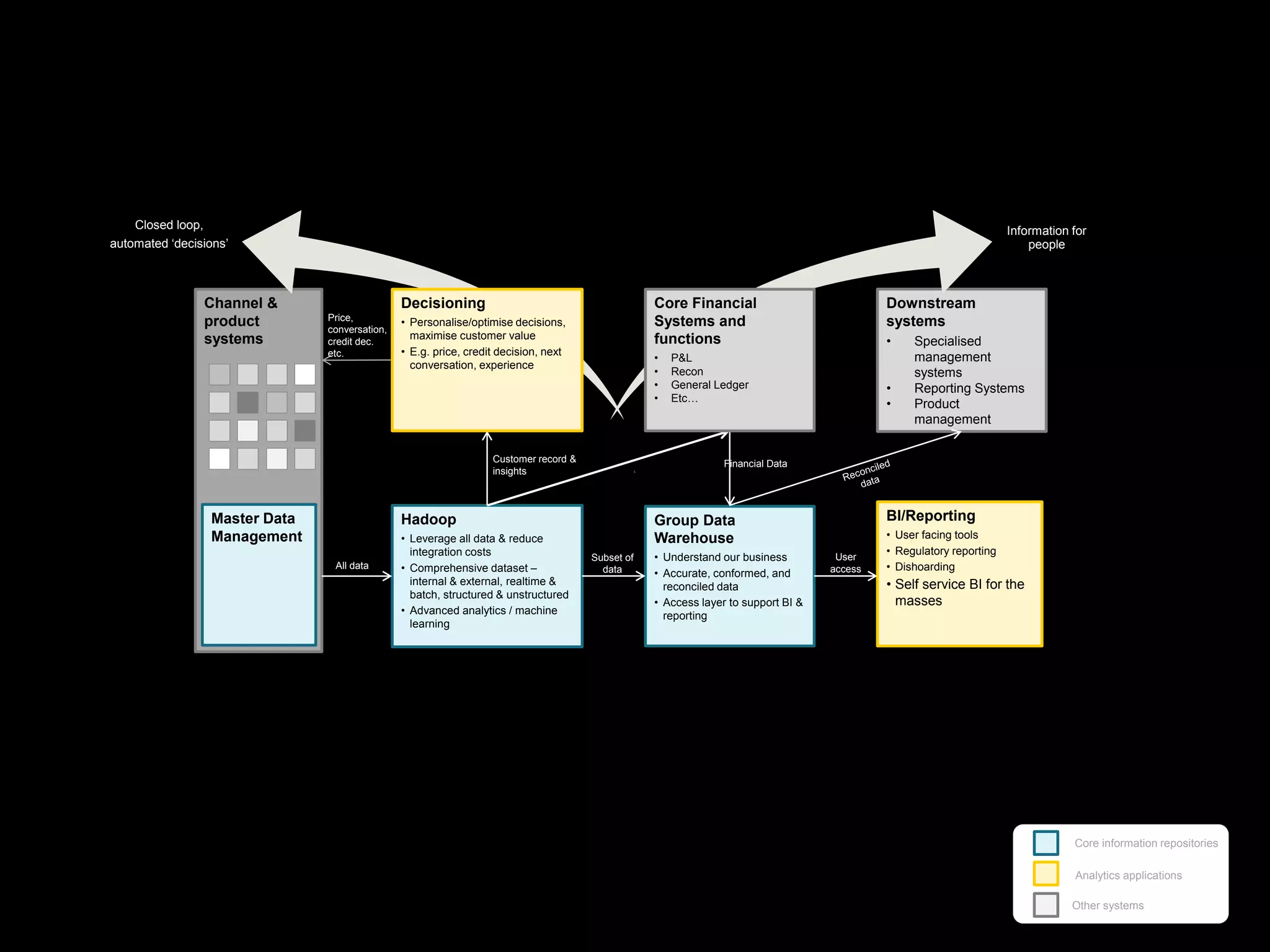
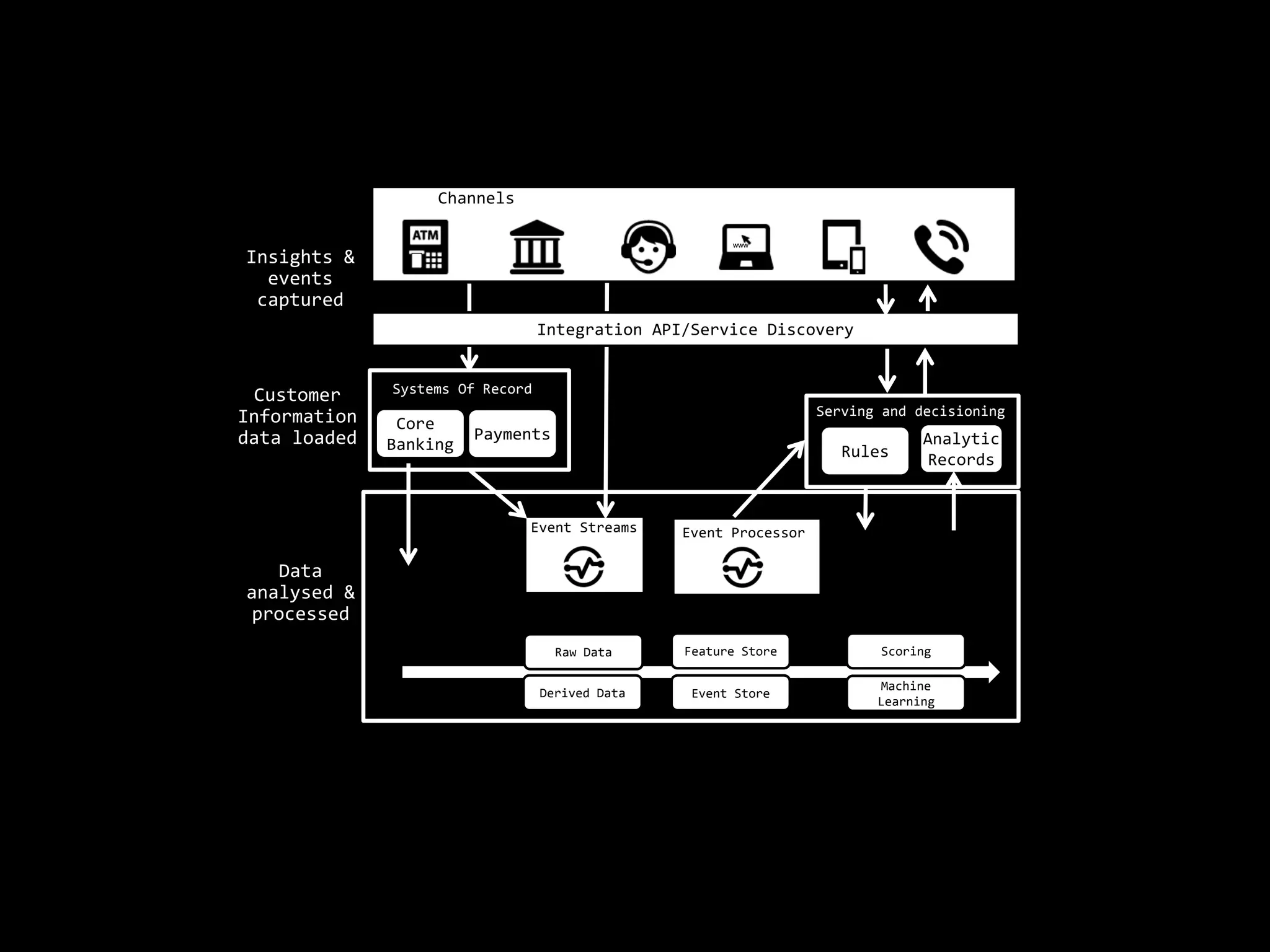
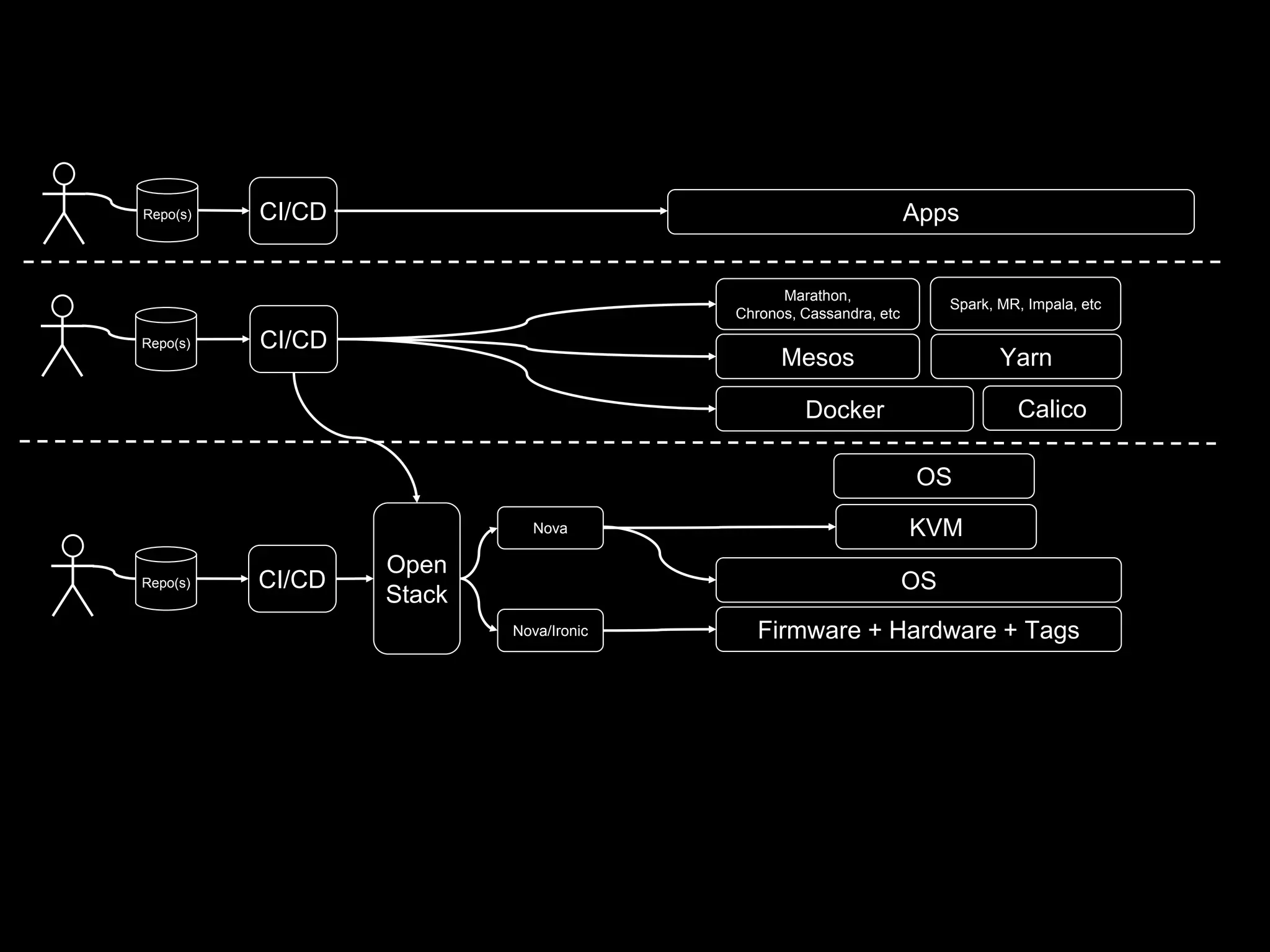
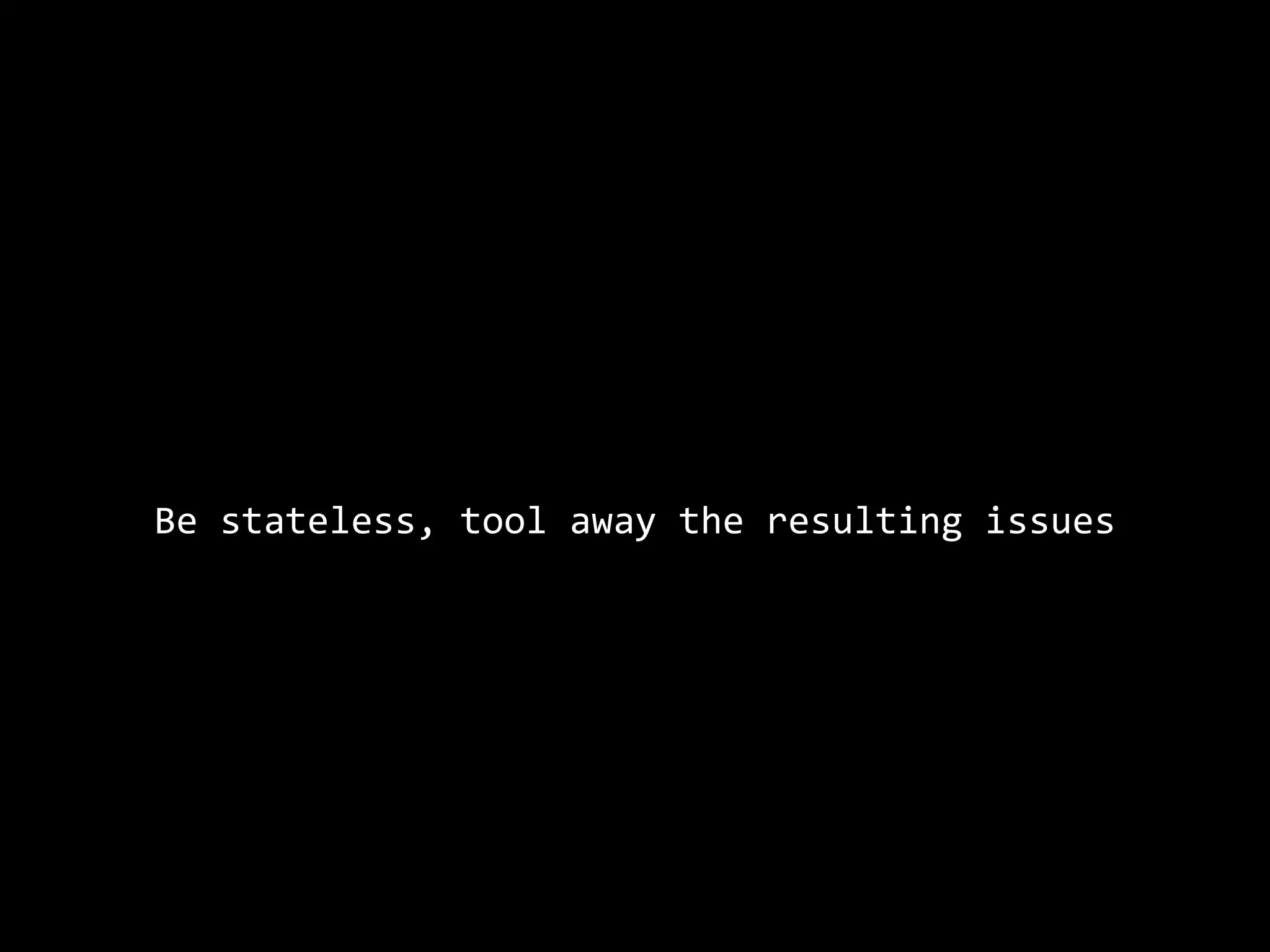
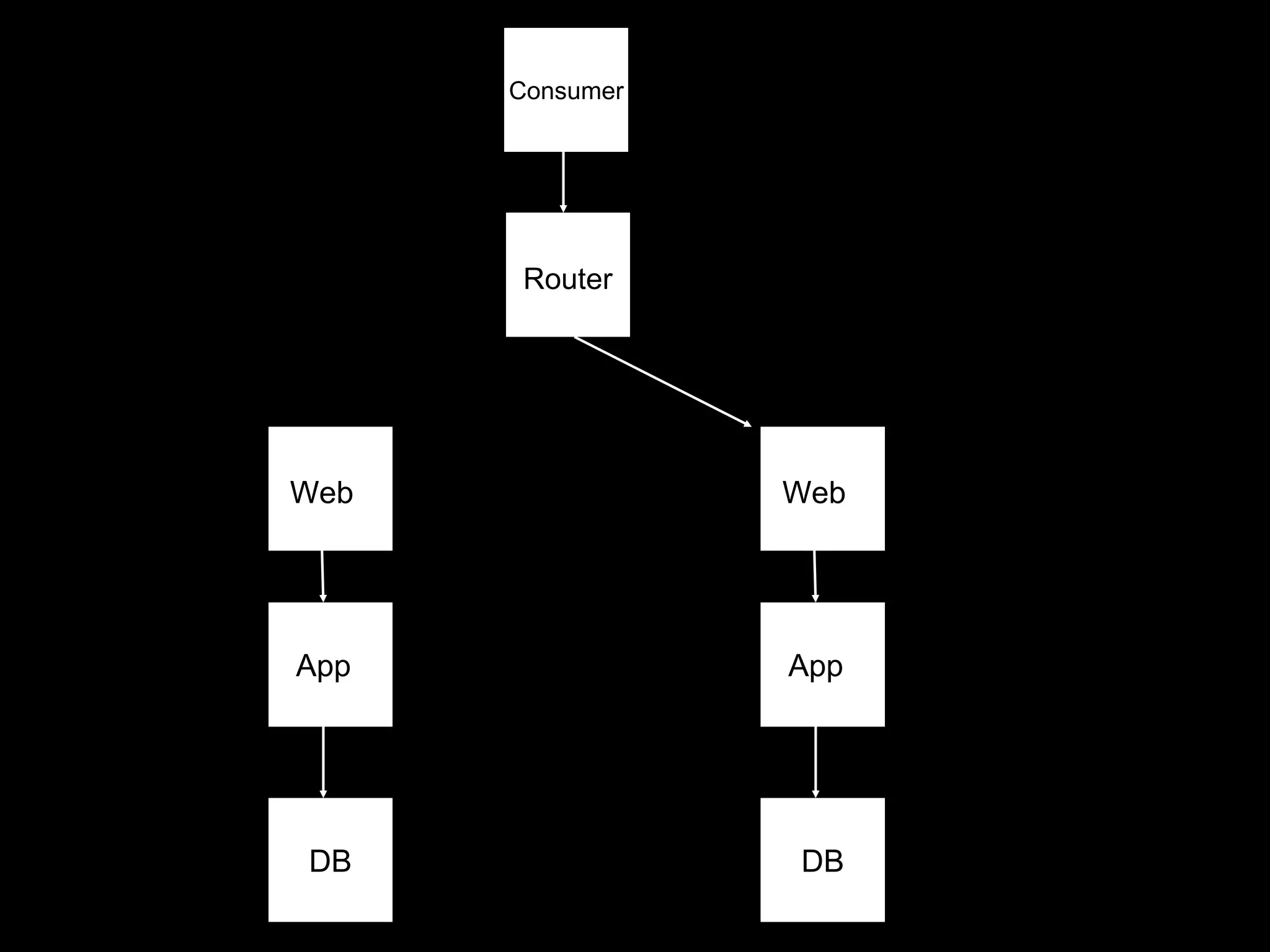
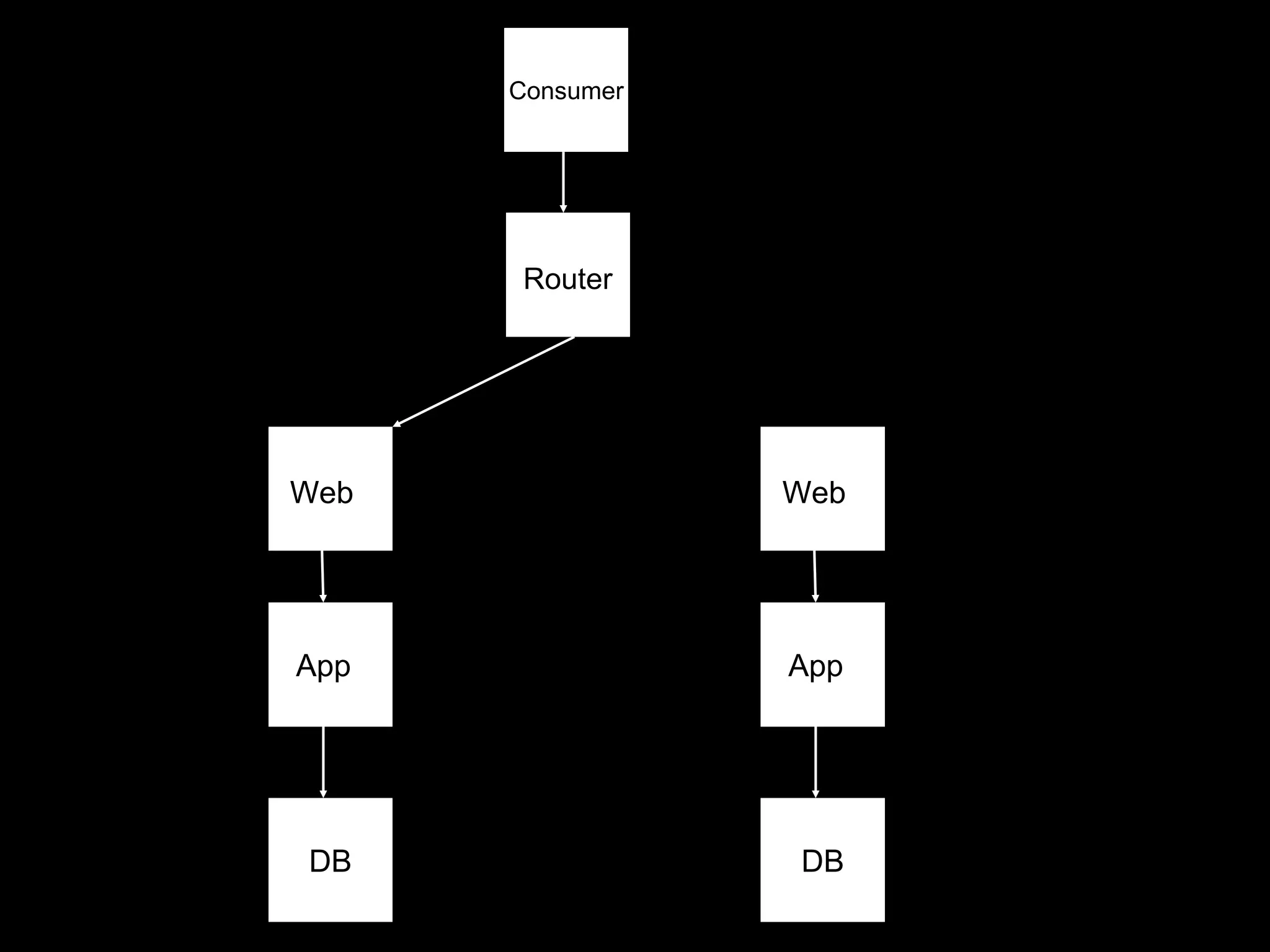
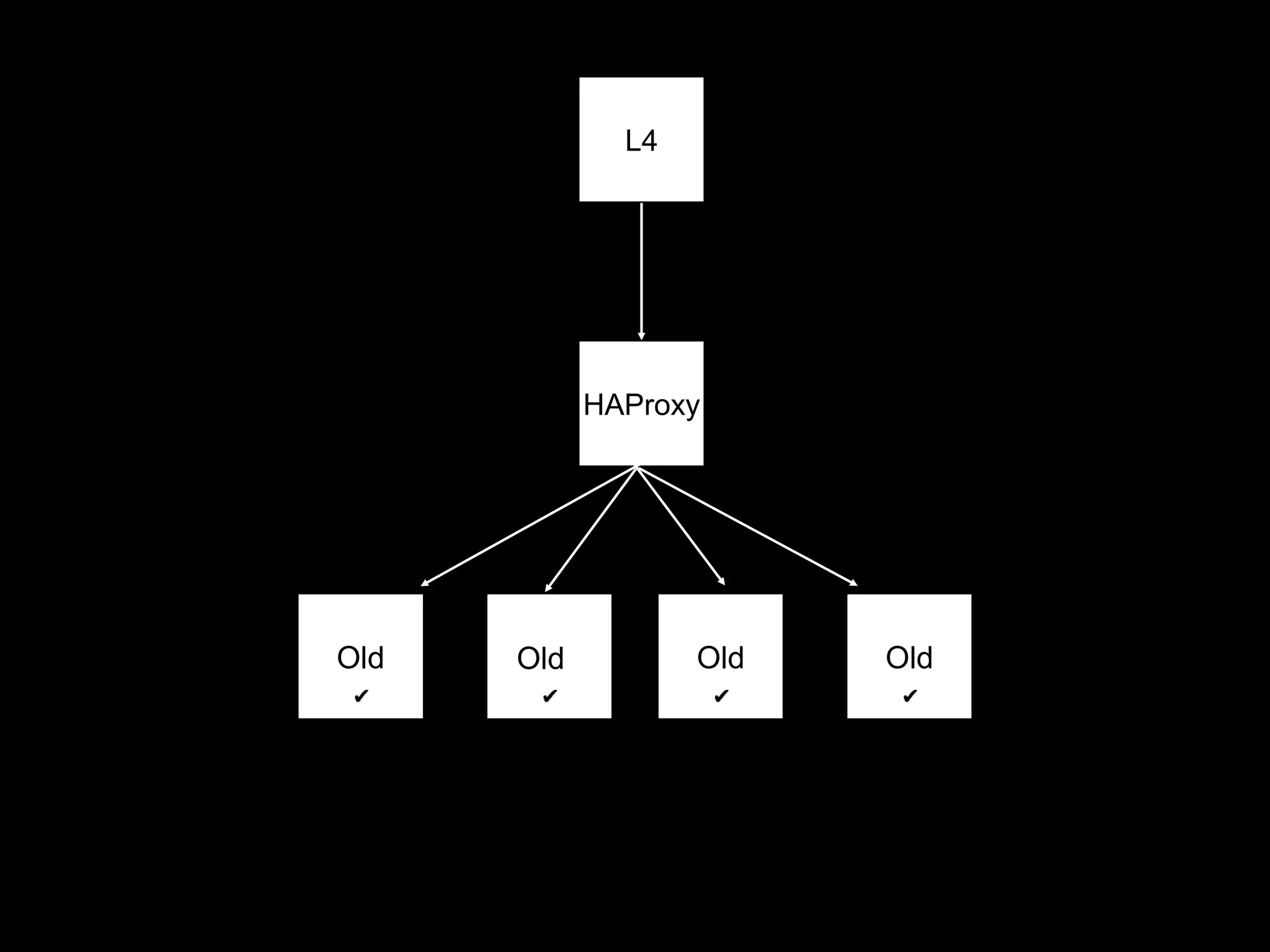
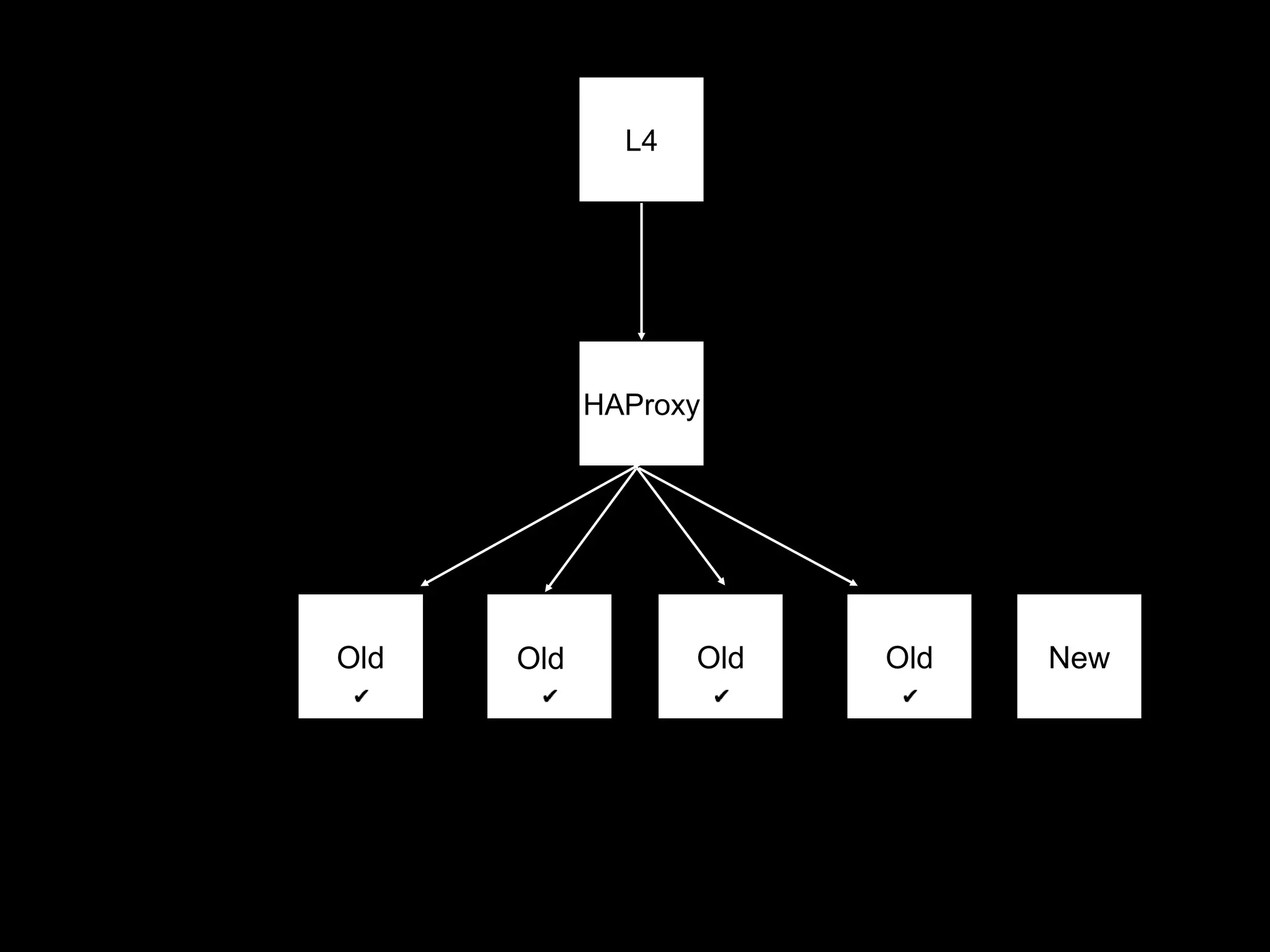
The document focuses on enhancing data management through advanced analytics and machine learning, outlining a comprehensive architecture that integrates various systems and datasets. It emphasizes the importance of accurate data access for business intelligence, regulatory reporting, and automated decision-making processes. Additionally, it discusses the complexities of system architecture, recommending strategies for incremental optimization and manual intervention in deployment and provisioning processes.


































































