Download as PDF, PPTX



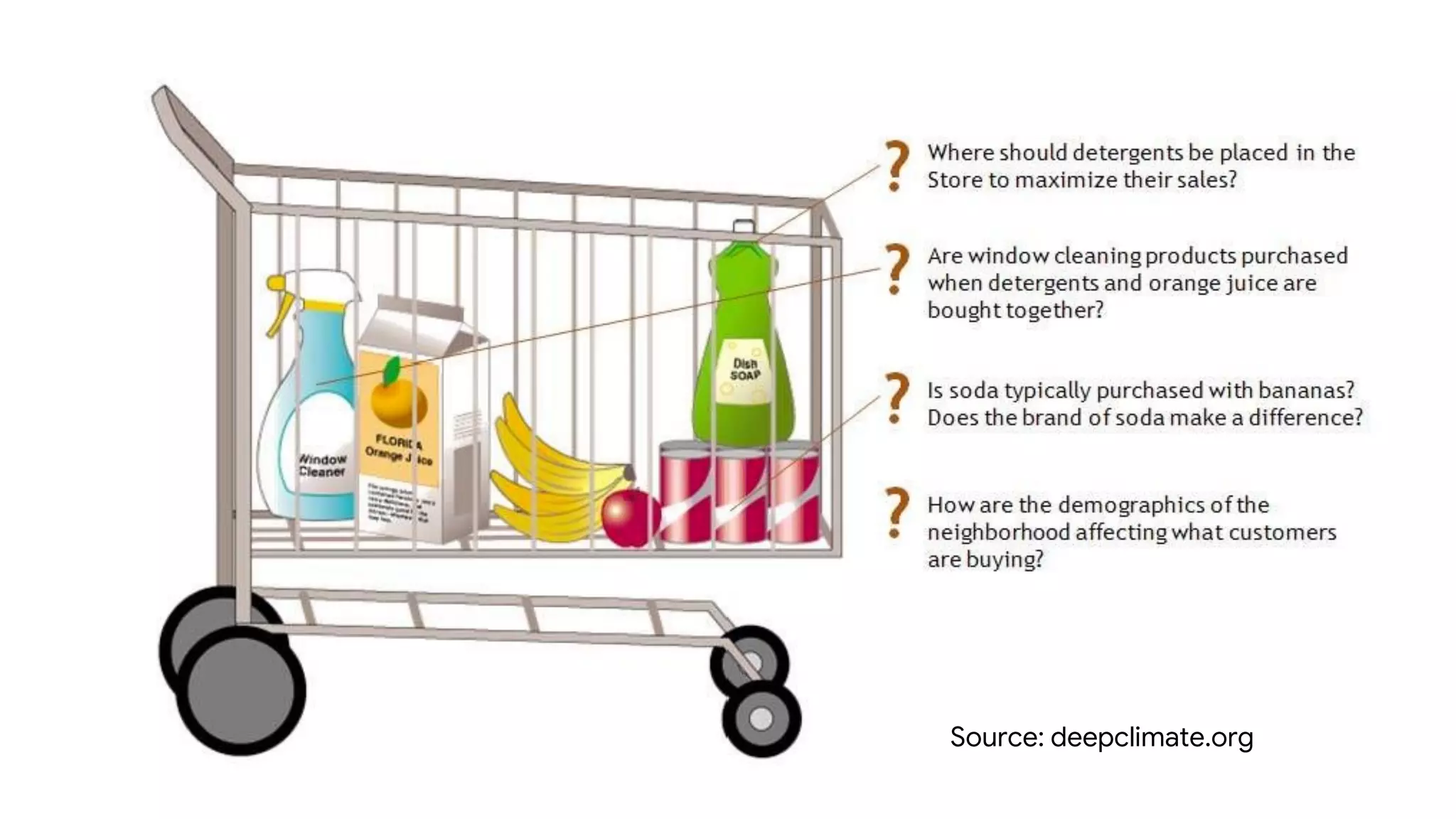




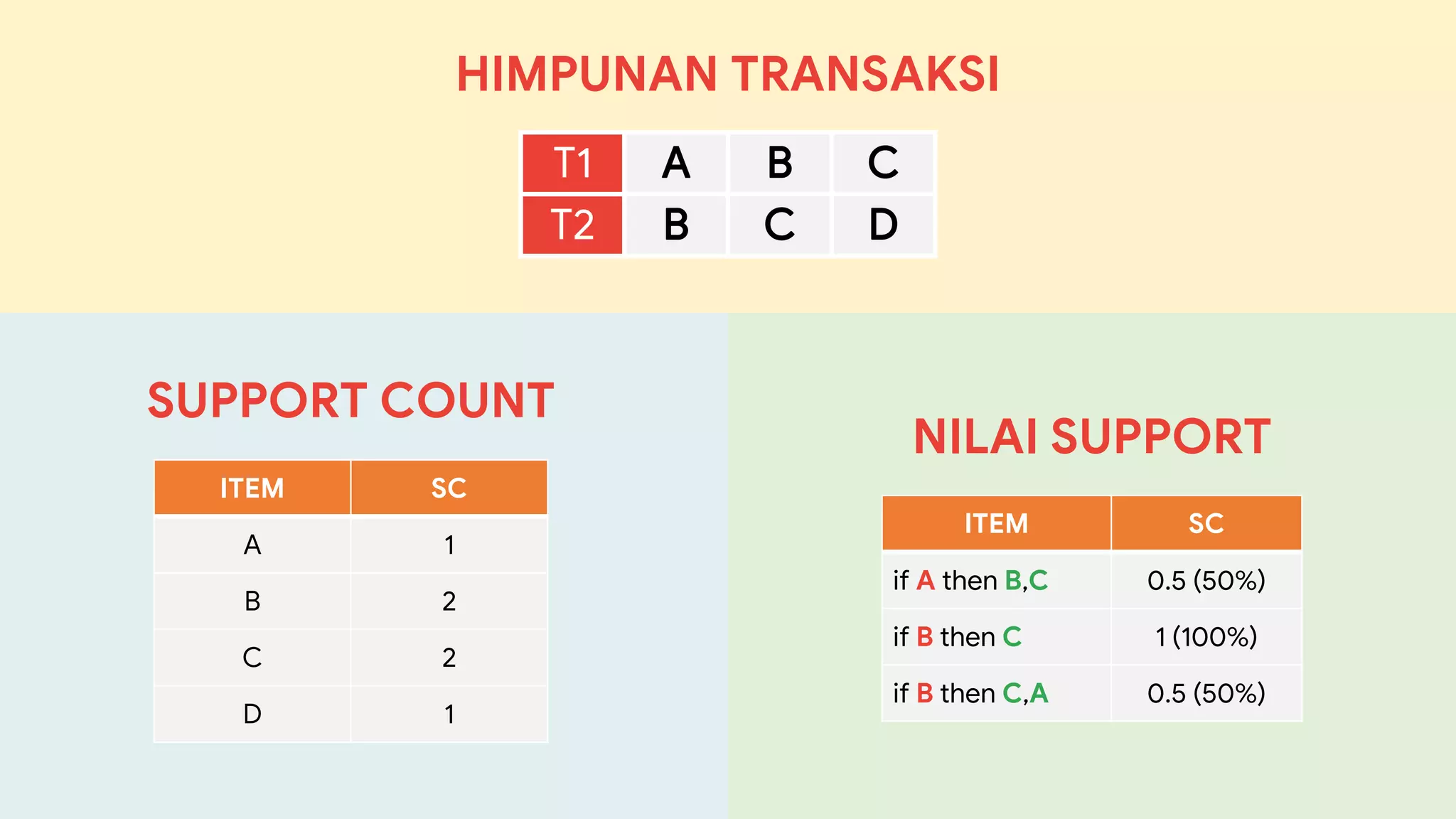







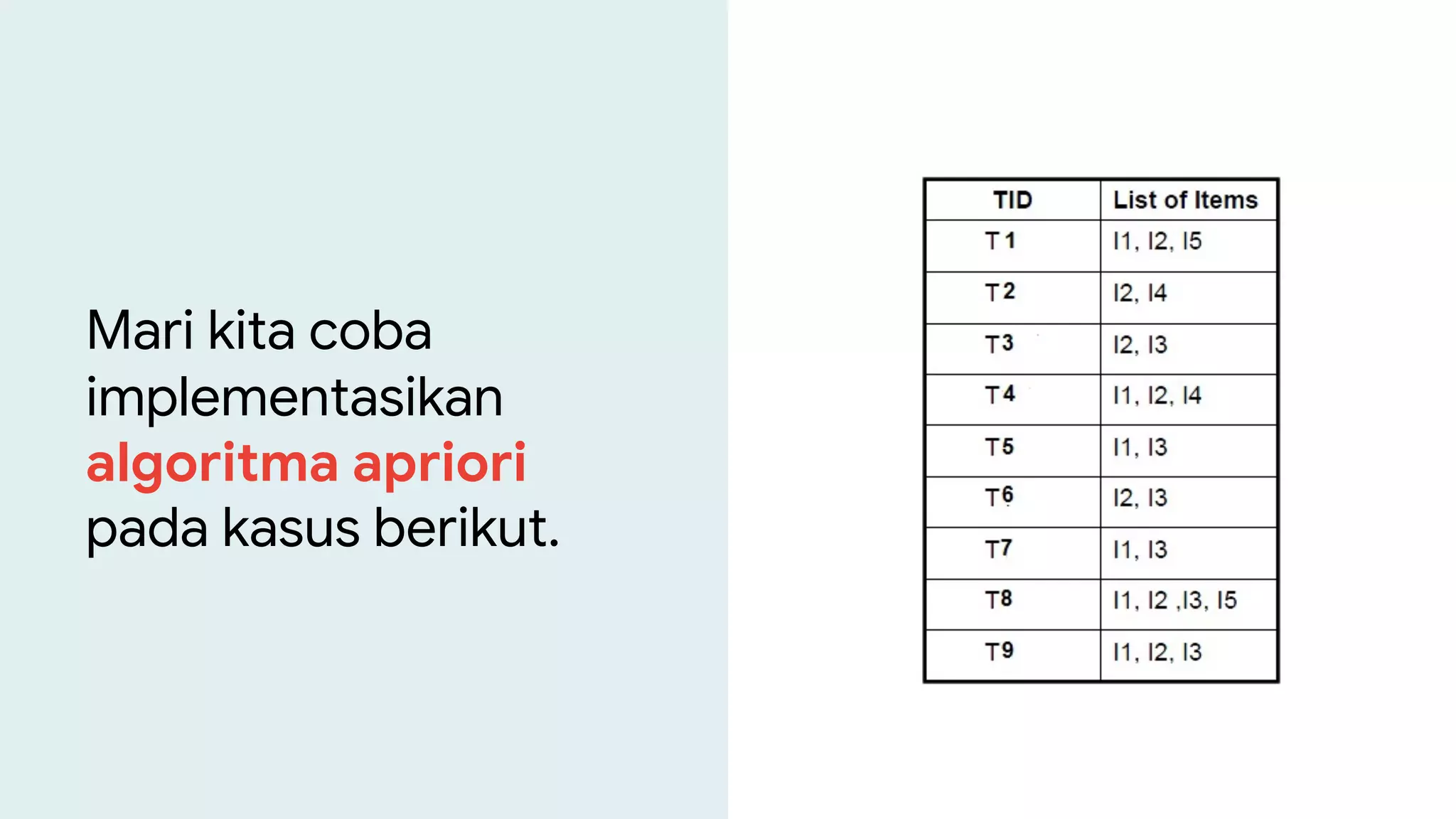





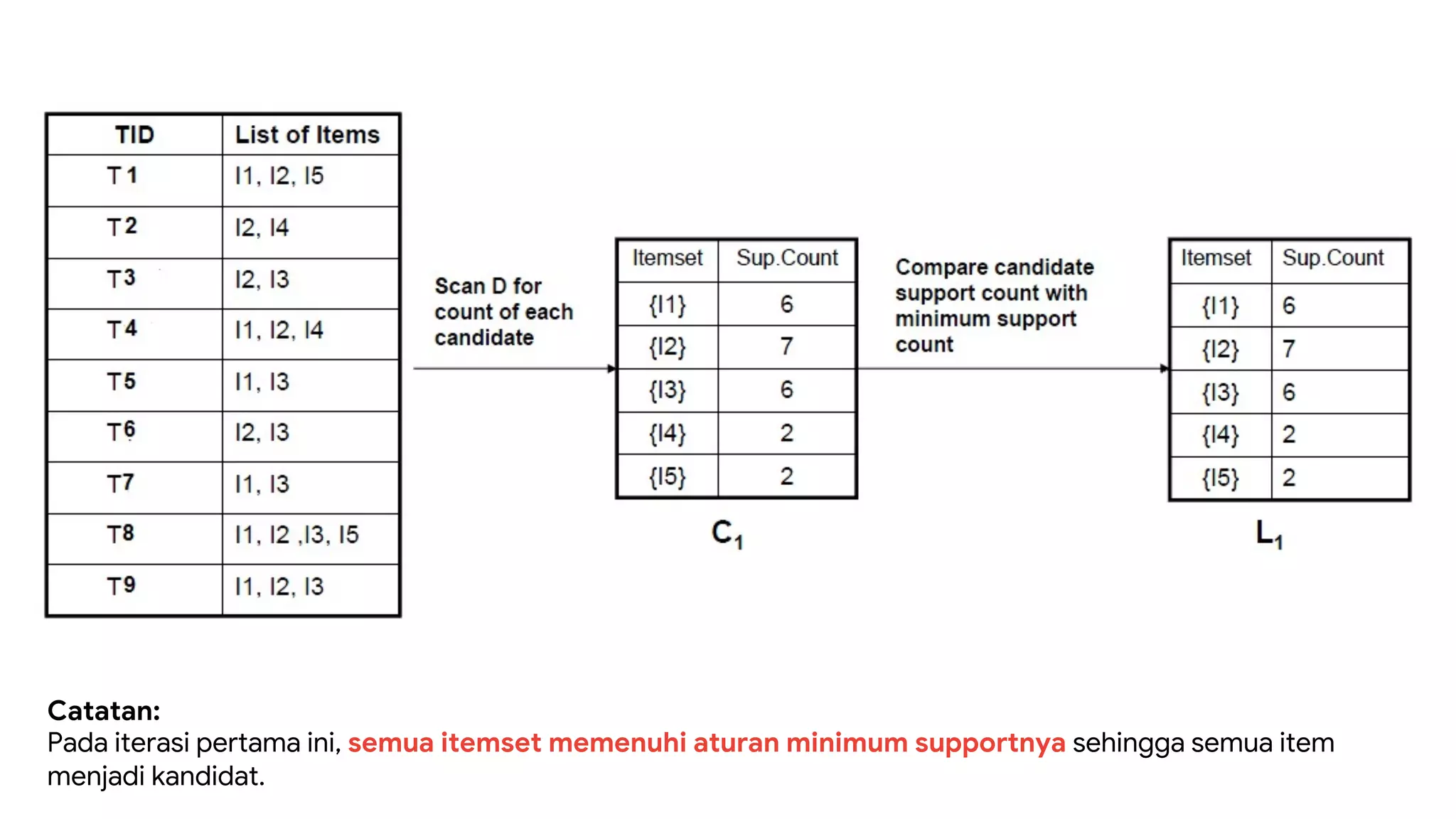

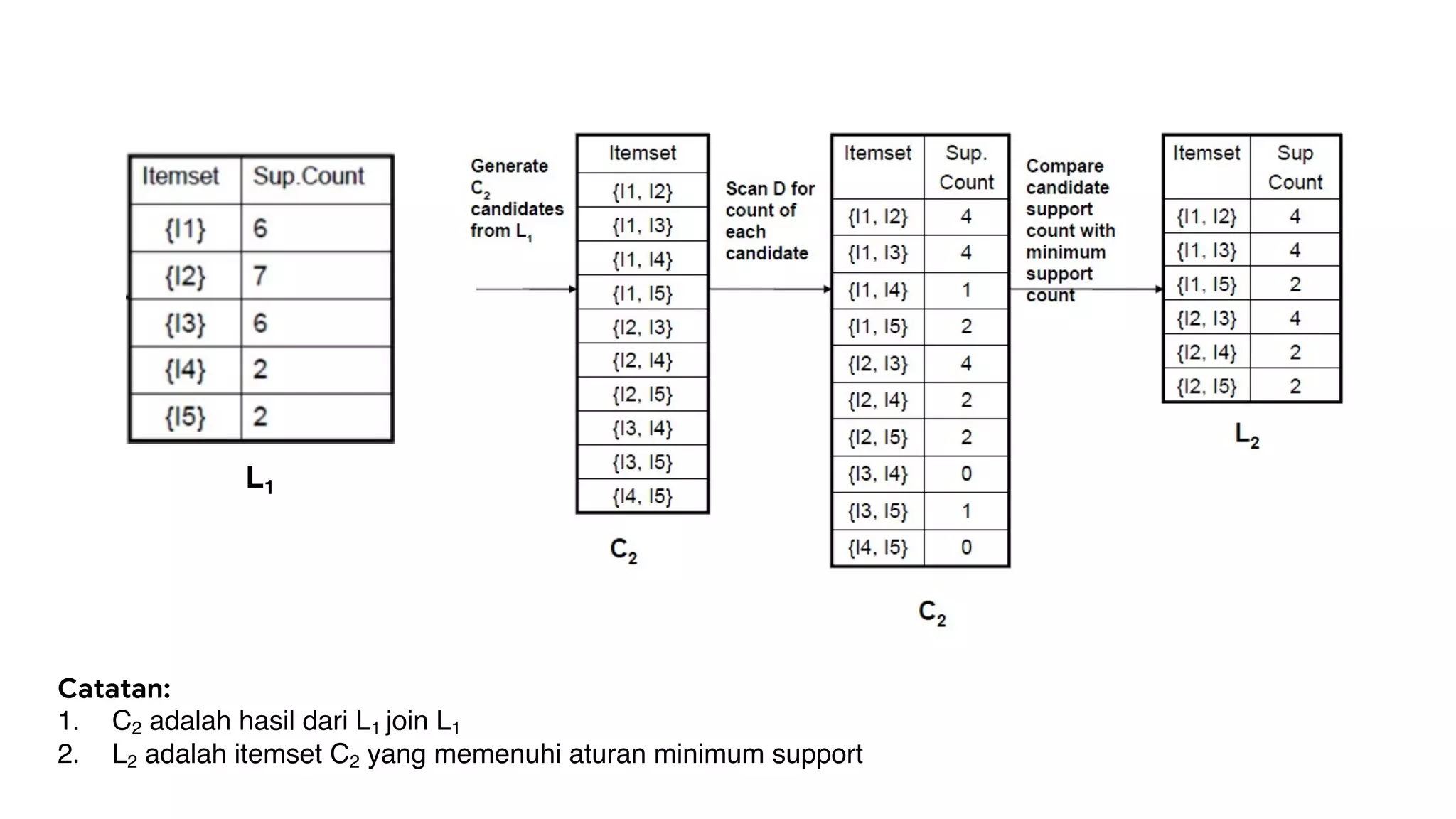

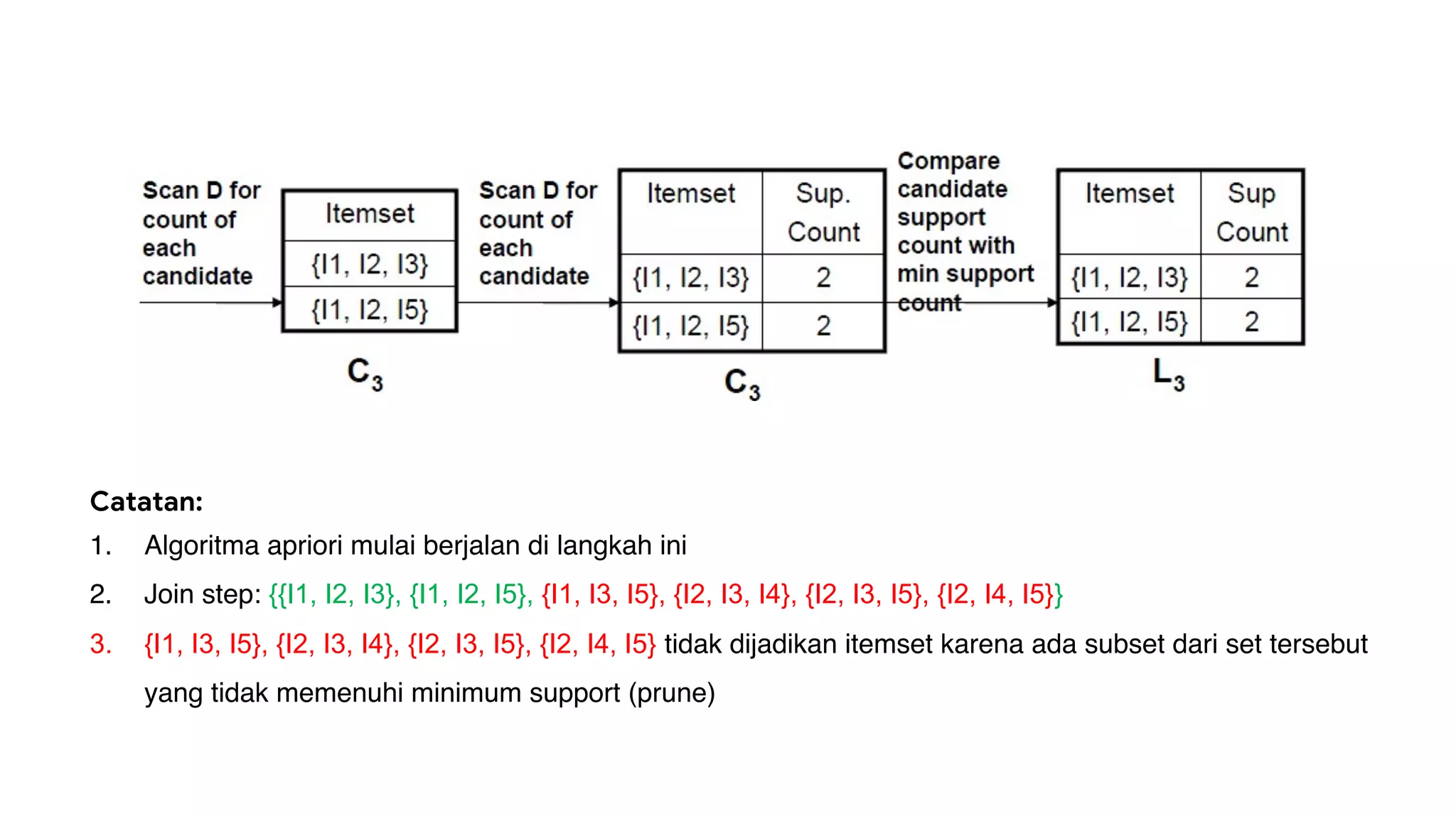










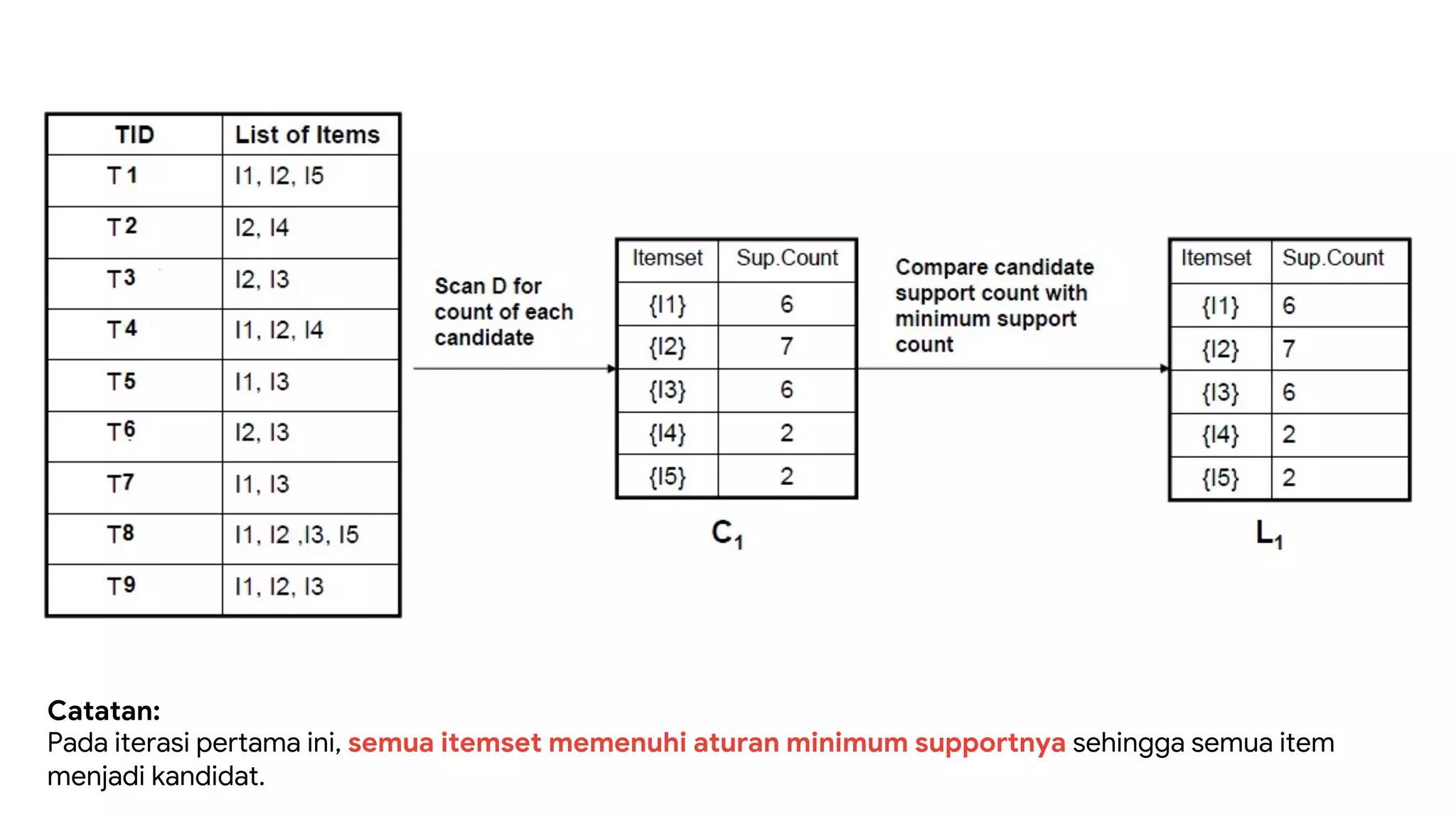



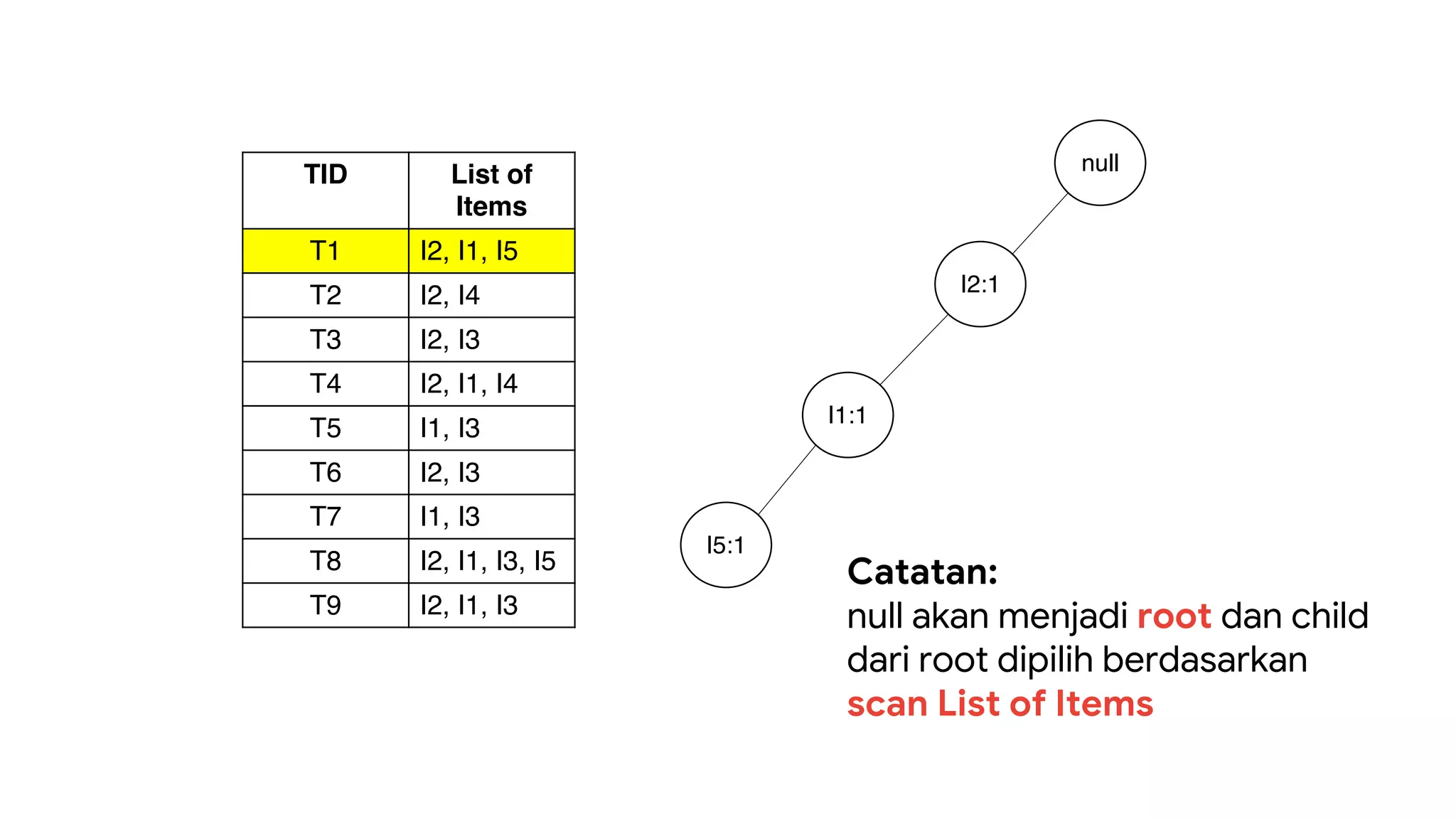
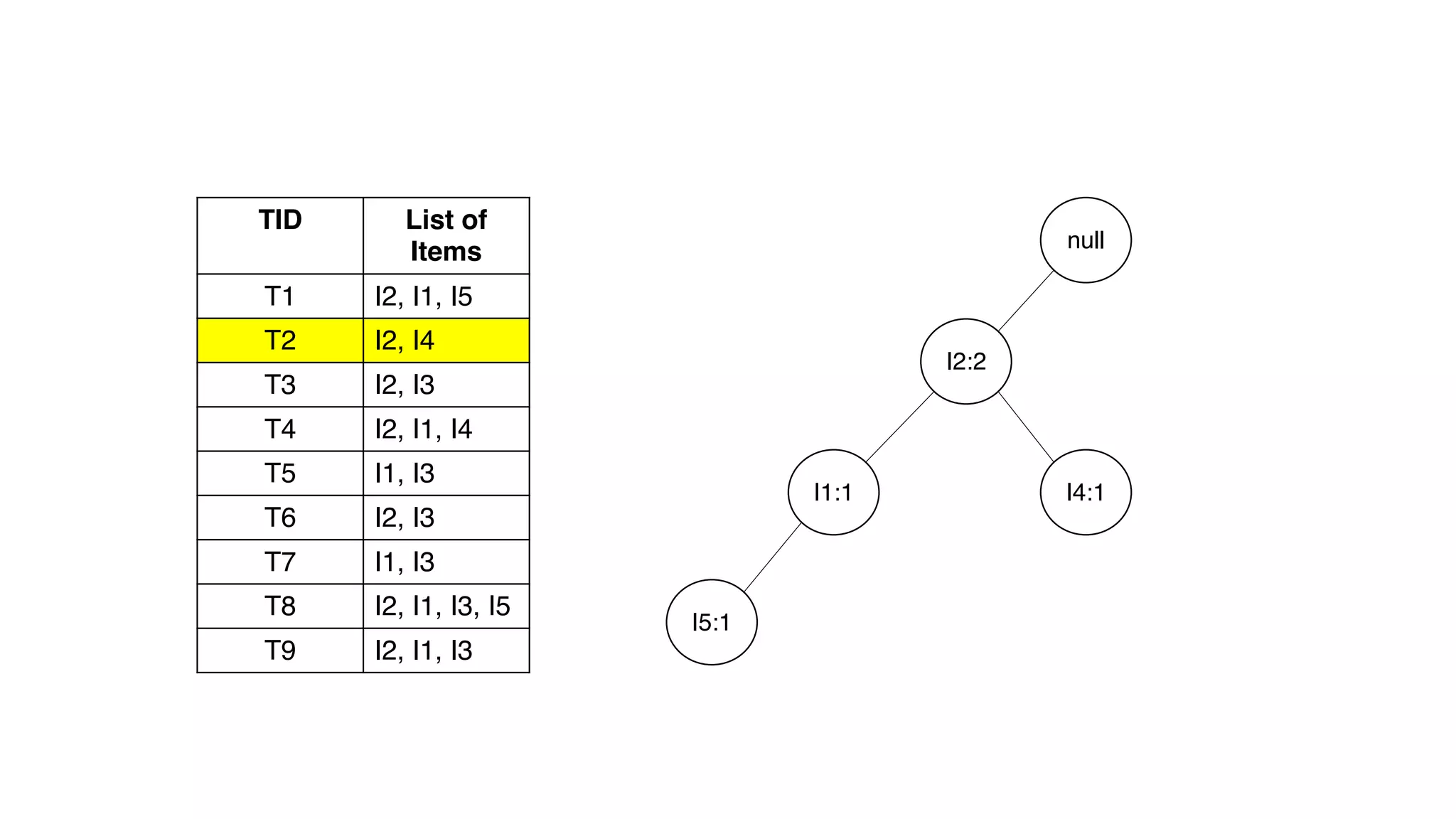
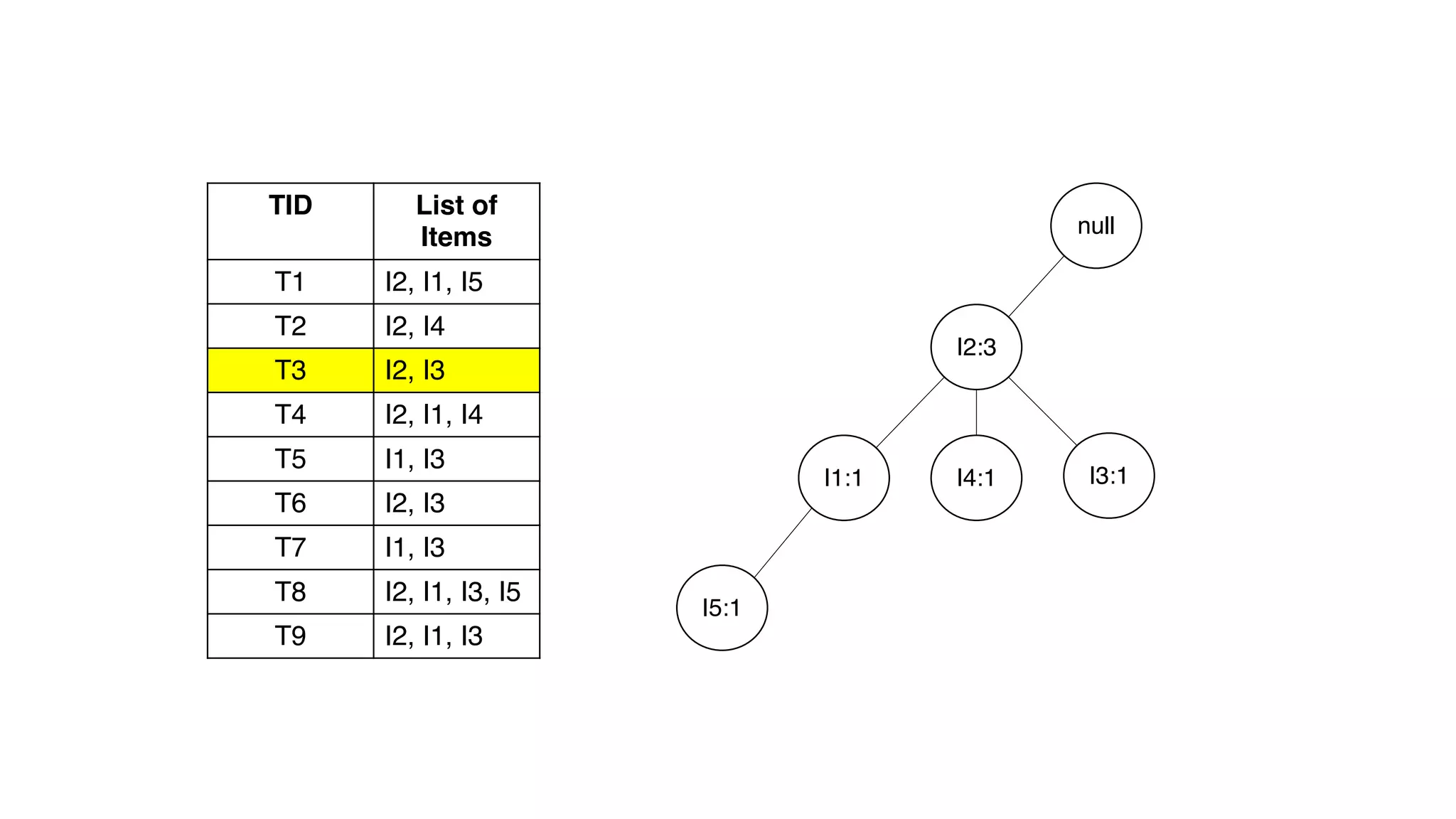
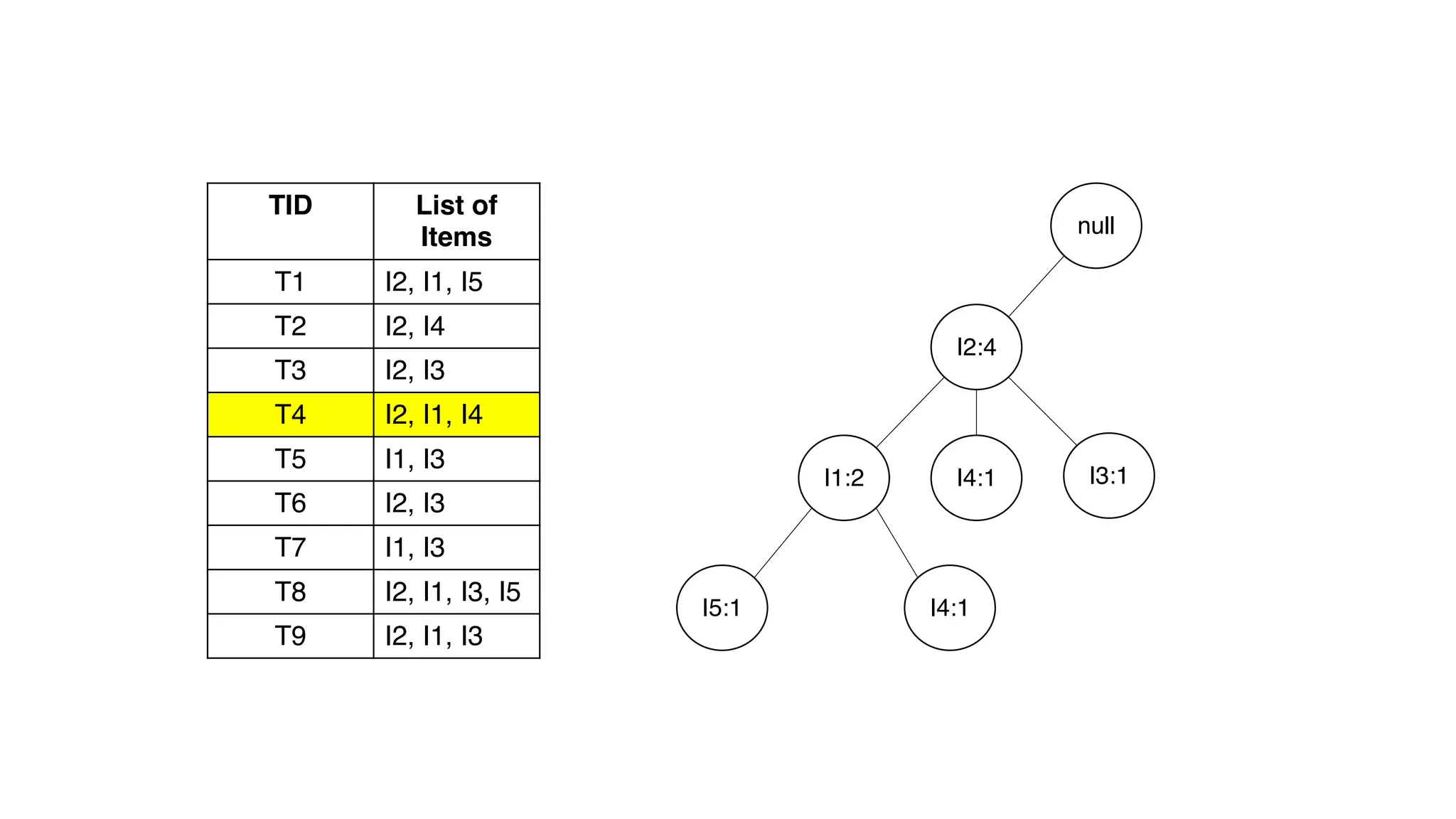
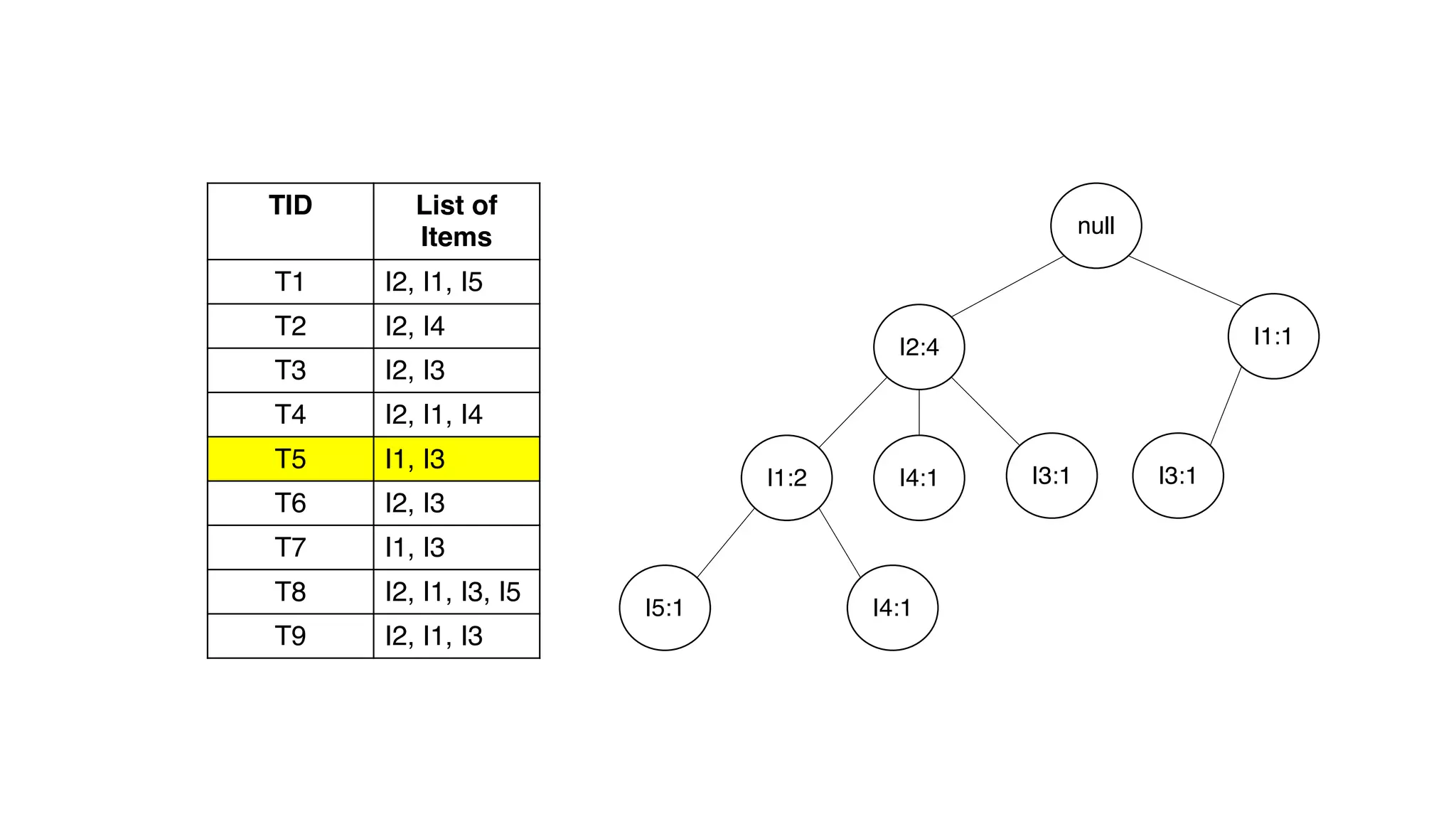
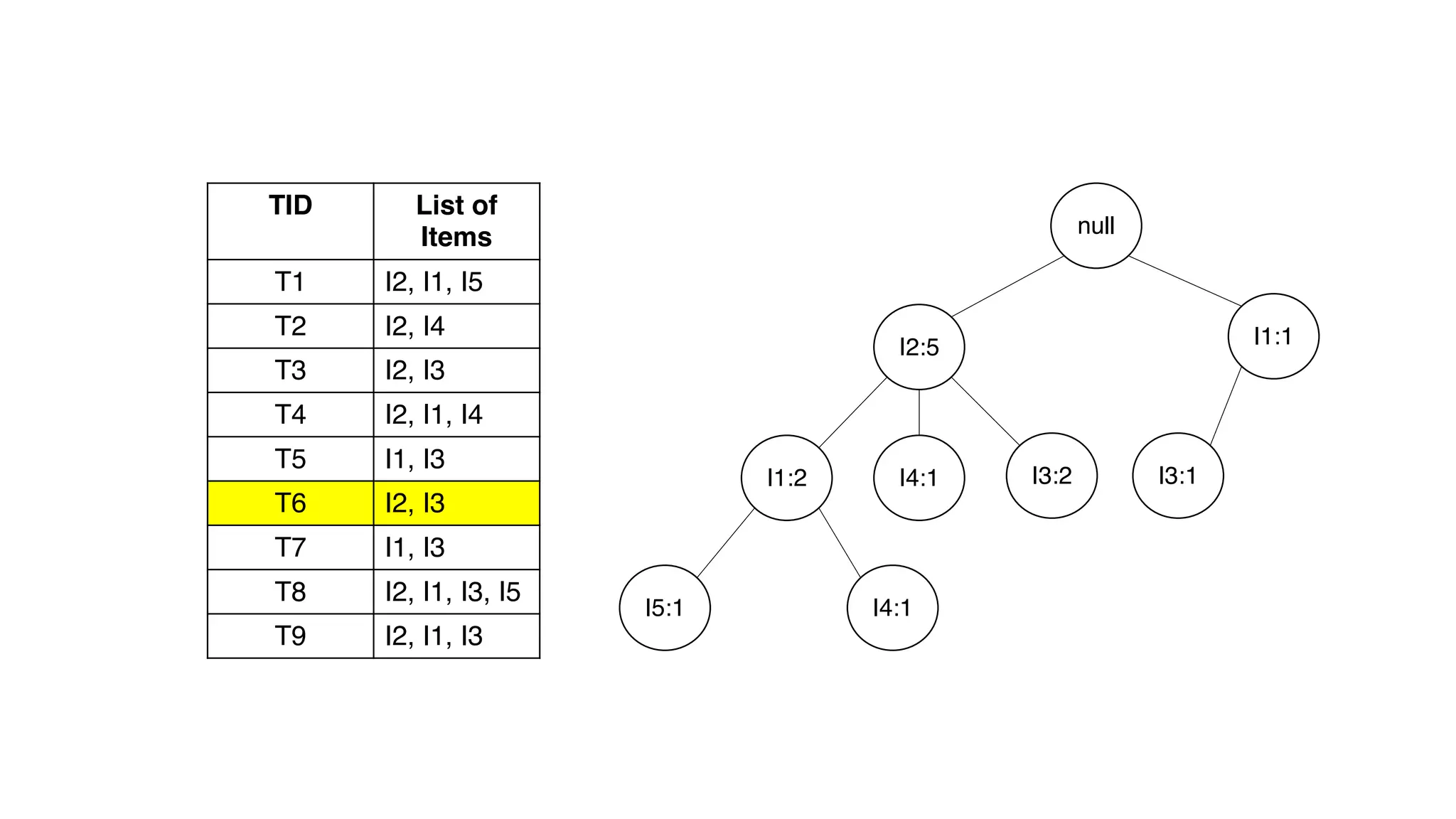
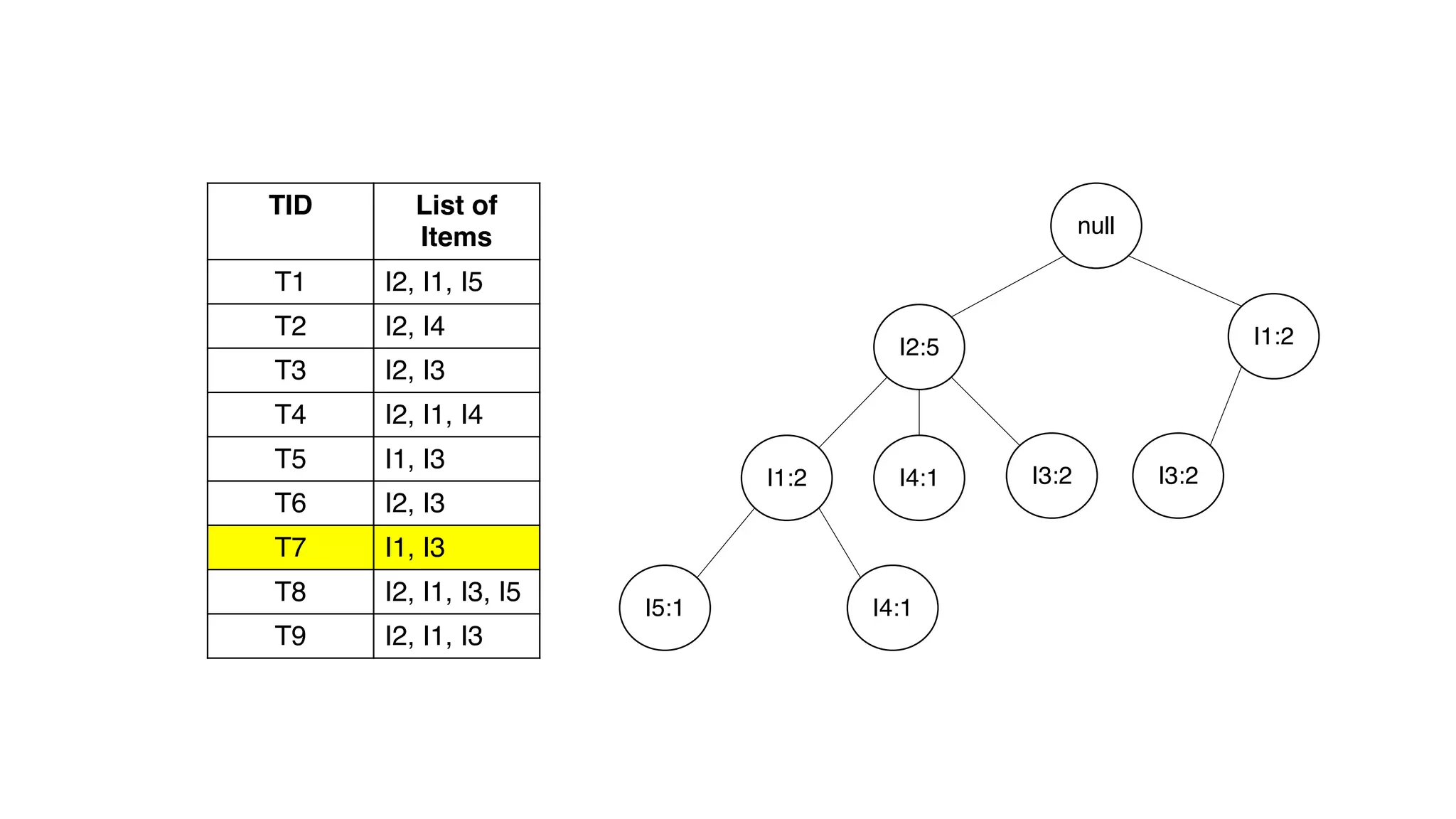
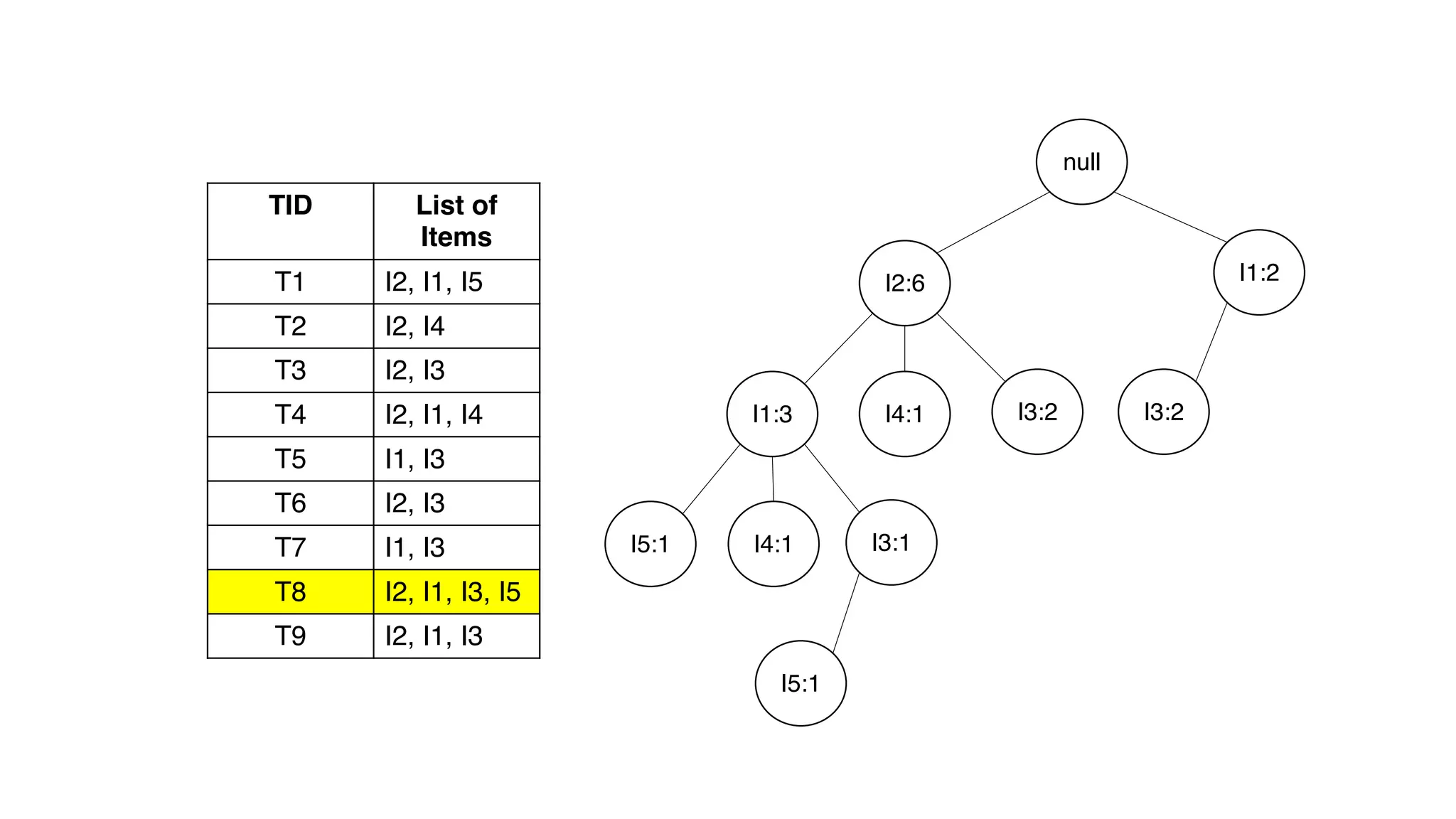
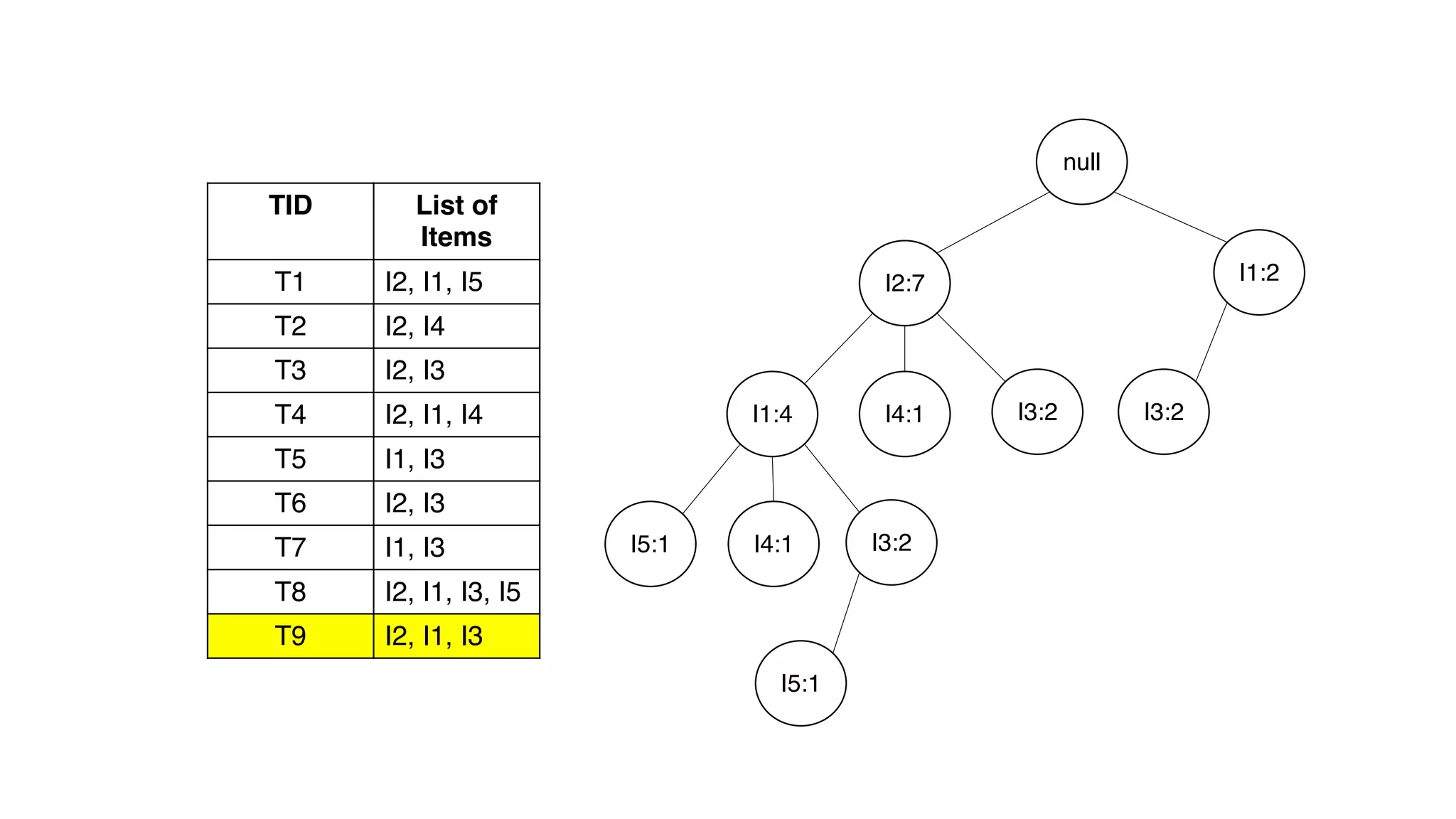

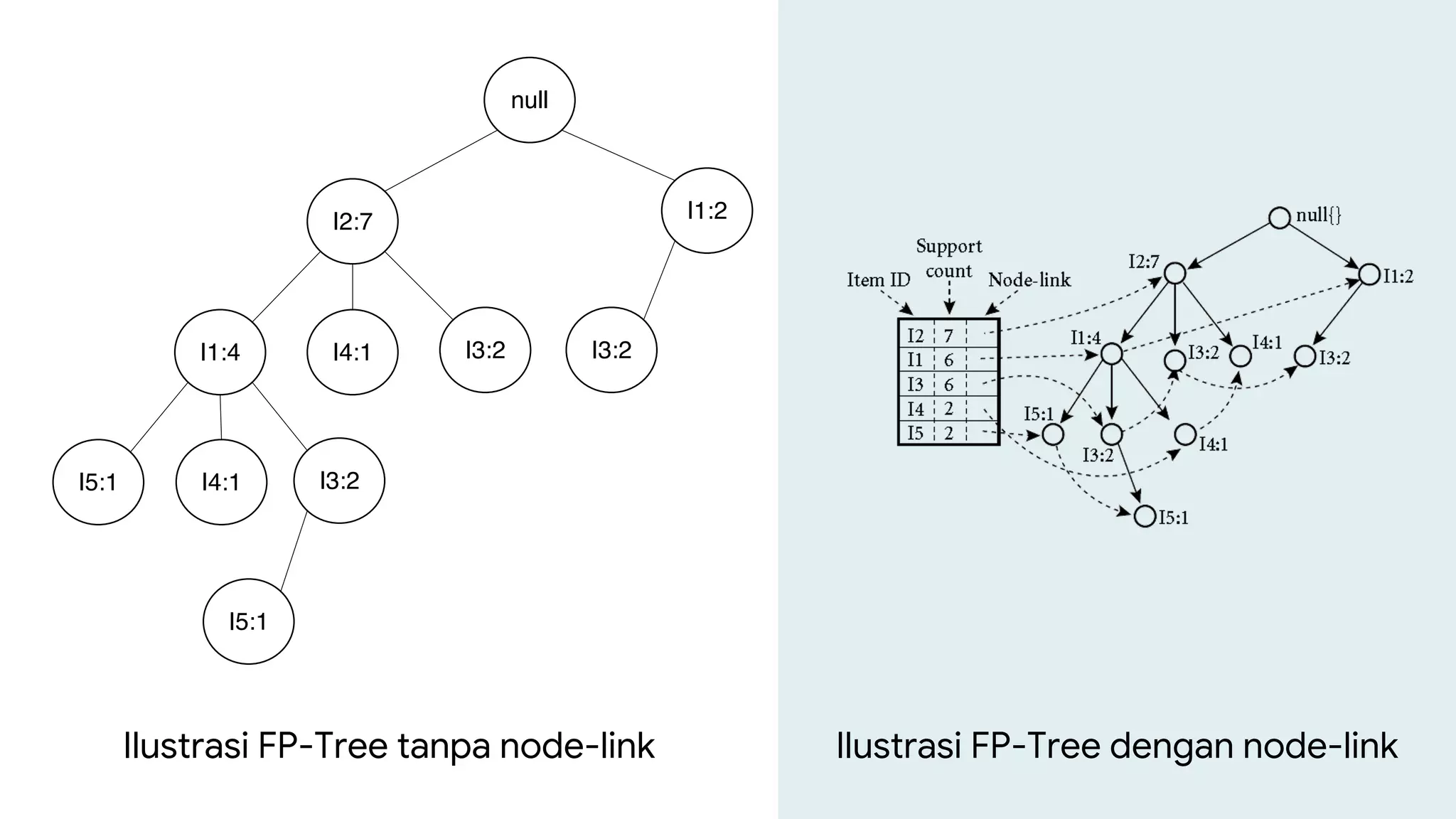

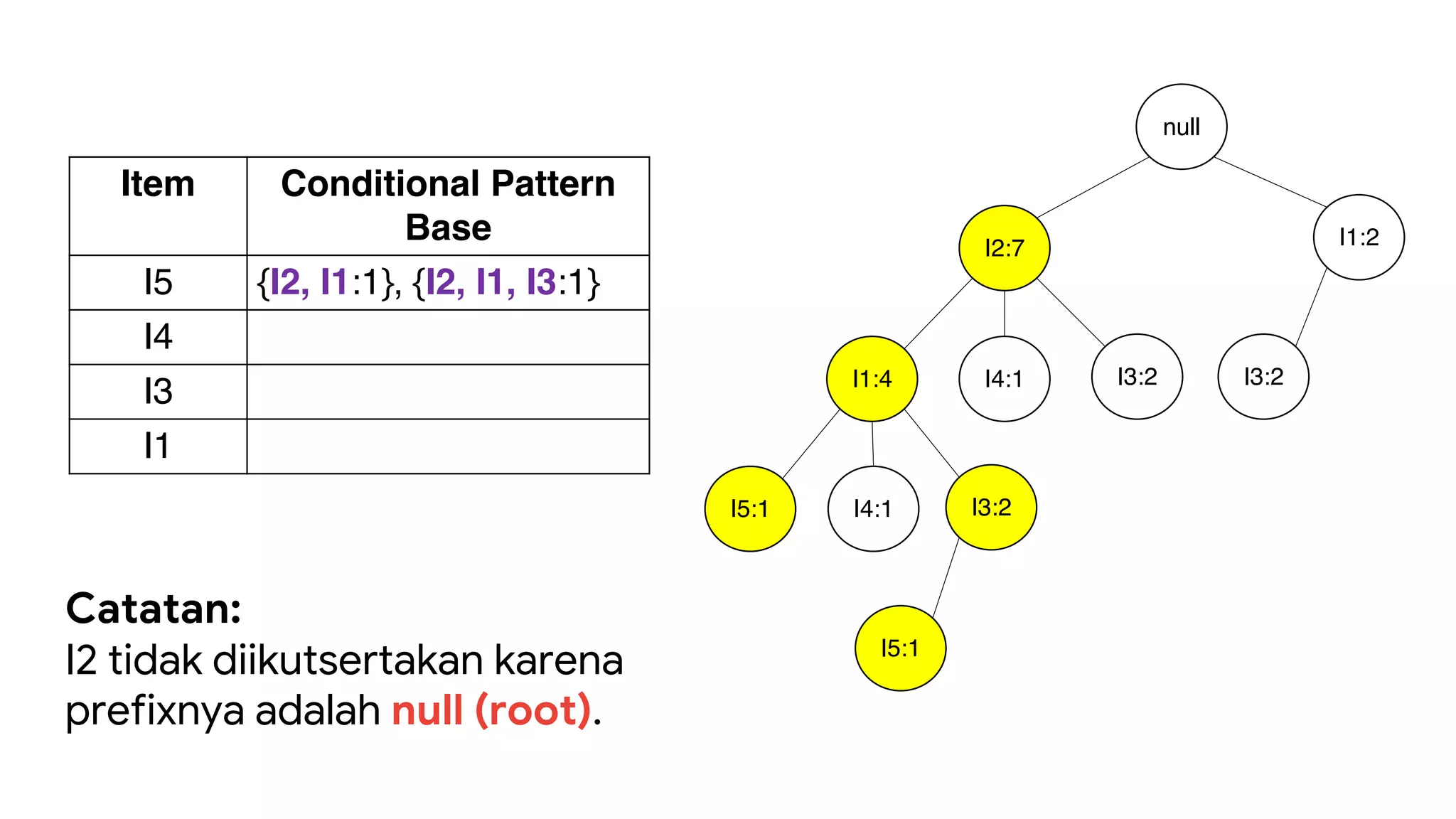
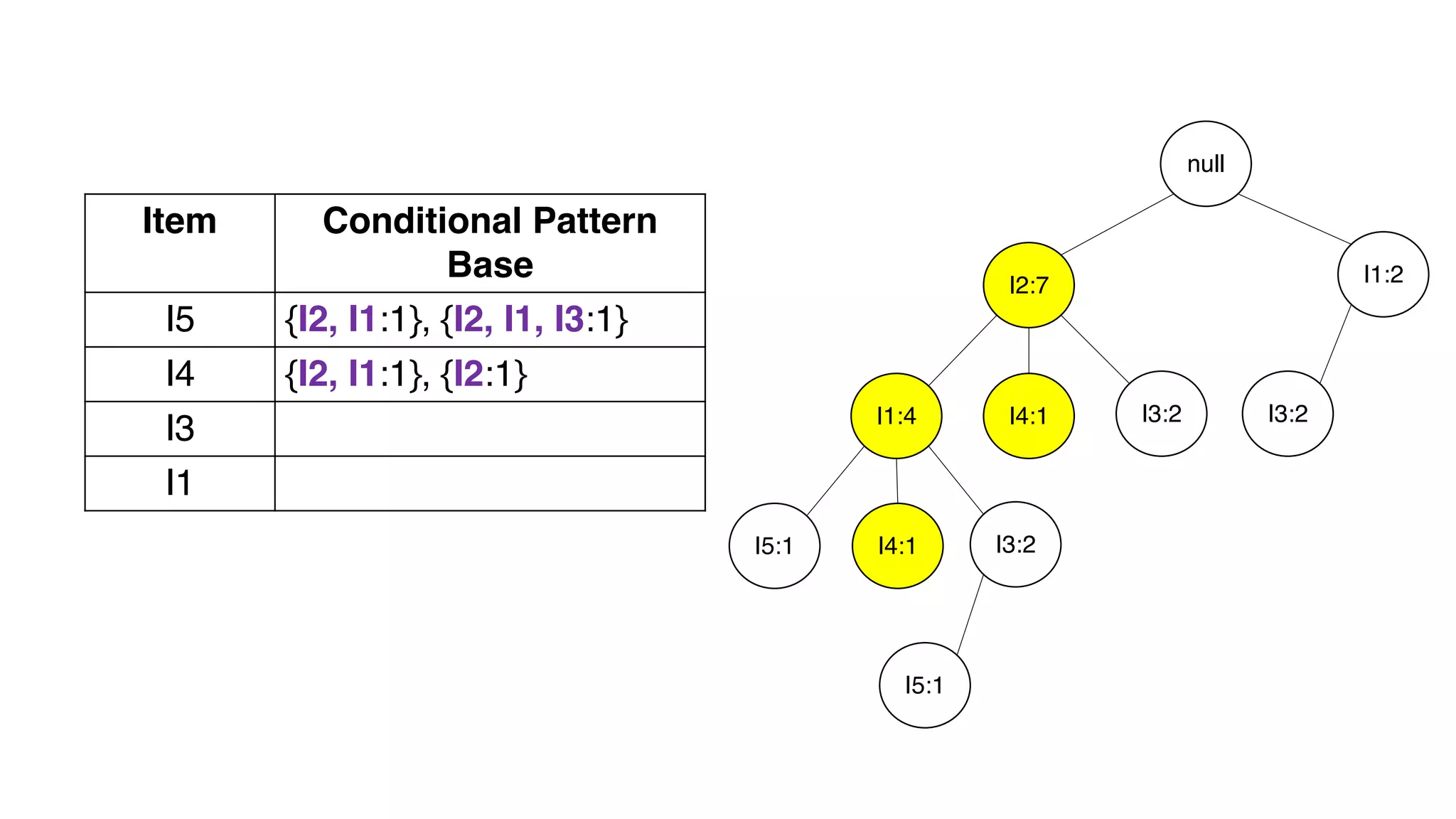
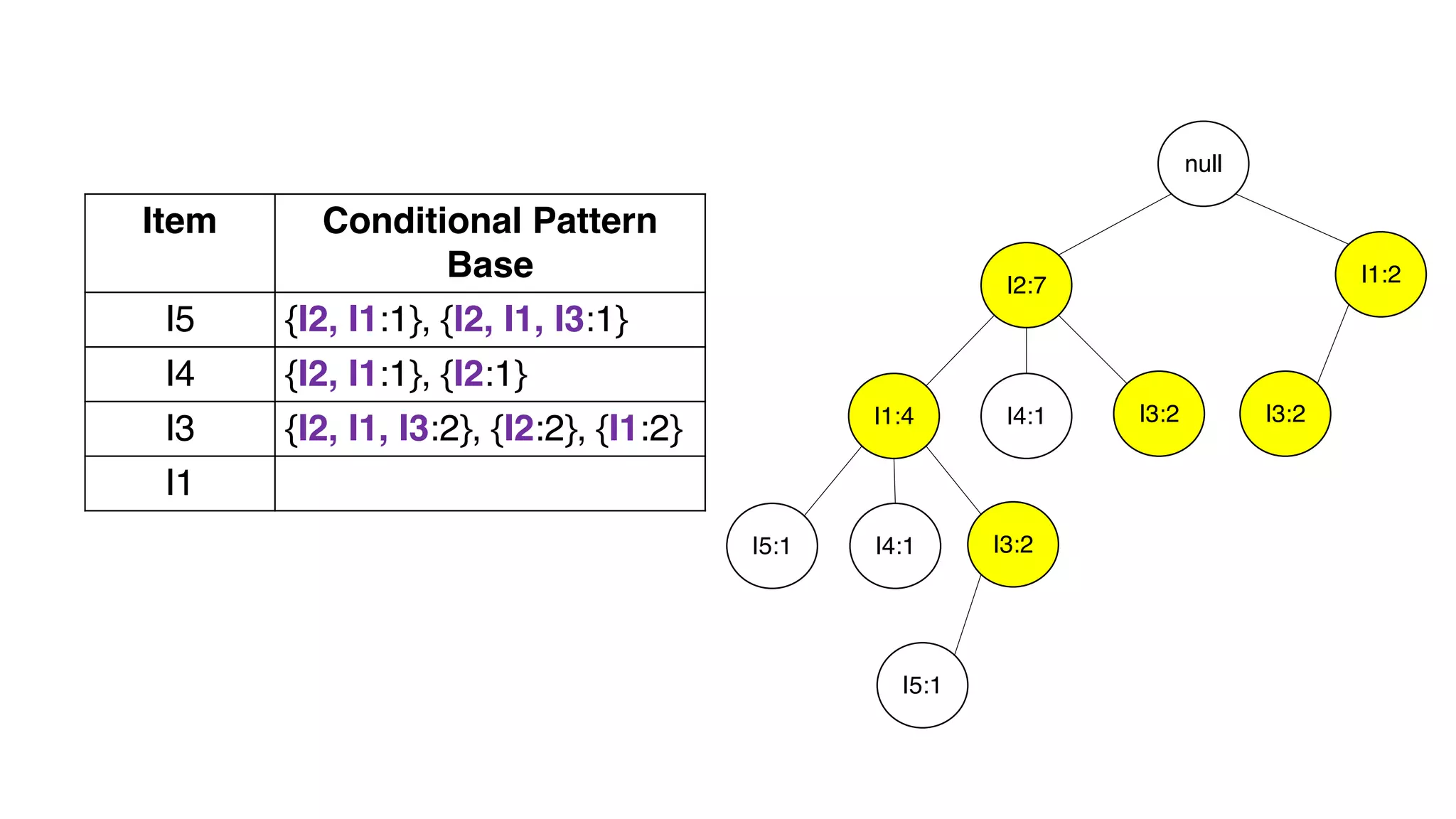
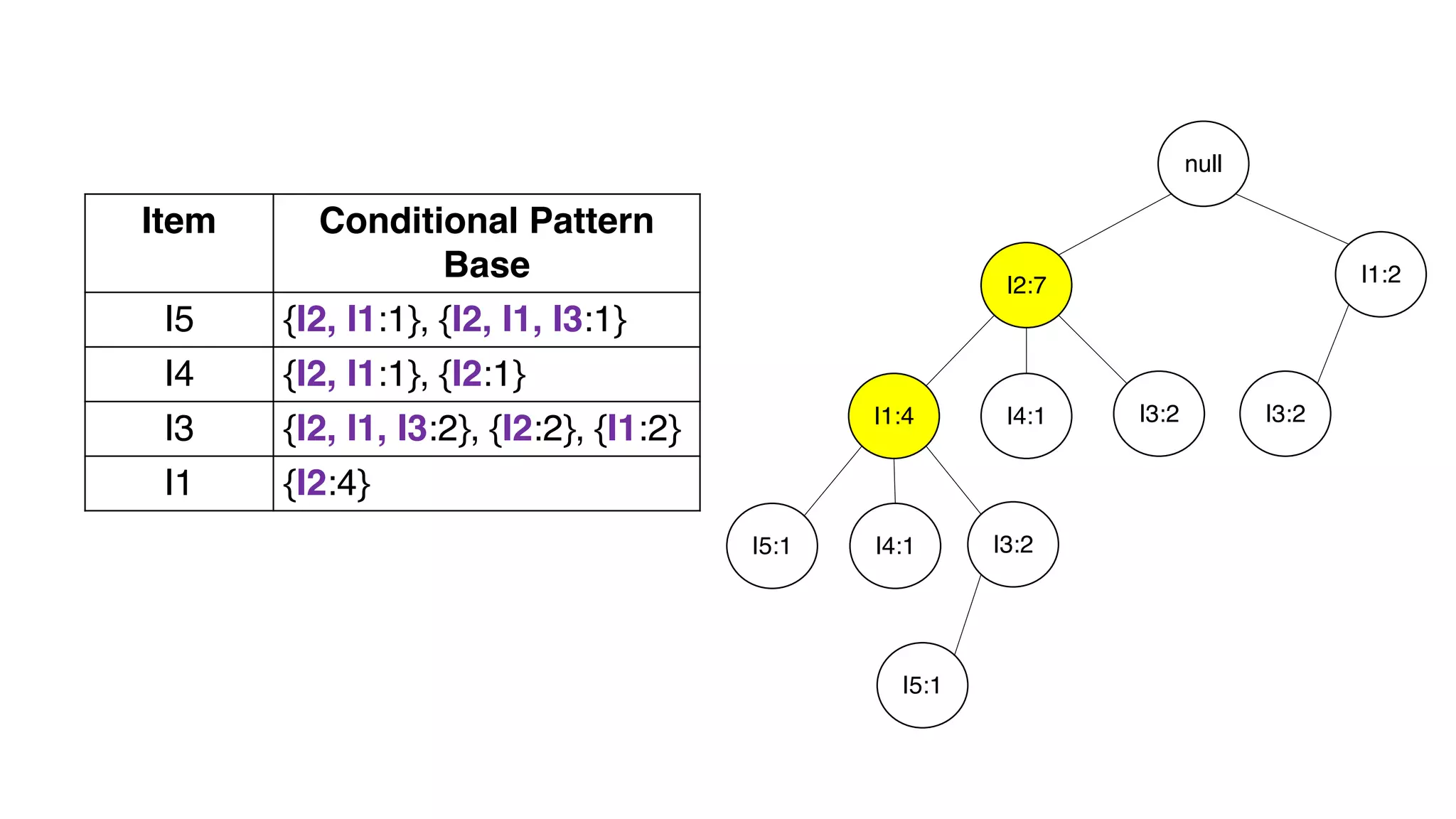

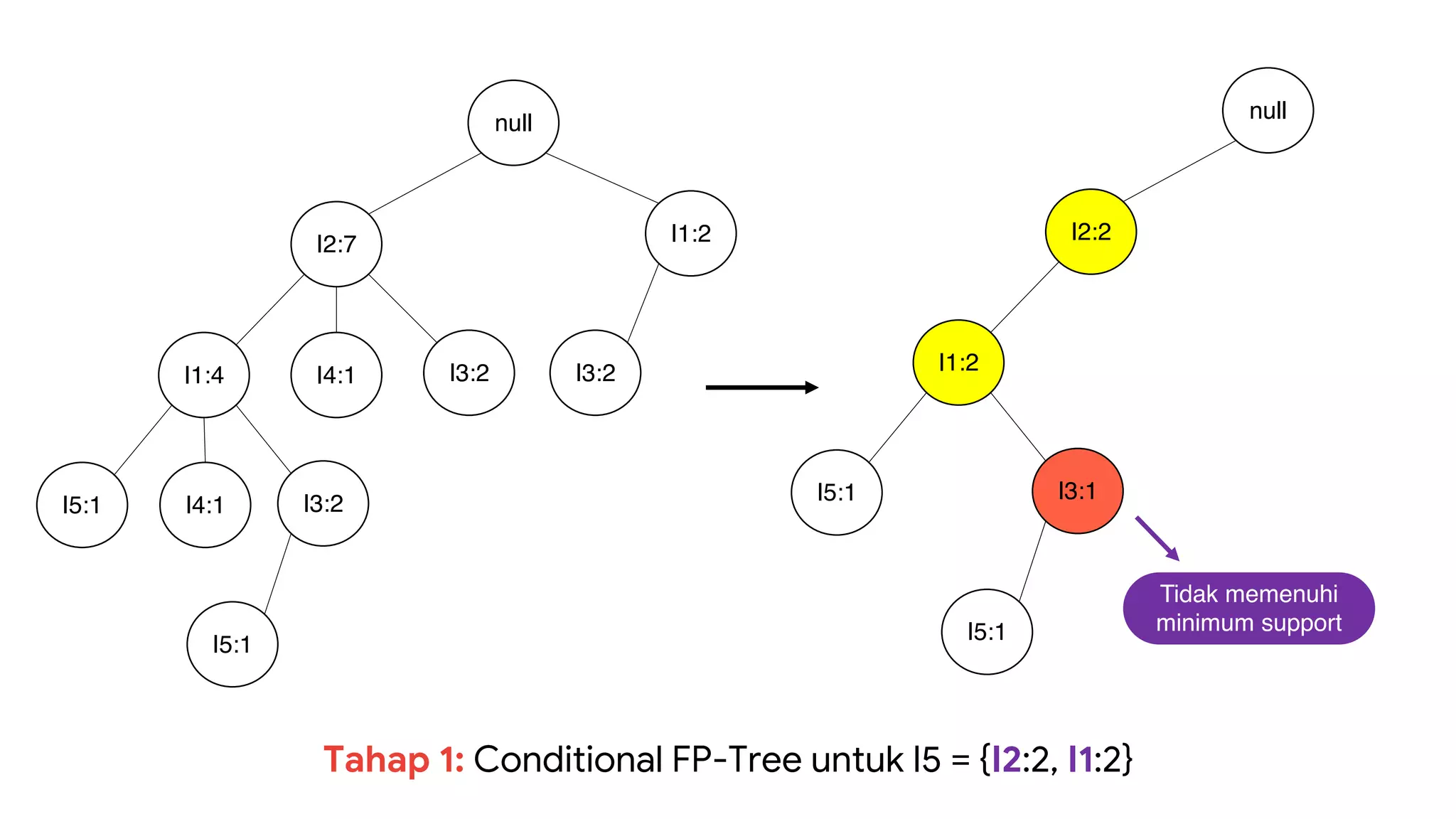
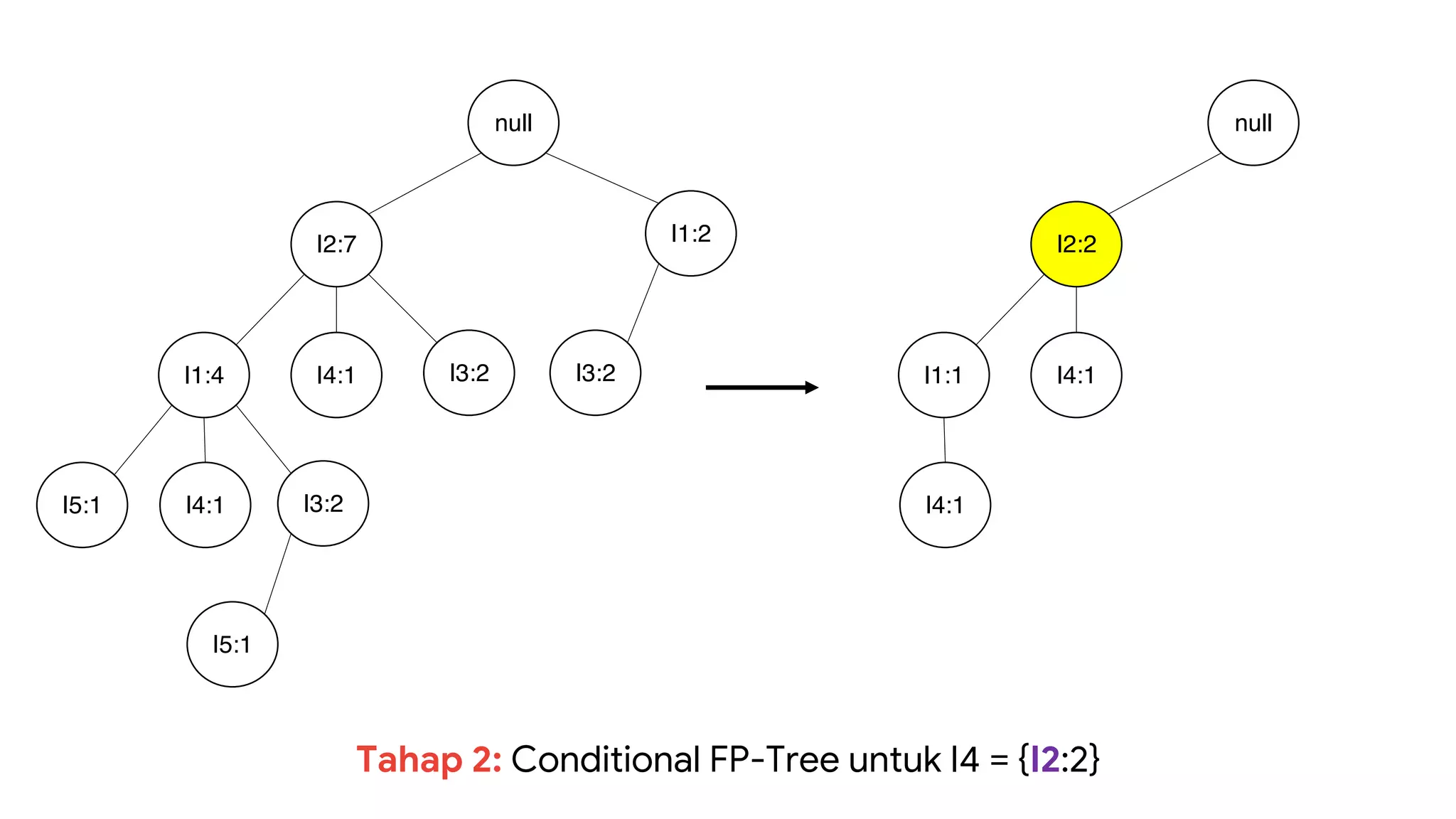
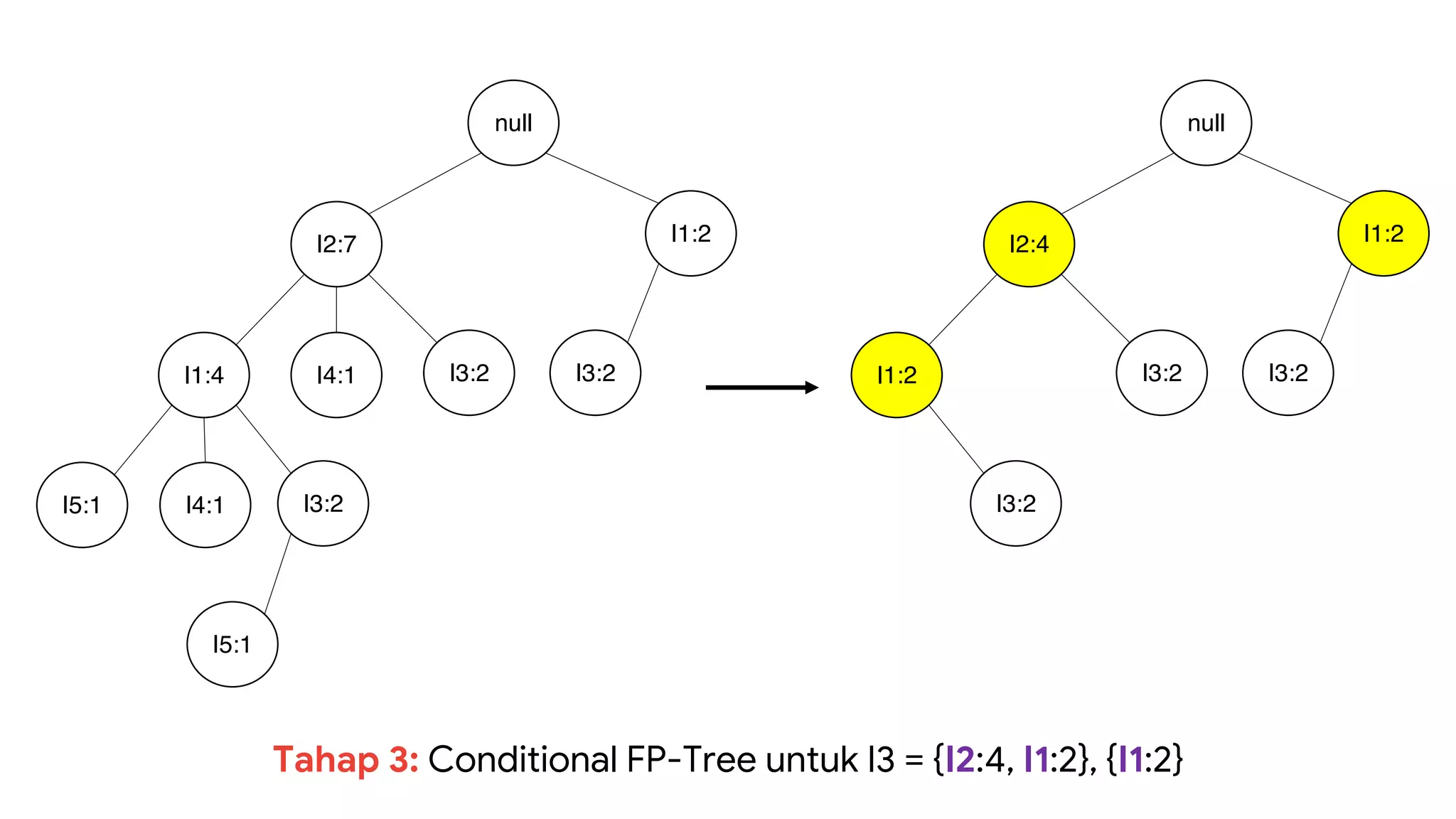
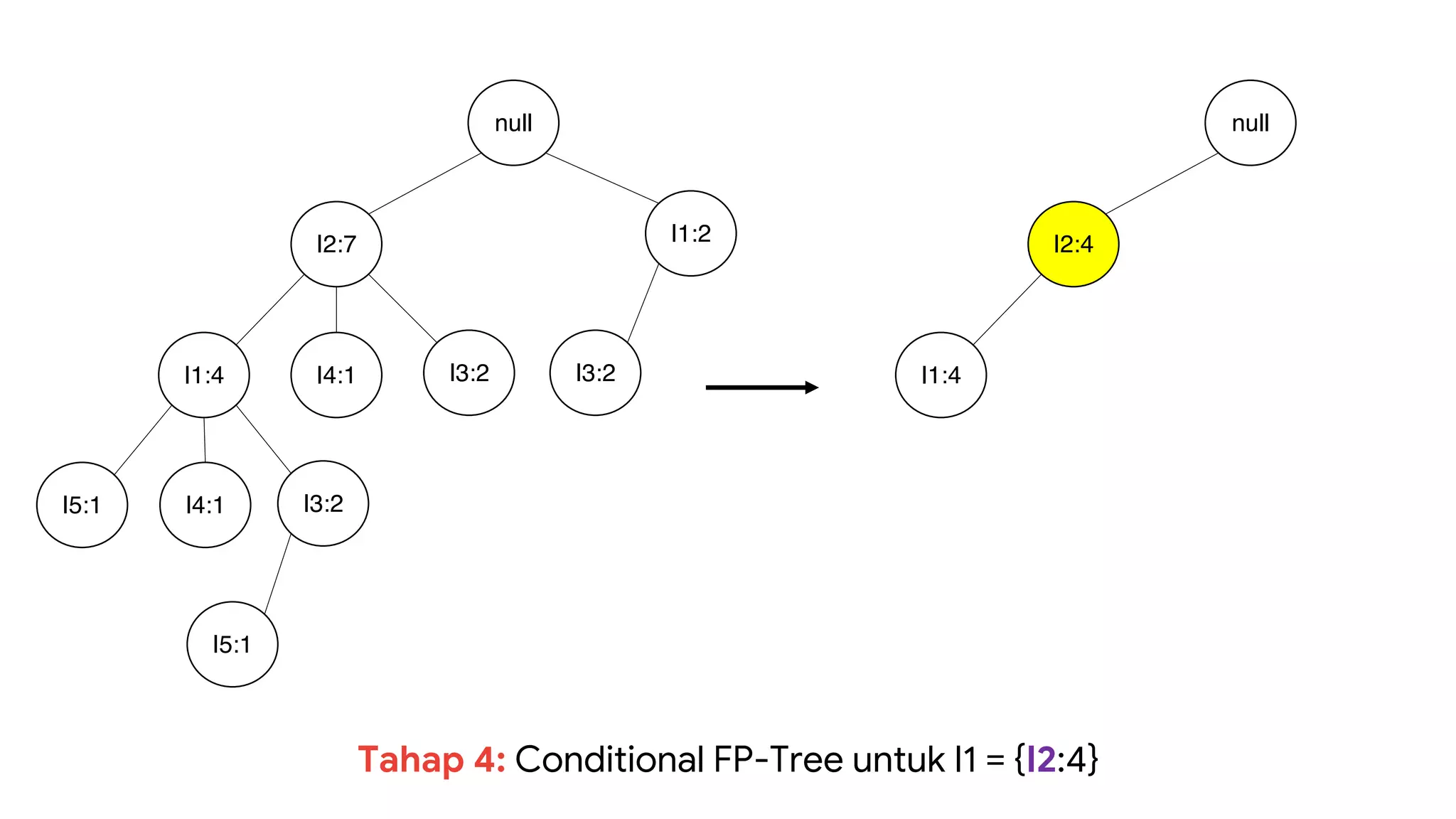
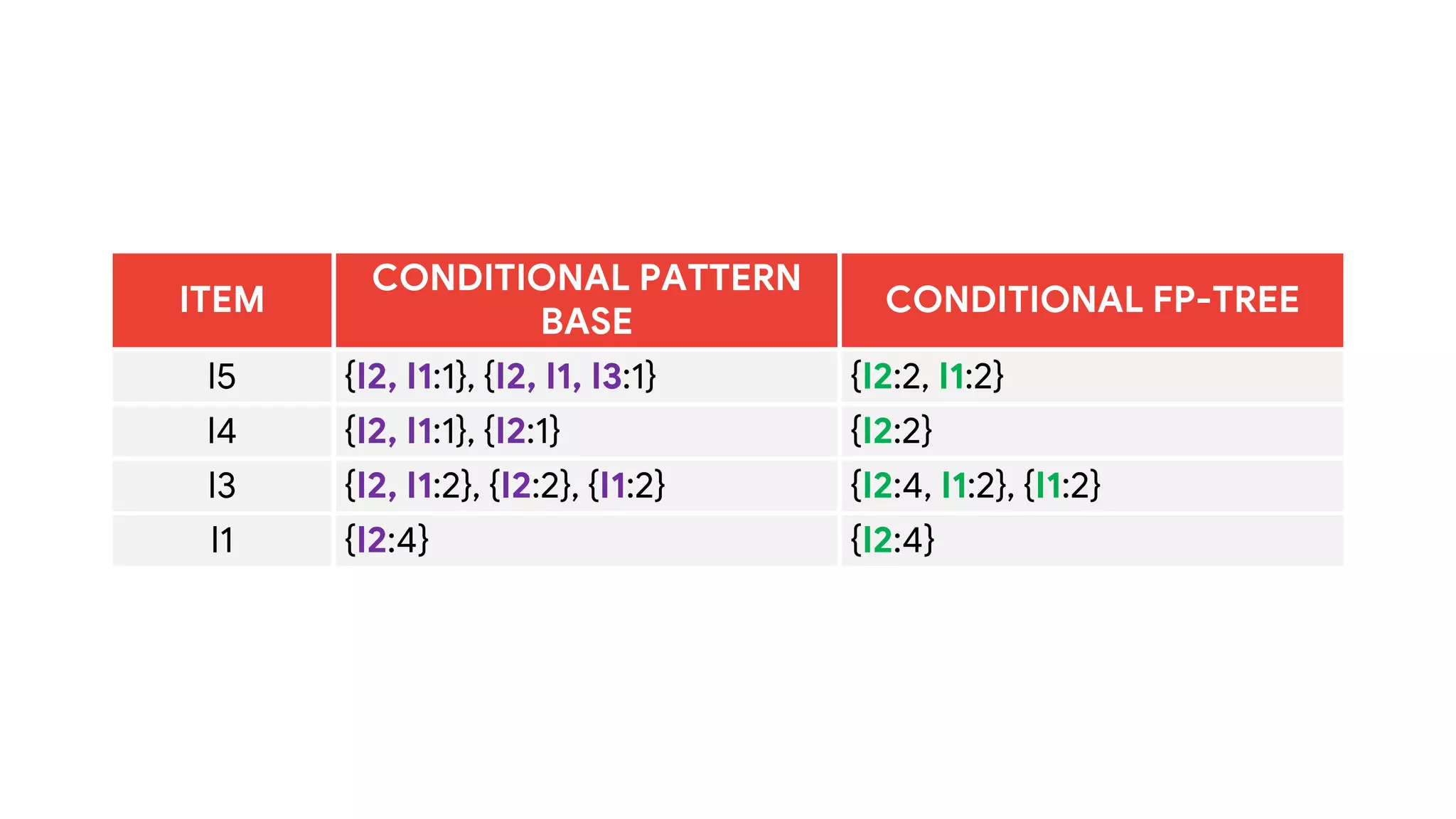

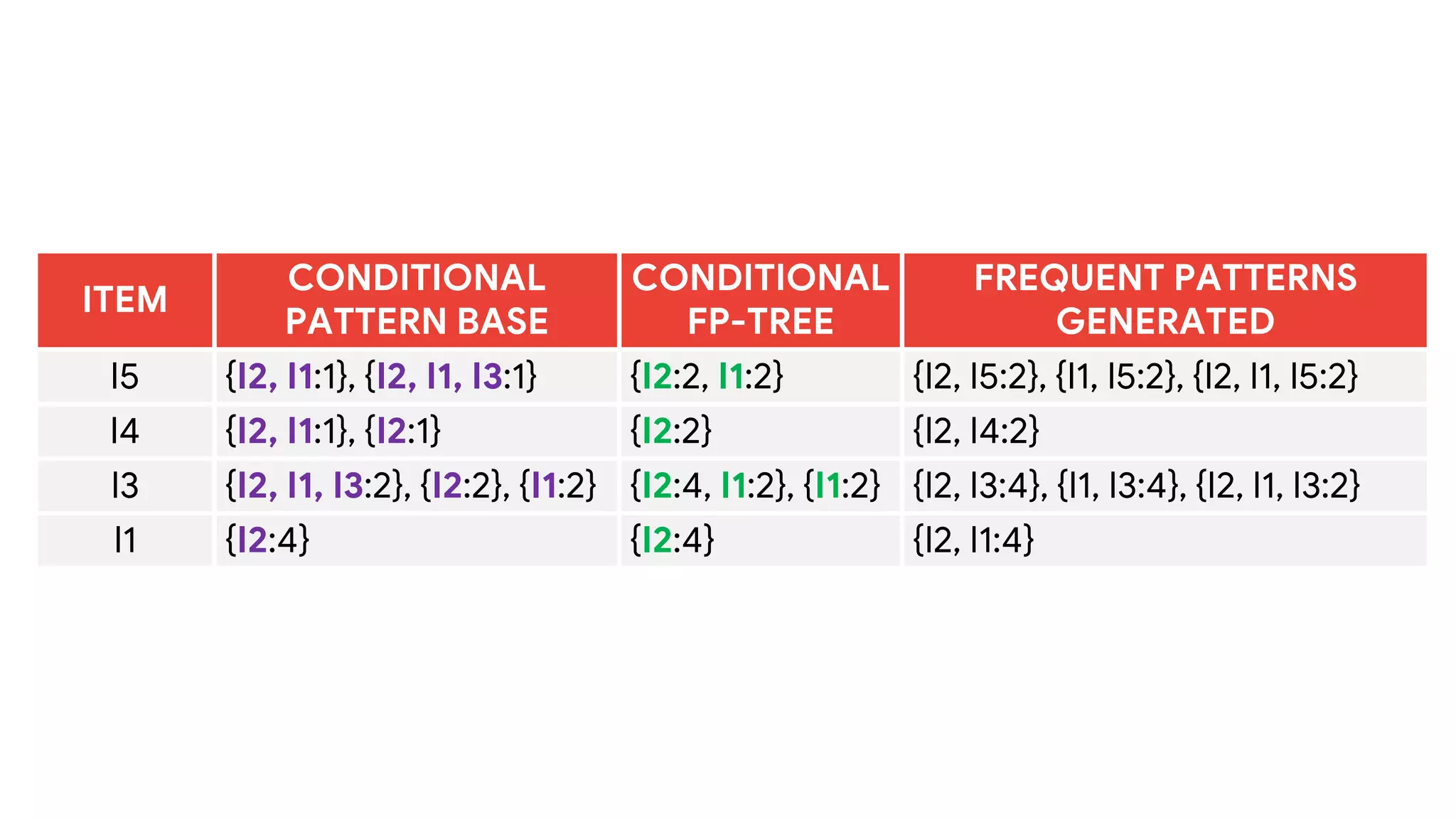








Dokumen ini menjelaskan metode data mining association rule, termasuk penggunaan nilai support dan confidence untuk mengekstraksi hubungan antar item. Algoritma yang dibahas adalah Apriori dan FP-Growth, dengan implementasi langkah-langkah untuk mengidentifikasi strong association rules. Penjelasan meliputi pembuatan frequent itemsets dan penerapan conditional pattern base untuk membentuk pola yang signifikan.











































![Association_Rules[Ardha_Luthfiarta].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/associationrulesardythaluthfiarta-250409122613-fd4cb21b-thumbnail.jpg?width=640&height=640&fit=bounds)























