Download as KEY, PPTX











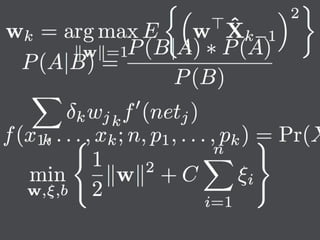















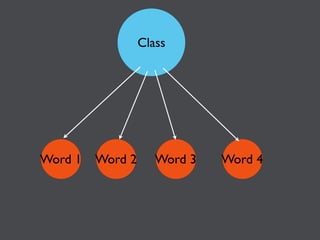
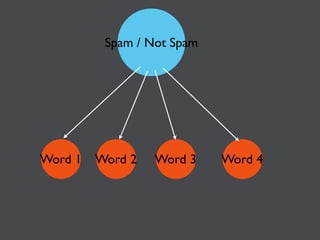
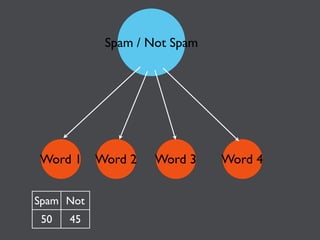
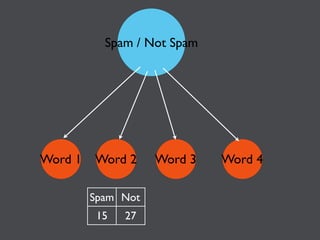
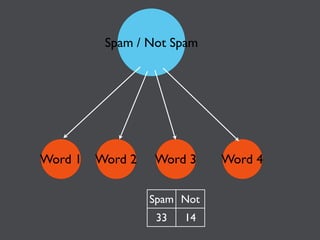
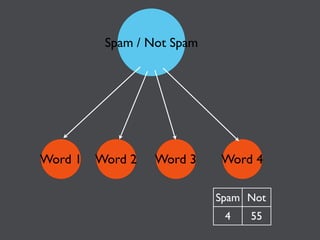






















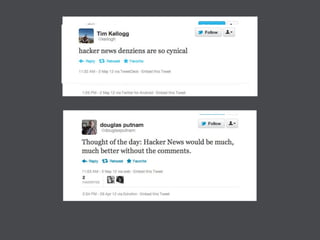
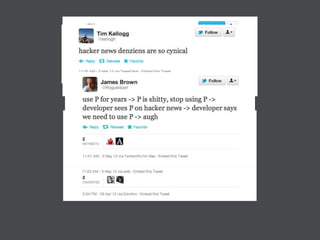
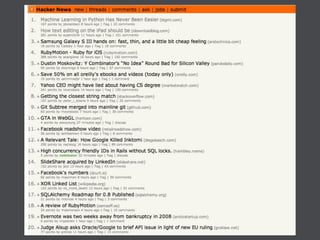
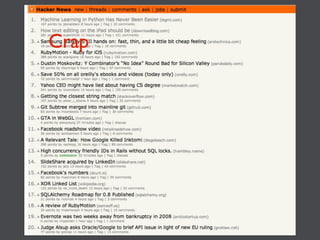

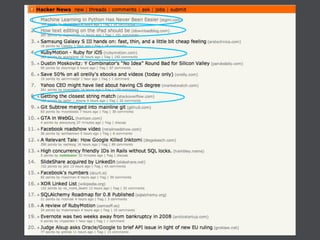








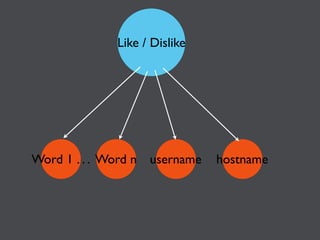




This document discusses machine learning in JavaScript and how it can be used to automatically analyze content on the web. It provides an overview of naive Bayes classification and how words in documents can be counted and compared to known spam or non-spam documents to determine if new documents are spam or not. Examples are given of how naive Bayes could be used to build a spam filter as well as how the technique could potentially be applied to analyze content on sites like Hacker News and surface the most valuable posts.















































