Download to read offline






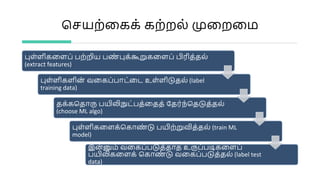
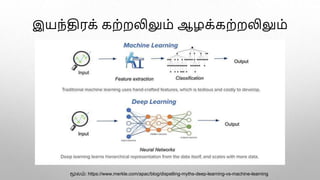



















இயந்திரக் கற்றல் பயிலிகளில் மொழியியல் கூறுகளை ஏற்றும் வாய்ப்புகள் இல. பாலசுந்தரராமன், மைக்குரோசாட்டு, பெங்களூர் கடந்த இருபது ஆண்டுகளில் இயந்திரக் கற்றல் (Machine Learning) நுட்பம் படிப்படியாக வளர்ச்சியடைந்து வந்துள்ளது. இன்று வகைப்படுத்தல் (classification), உணர்வறிதல் (sentiment identification), எழுத்துப்பெயர்ப்பு (transliteration), ஒலிபெயர்ப்பு (transcription), மொழிபெயர்ப்பு (translation) முதலிய வழக்கமான பணிகளுக்கு ஒவ்வொருவரும் தனித்தனியாக அடிப்படையிலிருந்து பயிலிகளைப் பயிற்றுவிக்க வேண்டியதில்லை எனும் நிலை ஏற்பட்டுள்ளது. இணையத்தில் கிடைக்கும் உரைகளைக் கொண்டு முன்பே பயிற்றுவித்த ஆழக்கற்றல் பயிலி மாதிரிகளை (Pre-trained Deep Learning Models) எவரும் தரவிறக்கிக் கொள்ள முடியும். பின்பு தத்தம் தேவைக்கேற்ப துறைசார், களம் சார் பயிற்சியுரைகளைக் கொண்டு பொதுப்பயிலிகளை கூடுதல் பயிற்சிக்குட்படுத்தி குறிப்பிட்ட பணிகளுக்குப் பயன்படுத்த முடிகிறது. ஆழக்கற்றலில் மொழியியற் பண்புகள் எவற்றையும் நாம் உள்ளிட வேண்டியதில்லை என்றும் போதிய அளவு எடுத்துக்காட்டுகள் இருப்பின் எவ்வித மொழிப்பண்பையும் பயிலி பயின்றுகொள்ளும் என்று அழுத்தமானவொரு வாதமுள்ளது. இதனால் இனி இயல்மொழிச் செயிலிகளைச் செய்வதற்கு மொழியியல் தேவையா என்ற கேள்வியும் எழுந்துள்ளது. இச்சூழலில், சில குறிப்பிட்ட இடங்களில் மொழியியற் கூறுகளை இயந்திரக் கற்றலுக்கு உள்ளீடாக வழங்குவதன்மூலம் பயிலிகள் முன்னைக் காட்டிலும் சிறப்பாக இயங்கும் வாய்ப்புள்ளது என்று சில எடுத்துக்காட்டுகளின் வழியாகக் காணலாம். தமிழிலும் மலையாளத்திலும் அமைந்த யூட்டியூபுக் கருத்துகளின் உணர்வைப் பகுக்கும் பயிலியொன்றை இதற்கு எடுத்துக்காட்டாகக் கொள்ளலாம். இதற்கான பயிலியொன்றை தமிழையும் மலையாளத்தையும் அறியாத சீன மொழி ஆய்வர்கள் ஆழக்கற்றல் பயிலியைப் பயன்படுத்தி வியத்தகு அளவிற்கு செயற்படுத்தினார்கள். இருப்பினும் இதிலும் சில எளிய மொழியியற் கூறுகளைச் சேர்ப்பதன்மூலம் இன்னும் மேம்பட்ட பயிலியை உருவாக்க முடியுமென்பதைக் காணலாம். மேற்கோள்கள் Qiu, Xipeng, Tianxiang Sun, Yige Xu, Yunfan Shao, Ning Dai, and Xuanjing Huang. "Pre-trained models for natural language processing: A survey." Science China Technological Sciences (2020): 1-26. Christopher D. Manning; Computational Linguistics and Deep Learning. Computational Linguistics 2015; 41 (4): 701–707. doi: https://doi.org/10.1162/COLI_a_00239 Ou, Xiaozhi, and Hongling Li. "YNU@ Dravidian-CodeMix-FIRE2020: XLM-RoBERTa for Multi-language Sentiment Analysis." In FIRE (Working Notes), pp. 560-565. 2020. Church, Kenneth, and Mark Liberman. "The Future of Computational Linguistics: On Beyond Alchemy." Frontiers in Artificial Intelligence 4 (2021): 10. Balasundararaman L and Sanjeeth Kumar Ravindranath. 2020. Theedum Nandrum@Dravidian-CodeMix-FIRE2020: A sentiment polarity detection system for YouTube comments with code switching between Tamil, Malayalam and English. In FIRE (Working Notes). CEUR, Hyderabad, India



























