Download to read offline




















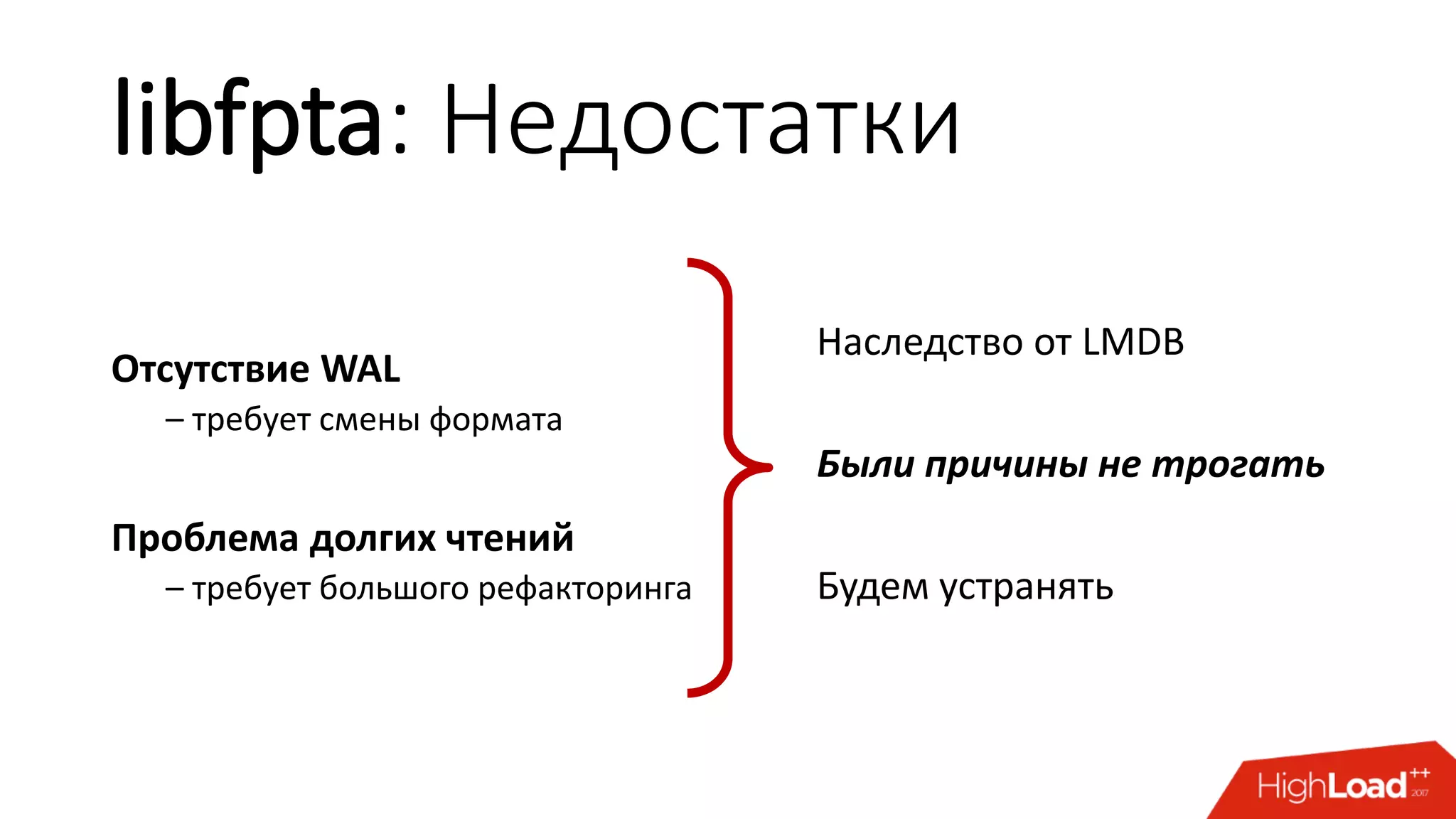








Документ представляет libfpta — продвинутый движок хранения данных, который предлагает высокую производительность и минимальные задержки в обработке локальных процессов. Он комбинирует функции других библиотек, таких как libmdbx и libfptu, и ориентирован на применение в условиях, где критически важна скорость и время восстановления. Однако у libfpta есть ограничения, включая отсутствие журнальной записи (WAL) и проблемы с долгими чтениями, что требует дальнейшего рефакторинга.
















































































