Downloaded 18 times

































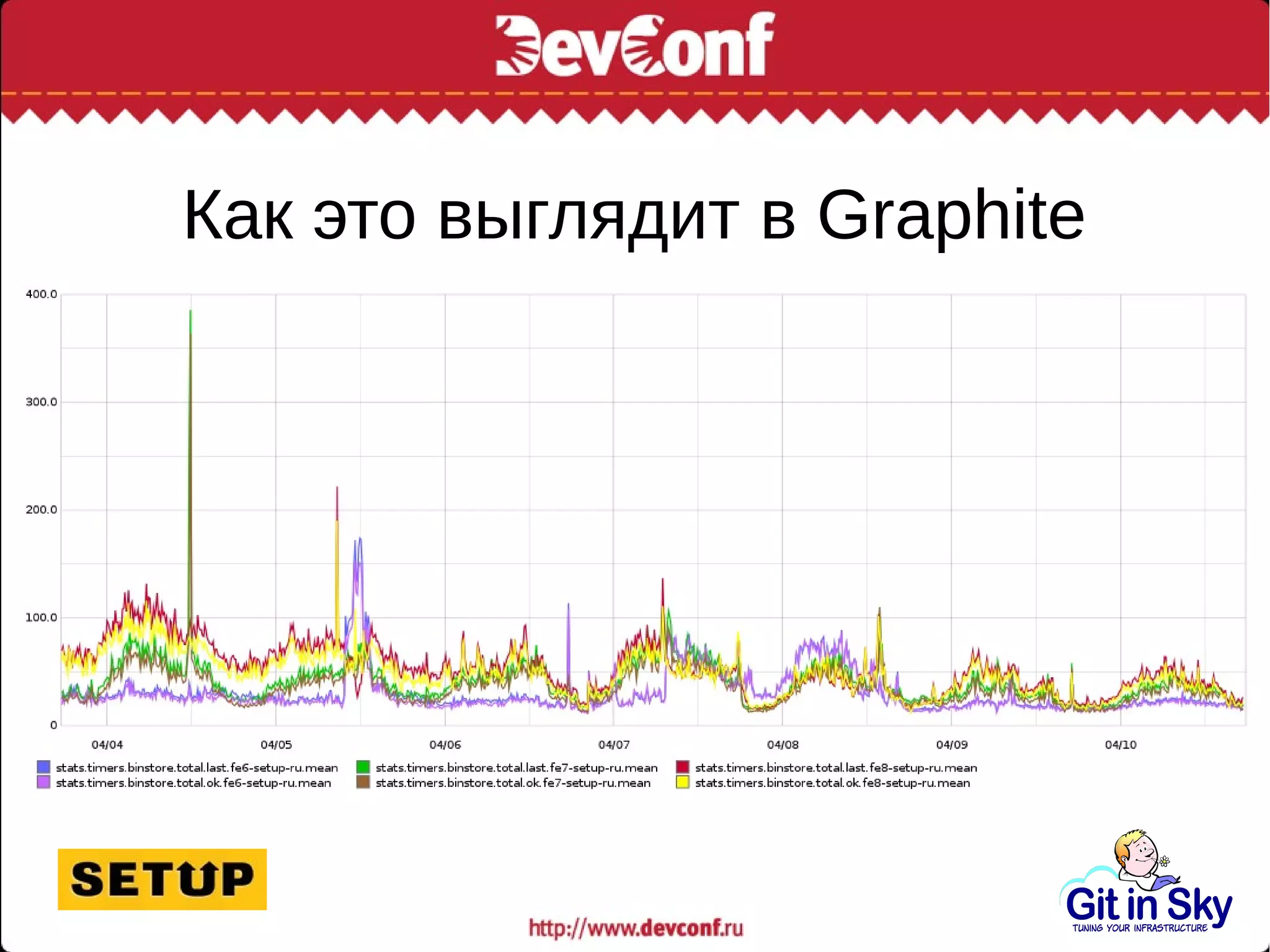
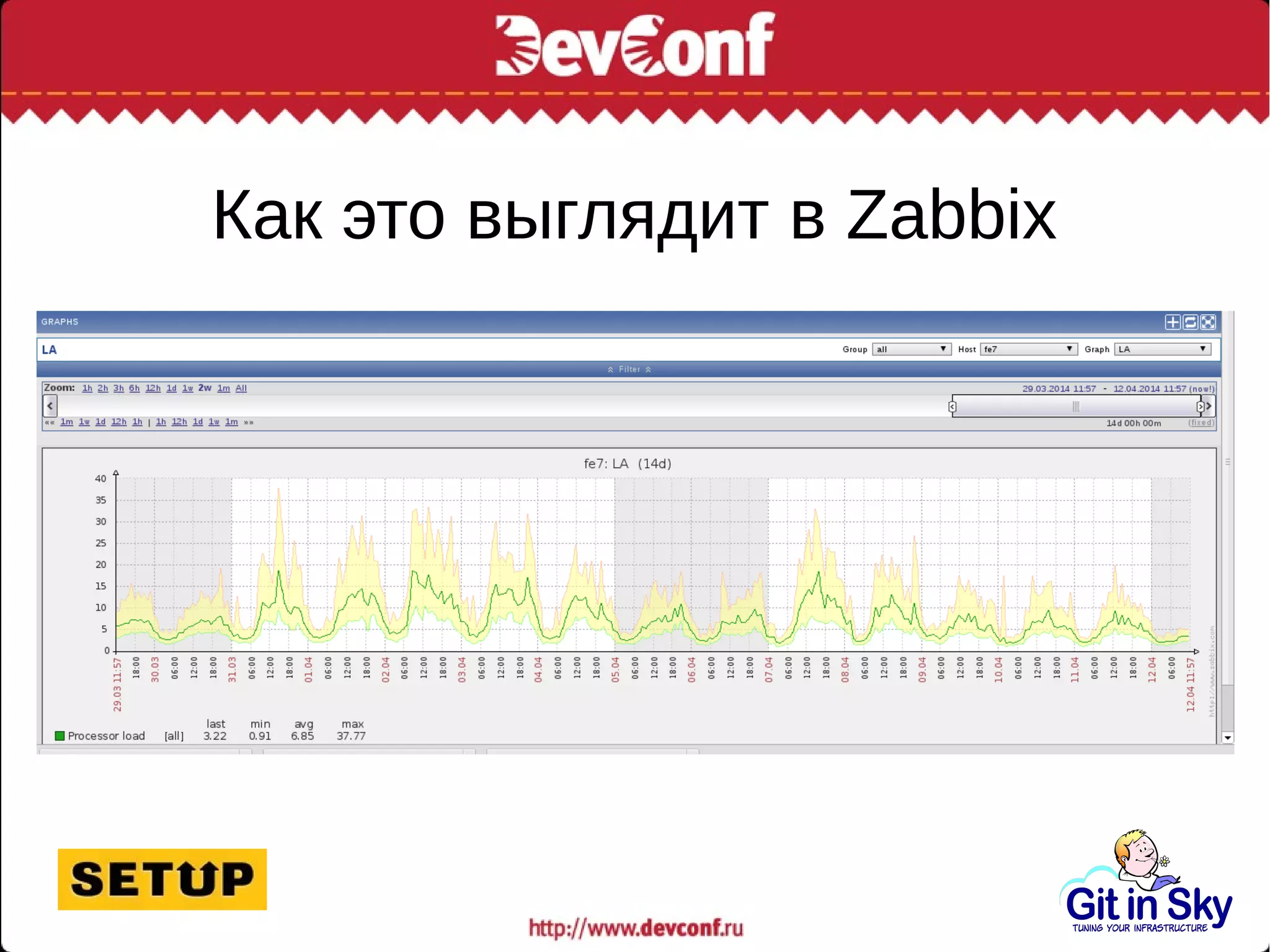









Саша, главный инженер компании Git in Sky, делится опытом оптимизации MySQL-сервера и управления большими объемами данных, обсуждая проблемы производительности и способы их решения. Основное внимание уделяется замедлению запросов и необходимости улучшения индексов, а также интеграции с системами мониторинга. Автор подчеркивает важность искать альтернативные хранилища для управления данными, а не слепо следовать устаревшим методам.



















































































