Download as PDF, PPTX

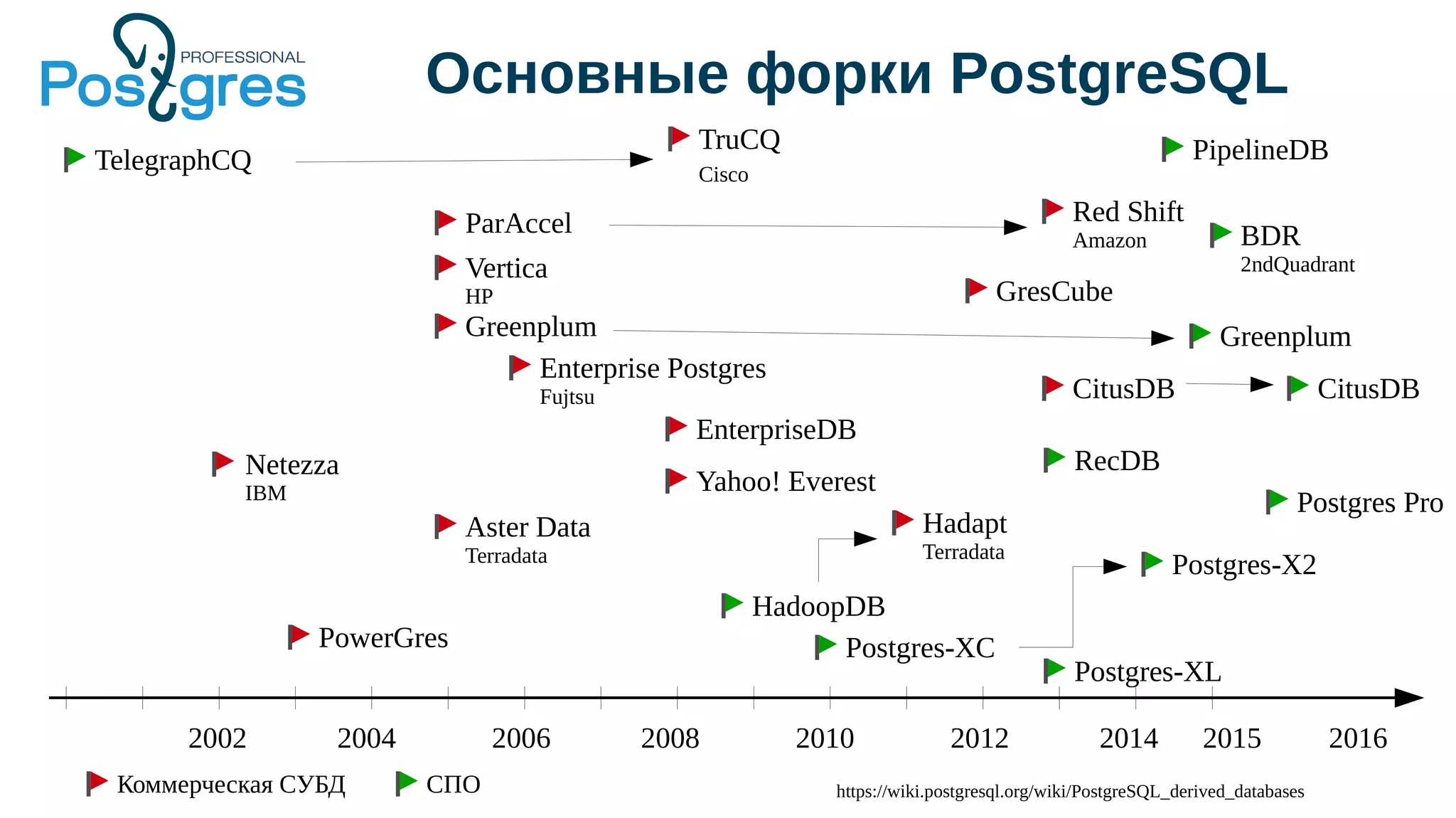
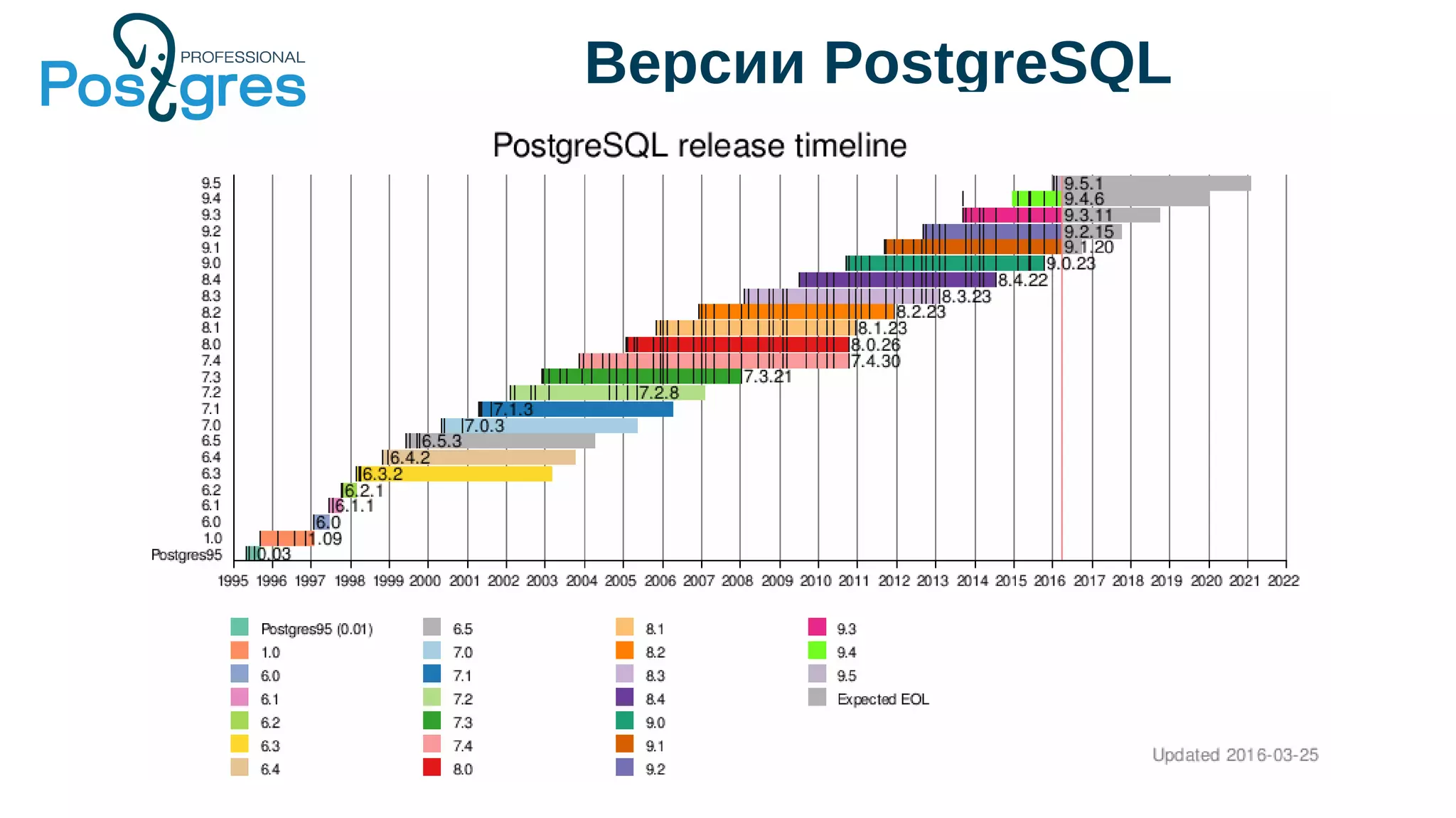






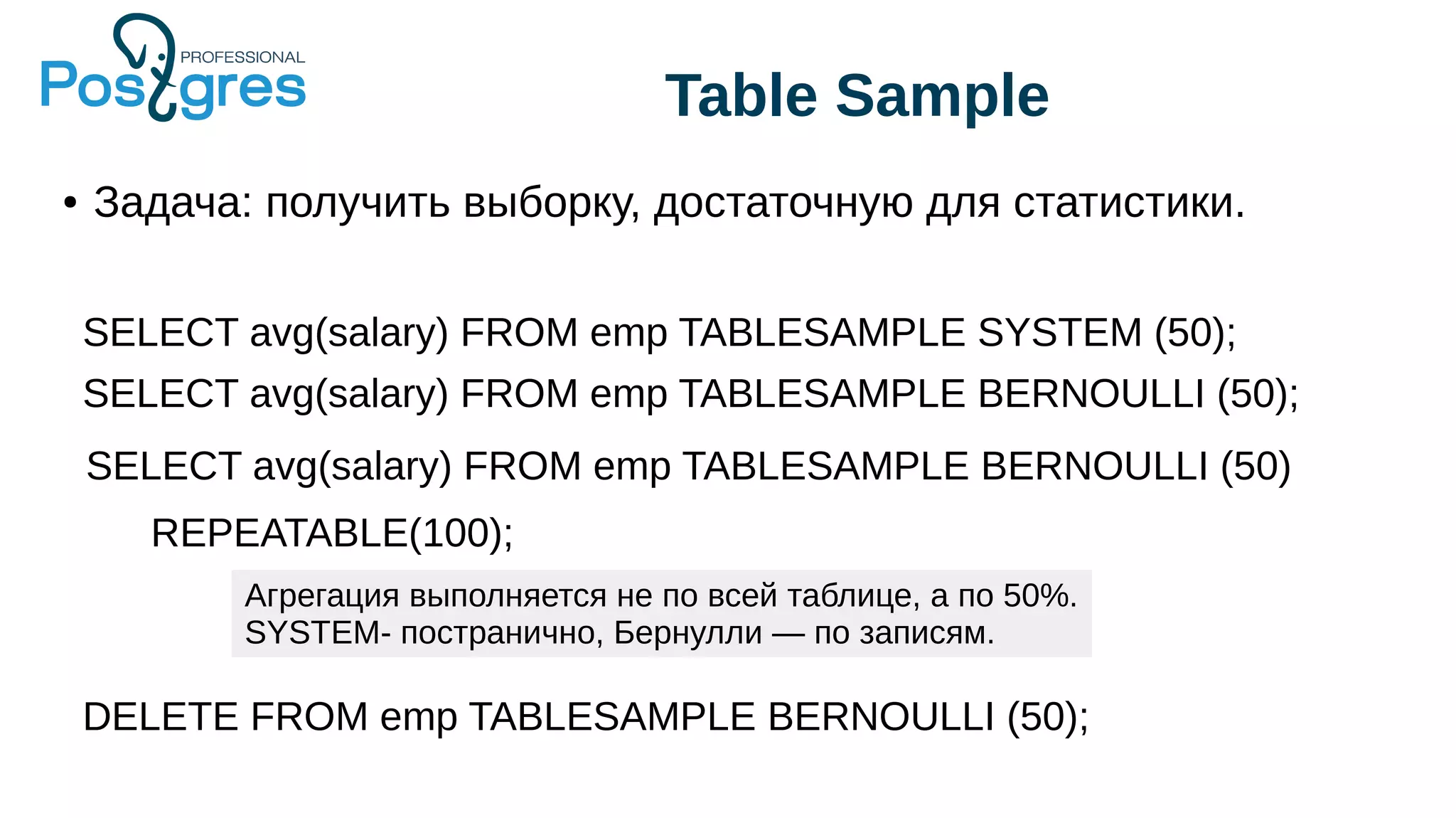



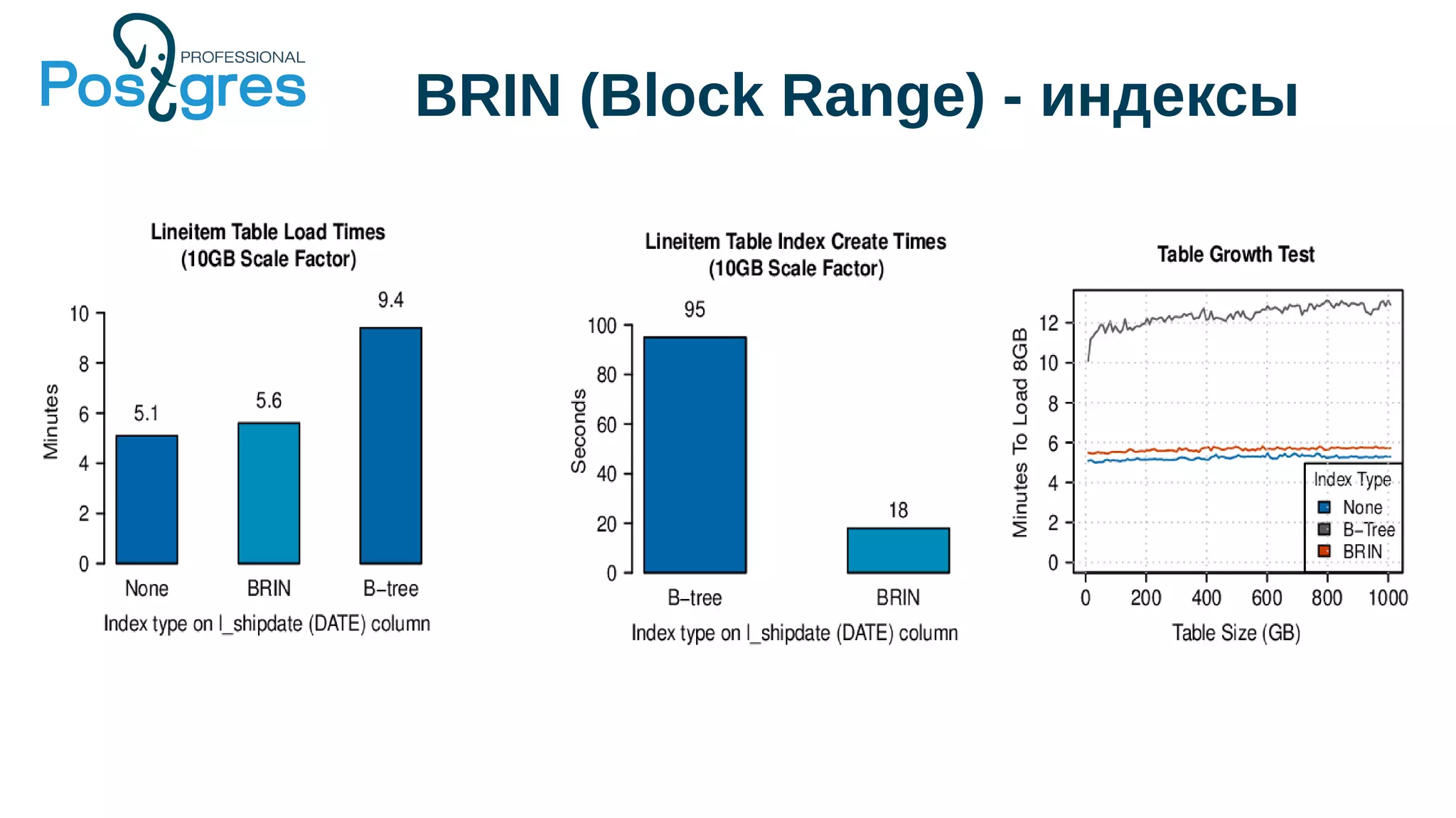


















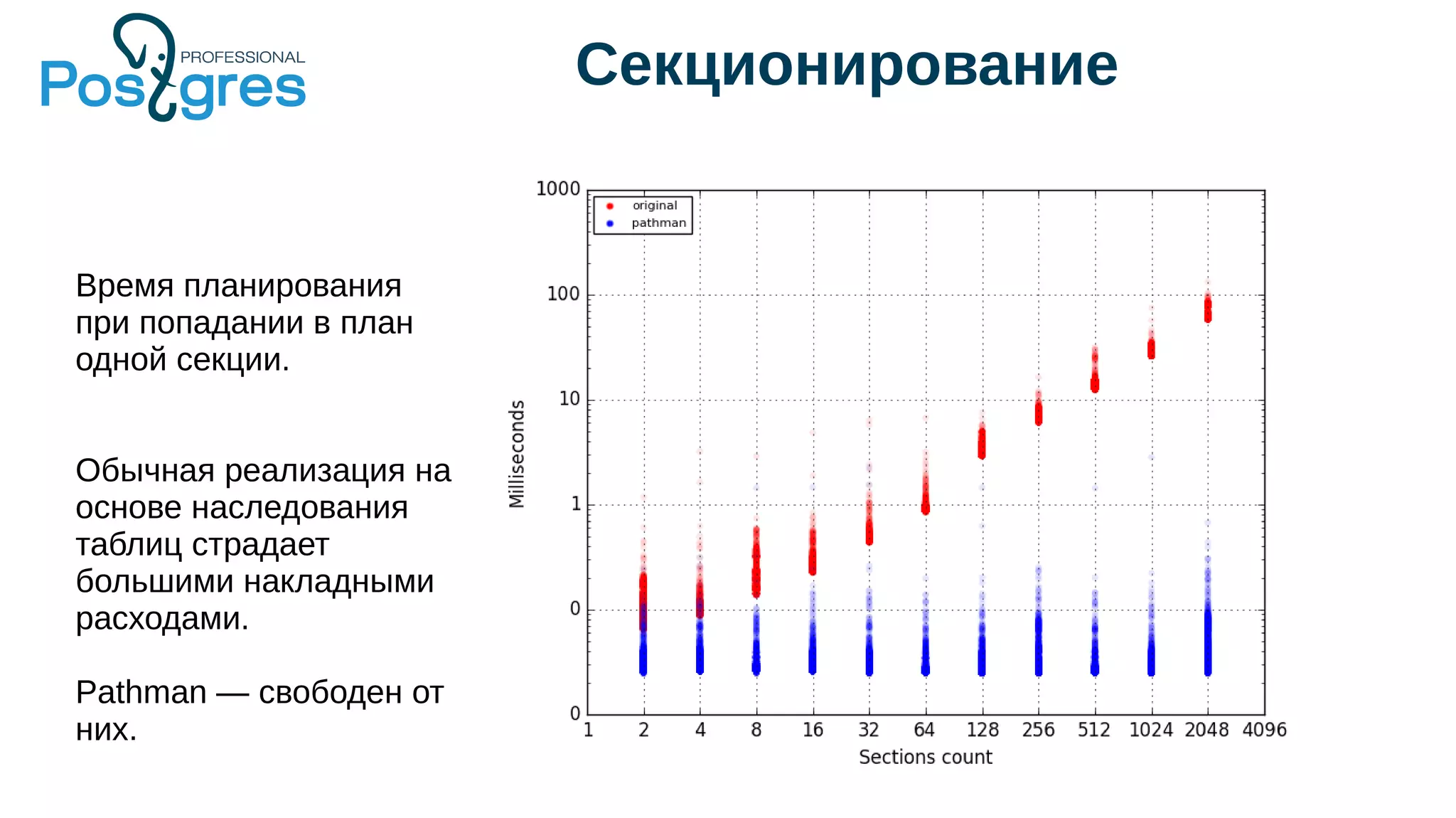
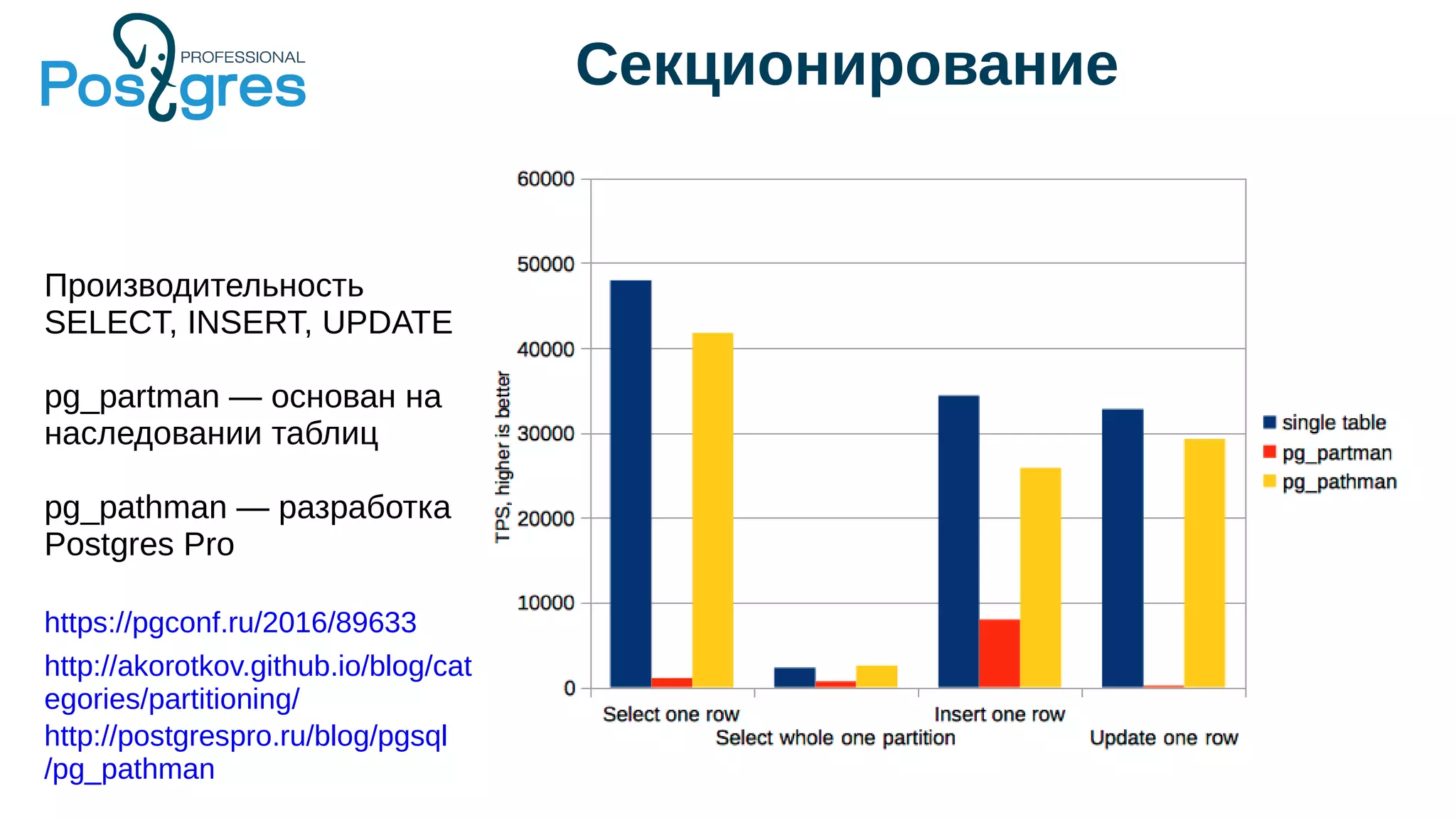


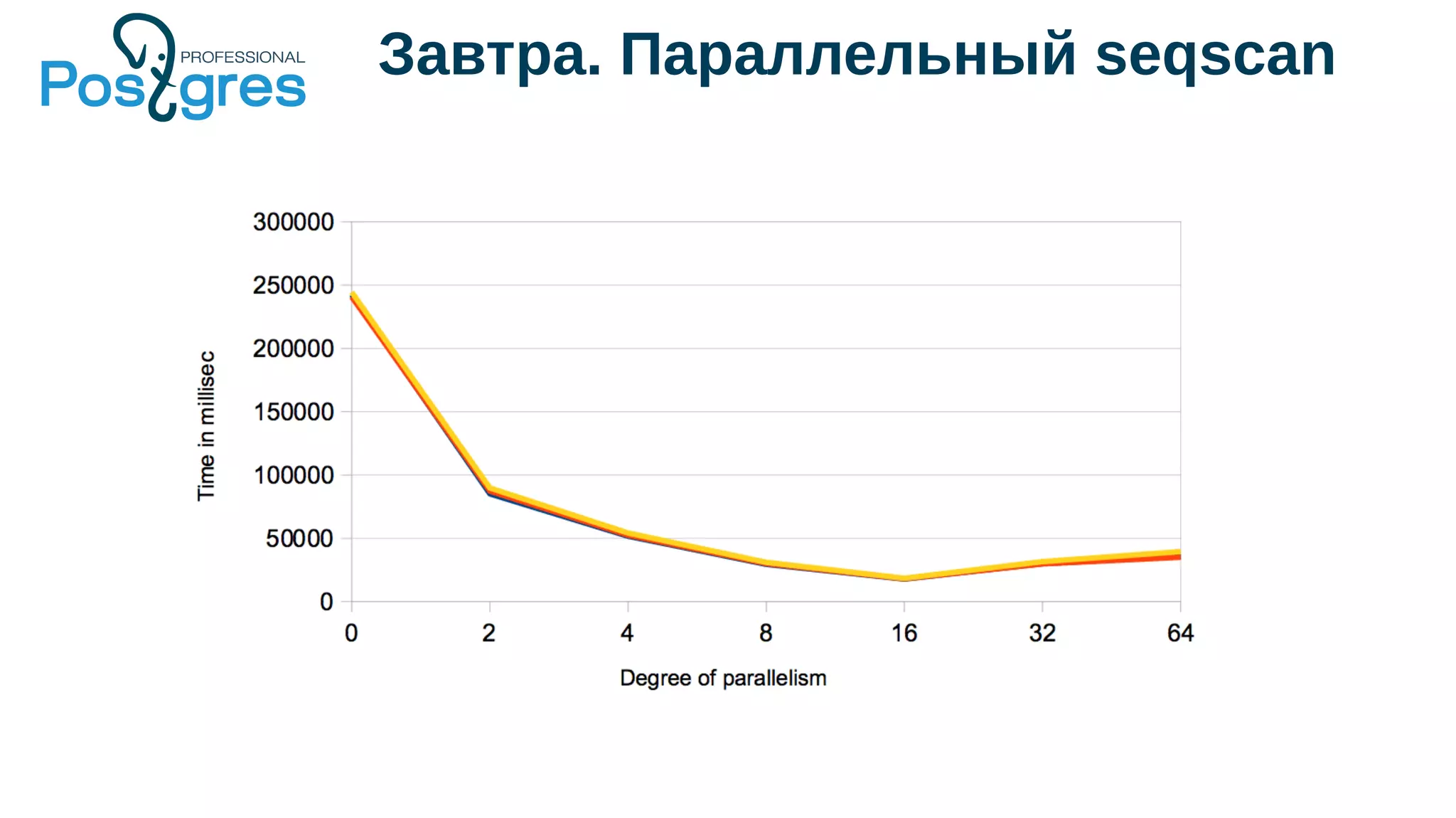
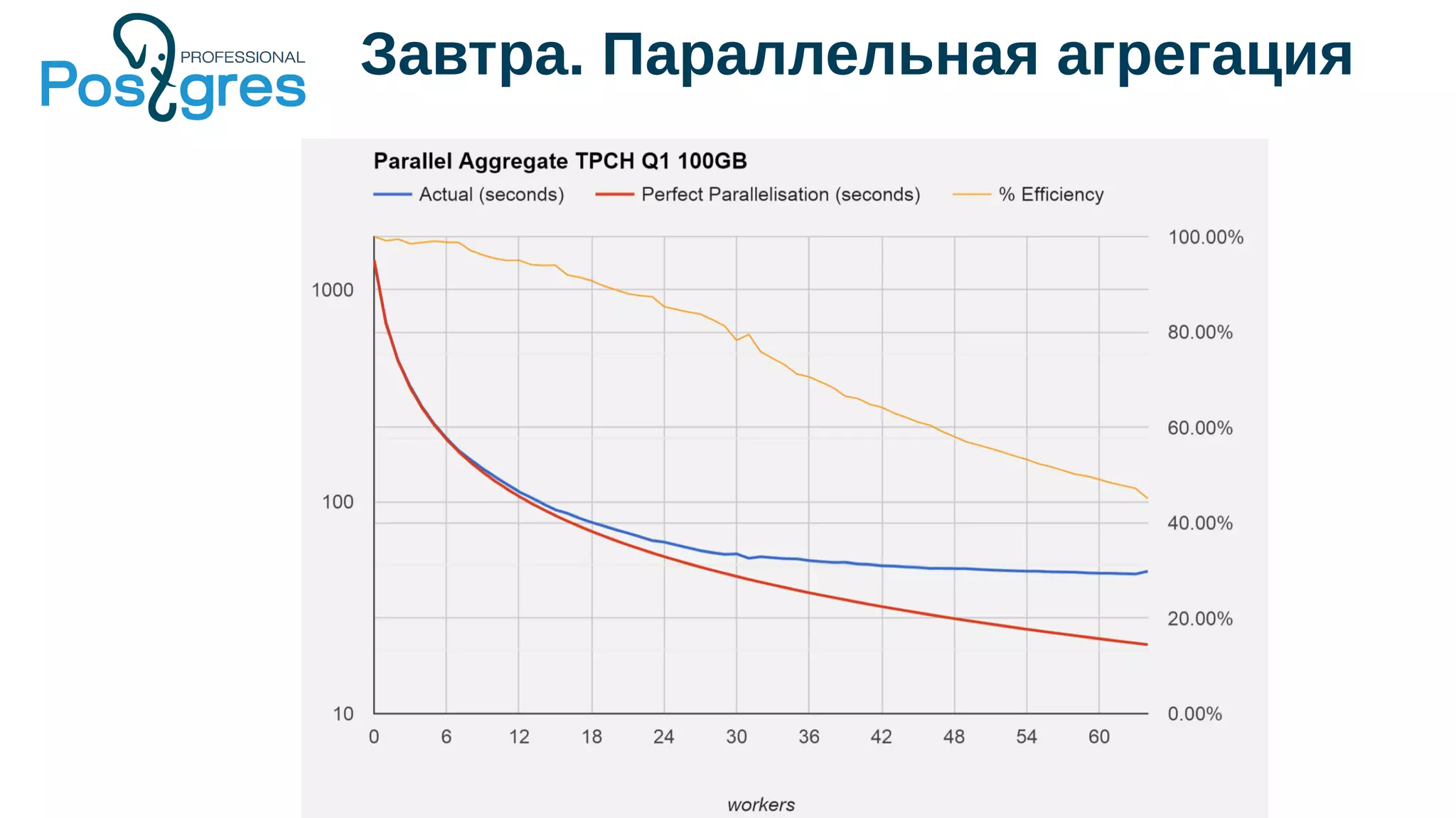


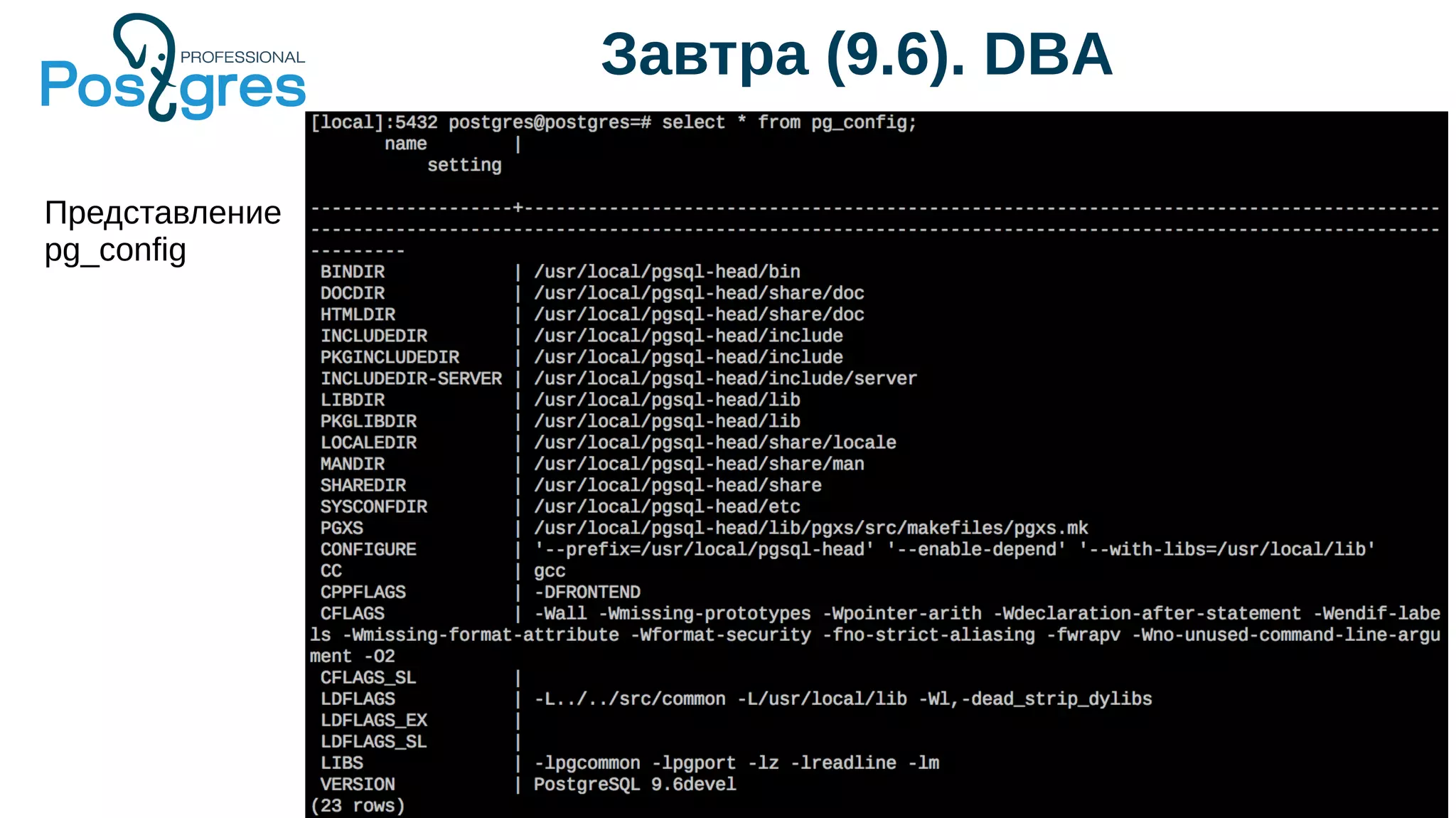
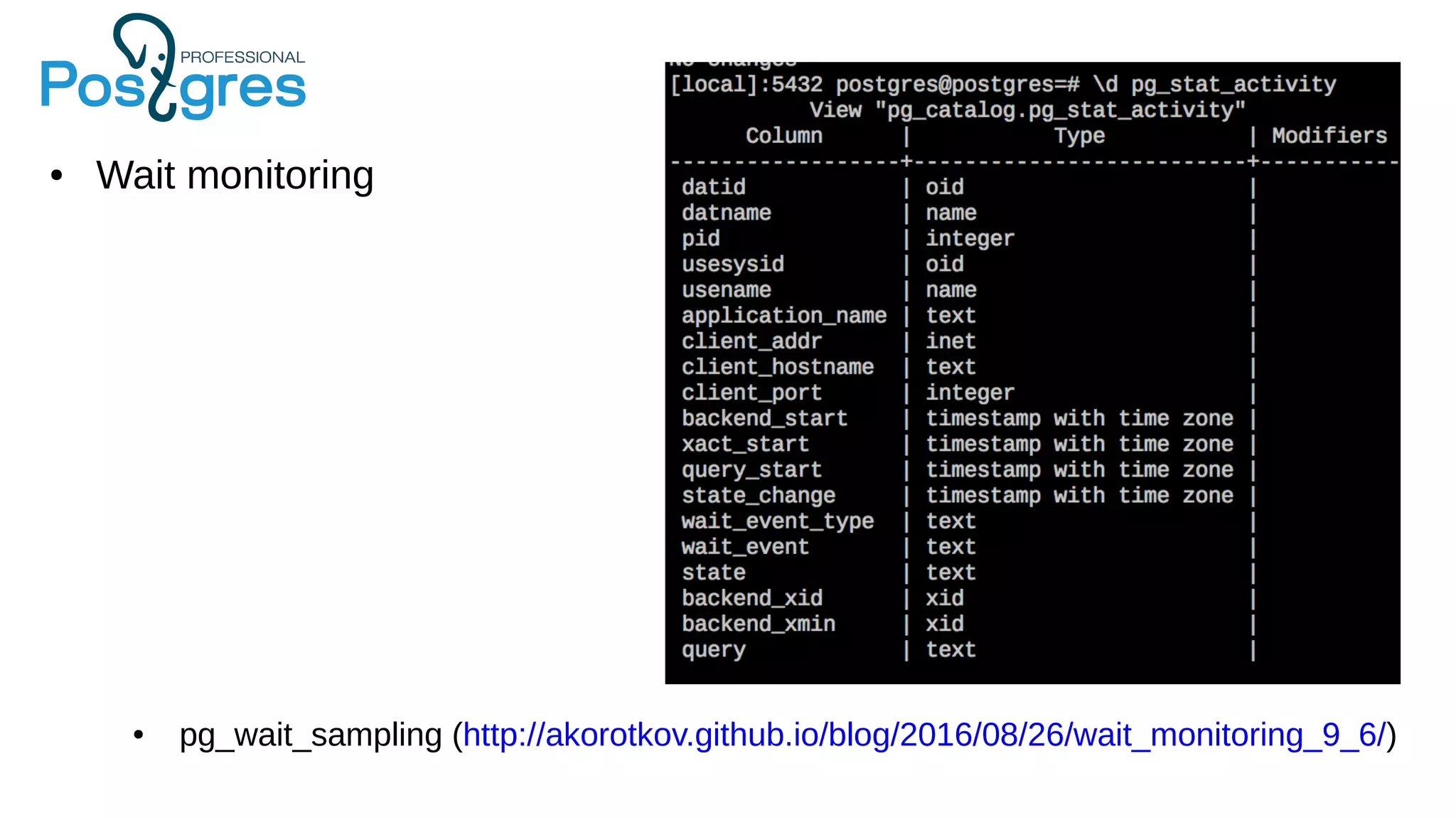





Документ описывает развитие PostgreSQL и его основные форки, а также достижения и новые функции, начиная с версии 9.5. Рассматриваются как исторические аспекты разработки, включая трудности и успехи, так и новые технологии, такие как секционирование, улучшение производительности и функции JSONB. В нем также упомянуто о внедрении и поддержке PostgreSQL Pro как российского форка с целью улучшения функциональности и производительности.























































































