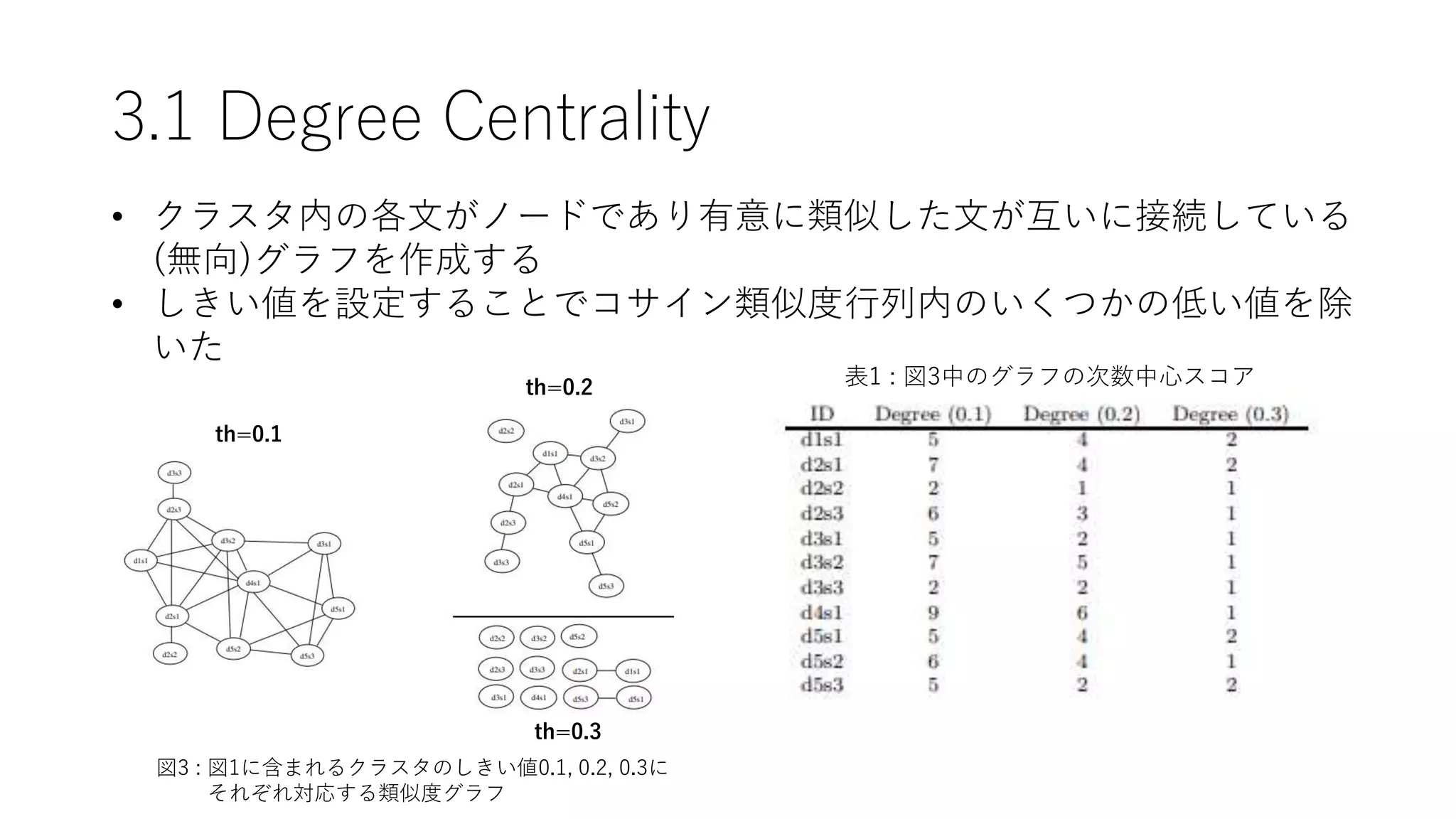
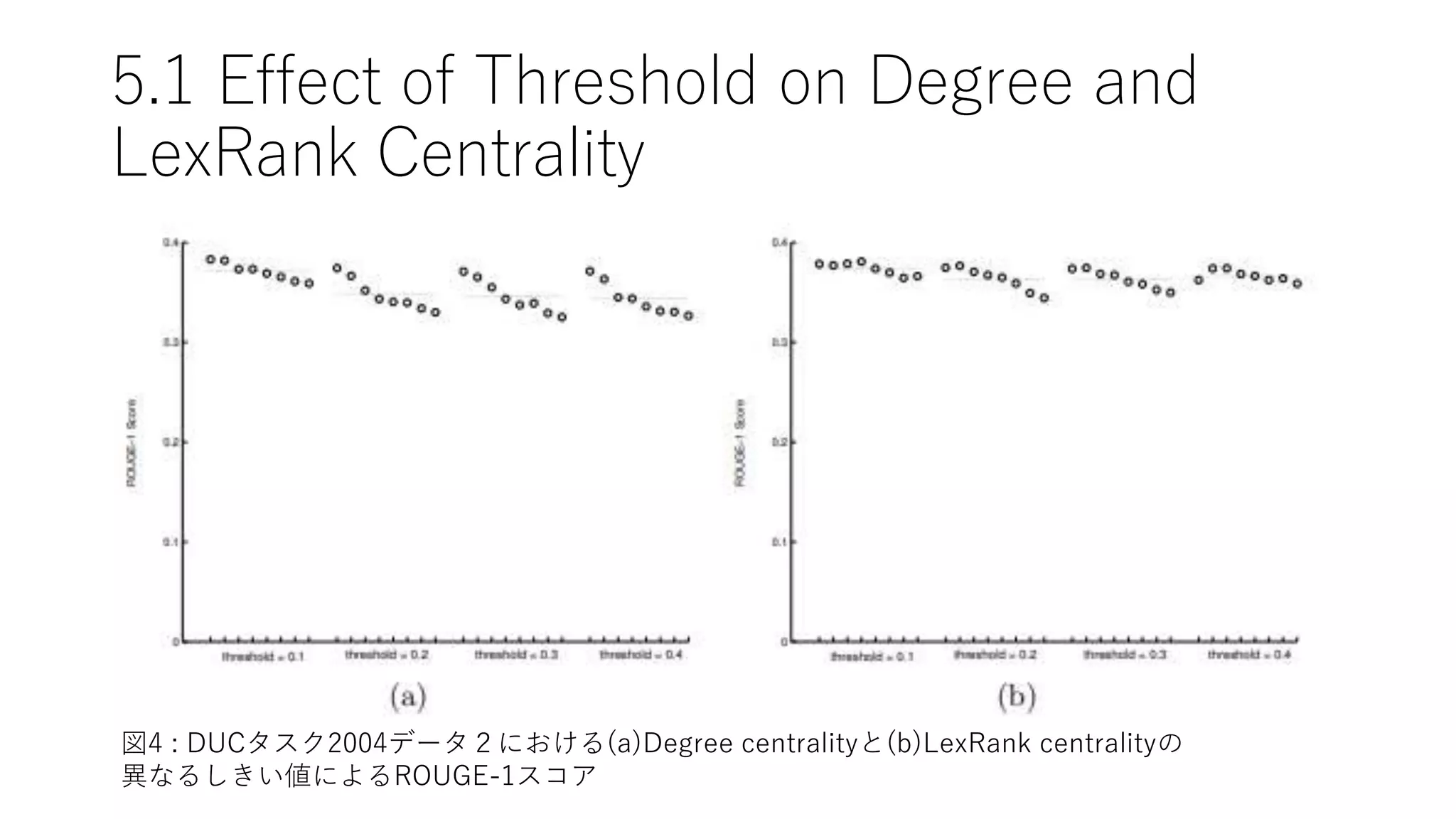
5.1 Effect ofThreshold on Degree and
LexRank Centrality
図4 : DUCタスク2004データ2における(a)Degree centralityと(b)LexRank centralityの
異なるしきい値によるROUGE-1スコア
15.
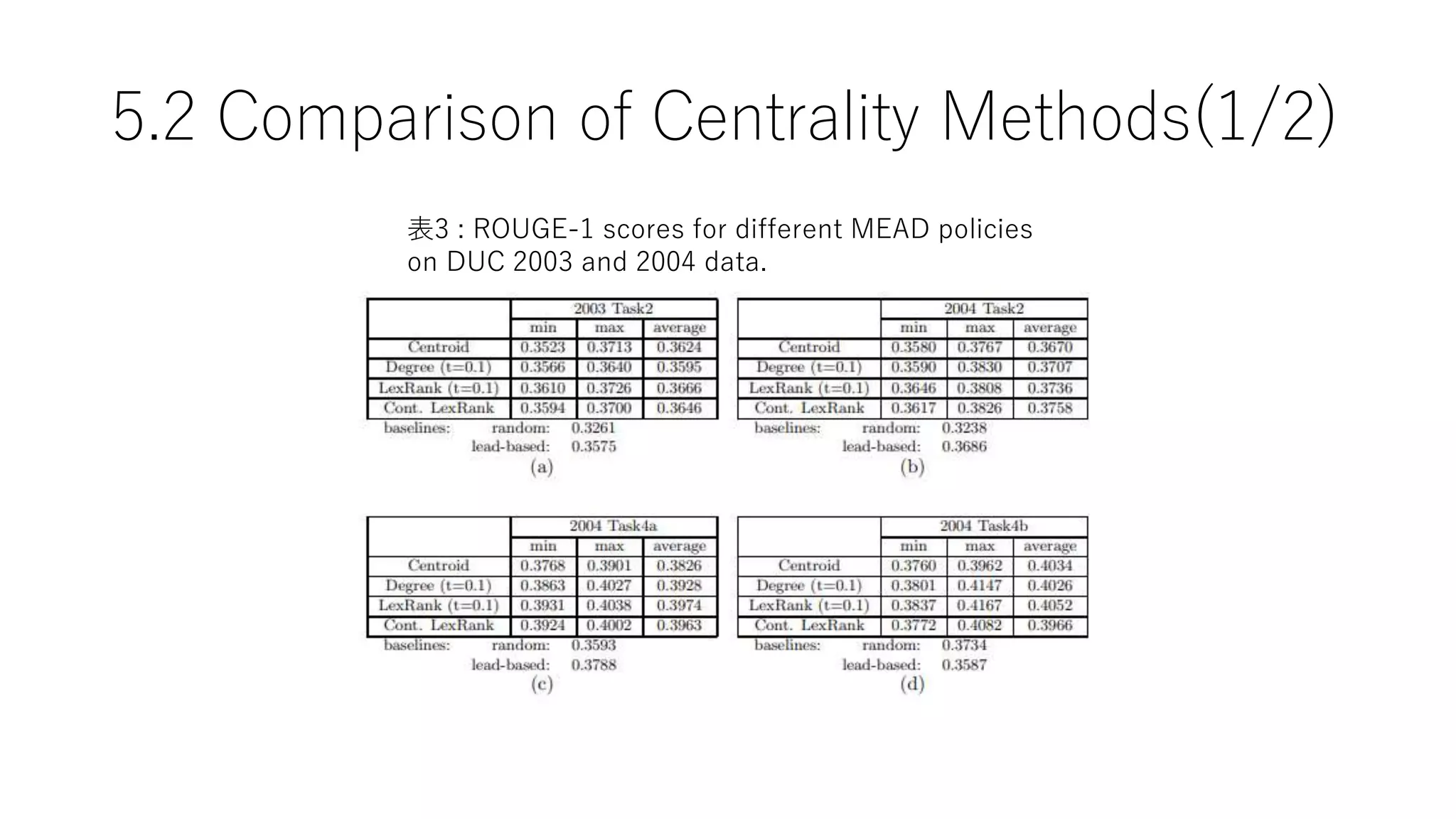
5.2 Comparison ofCentrality Methods(1/2)
表3 : ROUGE-1 scores for different MEAD policies
on DUC 2003 and 2004 data.
16.
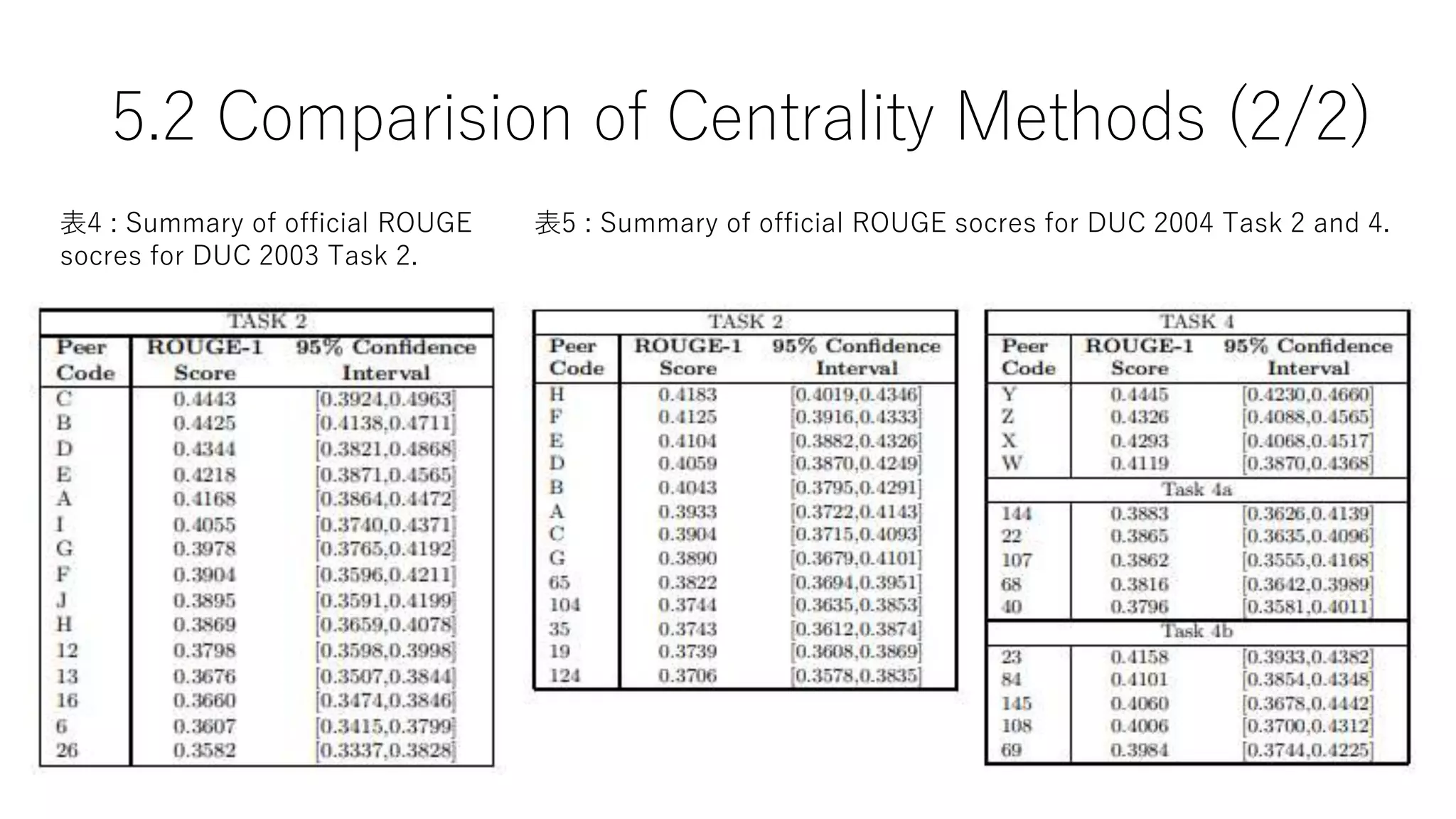
5.2 Comparision ofCentrality Methods (2/2)
表4 : Summary of official ROUGE
socres for DUC 2003 Task 2.
表5 : Summary of official ROUGE socres for DUC 2004 Task 2 and 4.
17.
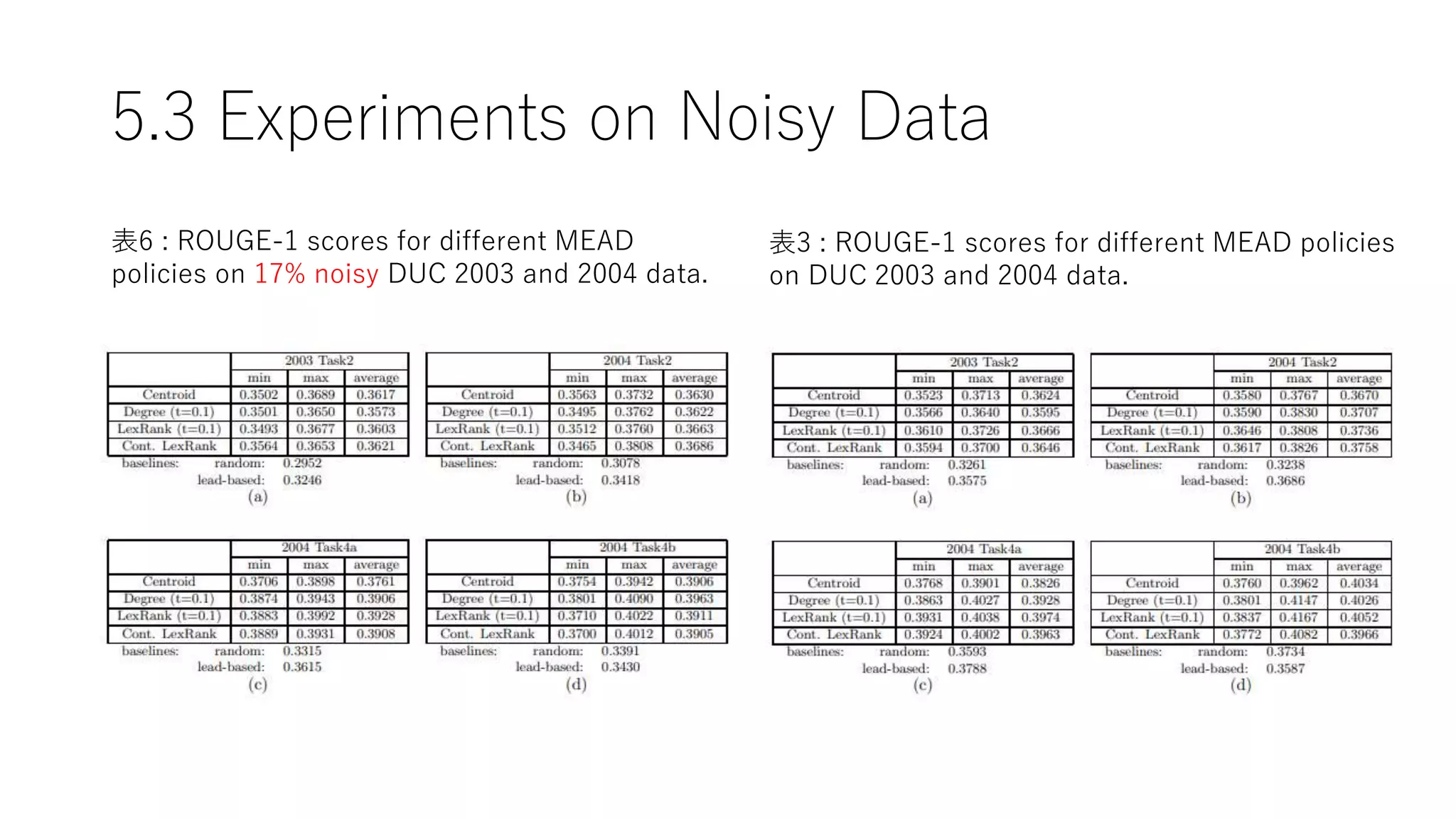
5.3 Experiments onNoisy Data
表6 : ROUGE-1 scores for different MEAD
policies on 17% noisy DUC 2003 and 2004 data.
表3 : ROUGE-1 scores for different MEAD policies
on DUC 2003 and 2004 data.
18.
6. Related Work
•Salton et al. (1997)
単一文書のテキスト要約にdegree Centralityを利用する最初の試み
• Moens, Uyttendaele, and Dumortier (1999)
文のコサイン類似度を用いてテキストを異なるトピック領域に
クラスタリングする
• Zha (2002)
用語の集合から文の集合まで2部グラフを定義する
• Mihalcea and Tarau (2004)
重み付きグラフにおける固有ベクトル中心性アルゴリズムを
単一文章要約のために提案する
• Mihalcea, Tarau, and Figa (2004)
PageRankを自然言語処理の別の問題である語義曖昧性解消に適用する