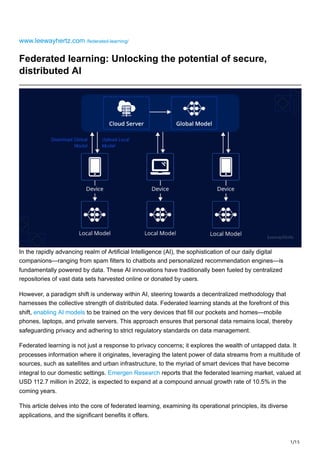
Federated learning is a decentralized machine learning approach that enables collaborative model training on individual devices while keeping data local to uphold privacy. This technique addresses privacy concerns by allowing client devices to train on their local datasets and share model updates instead of raw data. The federated learning market is projected to grow significantly, driven by increasing demand for privacy-preserving AI solutions across various industries.










![12/15
Plain text
Copy to clipboard
Open code in new window
EnlighterJS 3 Syntax Highlighter
# A fixed vocabularly of ASCII chars that occur in the works of Shakespeare and Dickens:
vocab = list('dhlptx@DHLPTX $(,048cgkoswCGKOSW[_#'/37;?
bfjnrvzBFJNRVZ"&*.26:naeimquyAEIMQUY]!%)-159r')
# Creating a mapping from unique characters to indices
char2idx = {u:i for i, u in enumerate(vocab)}
idx2char = np.array(vocab)
# A fixed vocabularly of ASCII chars that occur in the works of Shakespeare and Dickens: vocab =
list('dhlptx@DHLPTX $(,048cgkoswCGKOSW[_#'/37;?
bfjnrvzBFJNRVZ"&*.26:naeimquyAEIMQUY]!%)-159r') # Creating a mapping from unique characters to
indices char2idx = {u:i for i, u in enumerate(vocab)} idx2char = np.array(vocab)
# A fixed vocabularly of ASCII chars that occur in the works of Shakespeare
and Dickens:
vocab = list('dhlptx@DHLPTX $(,048cgkoswCGKOSW[_#'/37;?
bfjnrvzBFJNRVZ"&*.26:naeimquyAEIMQUY]!%)-159r')
# Creating a mapping from unique characters to indices
char2idx = {u:i for i, u in enumerate(vocab)}
idx2char = np.array(vocab)
Load the pre-trained model and generate some text
Plain text
Copy to clipboard
Open code in new window
EnlighterJS 3 Syntax Highlighter
def load_model(batch_size):
urls = {
1: 'https://storage.googleapis.com/tff-models-public/dickens_rnn.batch1.kerasmodel',
8: 'https://storage.googleapis.com/tff-models-public/dickens_rnn.batch8.kerasmodel'}
assert batch_size in urls, 'batch_size must be in ' + str(urls.keys())
url = urls[batch_size]
local_file = tf.keras.utils.get_file(os.path.basename(url), origin=url)
return tf.keras.models.load_model(local_file, compile=False)
def load_model(batch_size): urls = { 1: 'https://storage.googleapis.com/tff-models-
public/dickens_rnn.batch1.kerasmodel', 8: 'https://storage.googleapis.com/tff-models-
public/dickens_rnn.batch8.kerasmodel'} assert batch_size in urls, 'batch_size must be in ' +
str(urls.keys()) url = urls[batch_size] local_file = tf.keras.utils.get_file(os.path.basename(url), origin=url)
return tf.keras.models.load_model(local_file, compile=False)
def load_model(batch_size):
urls = {
1: 'https://storage.googleapis.com/tff-models-](https://image.slidesharecdn.com/leewayhertz-240208152214-4028148a/85/leewayhertz-com-Federated-learning-Unlocking-the-potential-of-secure-distributed-AI-pdf-12-320.jpg)
![13/15
public/dickens_rnn.batch1.kerasmodel',
8: 'https://storage.googleapis.com/tff-models-
public/dickens_rnn.batch8.kerasmodel'}
assert batch_size in urls, 'batch_size must be in ' + str(urls.keys())
url = urls[batch_size]
local_file = tf.keras.utils.get_file(os.path.basename(url), origin=url)
return tf.keras.models.load_model(local_file, compile=False)
Plain text
Copy to clipboard
Open code in new window
EnlighterJS 3 Syntax Highlighter
def generate_text(model, start_string):
# From https://www.tensorflow.org/tutorials/sequences/text_generation
num_generate = 200
input_eval = [char2idx[s] for s in start_string]
input_eval = tf.expand_dims(input_eval, 0)
text_generated = []
temperature = 1.0
model.reset_states()
for i in range(num_generate):
predictions = model(input_eval)
predictions = tf.squeeze(predictions, 0)
predictions = predictions / temperature
predicted_id = tf.random.categorical(
predictions, num_samples=1)[-1, 0].numpy()
input_eval = tf.expand_dims([predicted_id], 0)
text_generated.append(idx2char[predicted_id])
return (start_string + ''.join(text_generated))
def generate_text(model, start_string): # From
https://www.tensorflow.org/tutorials/sequences/text_generation num_generate = 200 input_eval =
[char2idx[s] for s in start_string] input_eval = tf.expand_dims(input_eval, 0) text_generated = []
temperature = 1.0 model.reset_states() for i in range(num_generate): predictions = model(input_eval)
predictions = tf.squeeze(predictions, 0) predictions = predictions / temperature predicted_id =
tf.random.categorical( predictions, num_samples=1)[-1, 0].numpy() input_eval =
tf.expand_dims([predicted_id], 0) text_generated.append(idx2char[predicted_id]) return (start_string +
''.join(text_generated))
def generate_text(model, start_string):
# From https://www.tensorflow.org/tutorials/sequences/text_generation
num_generate = 200
input_eval = [char2idx[s] for s in start_string]
input_eval = tf.expand_dims(input_eval, 0)
text_generated = []
temperature = 1.0](https://image.slidesharecdn.com/leewayhertz-240208152214-4028148a/85/leewayhertz-com-Federated-learning-Unlocking-the-potential-of-secure-distributed-AI-pdf-13-320.jpg)
![14/15
model.reset_states()
for i in range(num_generate):
predictions = model(input_eval)
predictions = tf.squeeze(predictions, 0)
predictions = predictions / temperature
predicted_id = tf.random.categorical(
predictions, num_samples=1)[-1, 0].numpy()
input_eval = tf.expand_dims([predicted_id], 0)
text_generated.append(idx2char[predicted_id])
return (start_string + ''.join(text_generated))
Plain text
Copy to clipboard
Open code in new window
EnlighterJS 3 Syntax Highlighter
# Text generation requires a batch_size=1 model.
keras_model_batch1 = load_model(batch_size=1)
print(generate_text(keras_model_batch1, 'What of TensorFlow Federated, you ask? '))
# Text generation requires a batch_size=1 model. keras_model_batch1 = load_model(batch_size=1)
print(generate_text(keras_model_batch1, 'What of TensorFlow Federated, you ask? '))
# Text generation requires a batch_size=1 model.
keras_model_batch1 = load_model(batch_size=1)
print(generate_text(keras_model_batch1, 'What of TensorFlow Federated, you
ask? '))
You can utilize the code provided in the TensorFlow article, which covers the entire process from loading
the pre-trained model to implementing federated learning.
Use cases of federated learning
Federated learning has made significant inroads across various industries, offering privacy-preserving
and collaborative training opportunities. Let’s explore some of the most common applications:
Mobile applications: Federated learning is well-suited for mobile applications, enabling the
enhancement of user-centric features while preserving data privacy. By processing data on the users’
devices and only exchanging model improvements, this approach allows for the advancement of
personalized experiences such as tailored recommendations, adaptive keyboards, and responsive voice
assistants, all without exporting personal data from the device.
Transportation: Self-driving cars heavily rely on computer vision and machine learning to analyze real-
time surroundings and adapt to dynamic environments. Federated learning enables these models to
continuously improve and enhance precision by learning from diverse datasets. This decentralized
approach enables faster learning and robust model development.
Manufacturing: In manufacturing, federated learning can significantly enhance predictive analytics and
operational efficiency. By utilizing data across a broad network of sensors and devices without](https://image.slidesharecdn.com/leewayhertz-240208152214-4028148a/85/leewayhertz-com-Federated-learning-Unlocking-the-potential-of-secure-distributed-AI-pdf-14-320.jpg)




































































