Downloaded 173 times






![A recursive procedure
Algorithm BinarySearch(A, k, low, high)
if low > high then return Nil
else mid (low+high) / 2
if k = A[mid] then return mid
elseif k < A[mid] then
return BinarySearch(A, k, low, mid-1)
else return BinarySearch(A, k, mid+1, high)
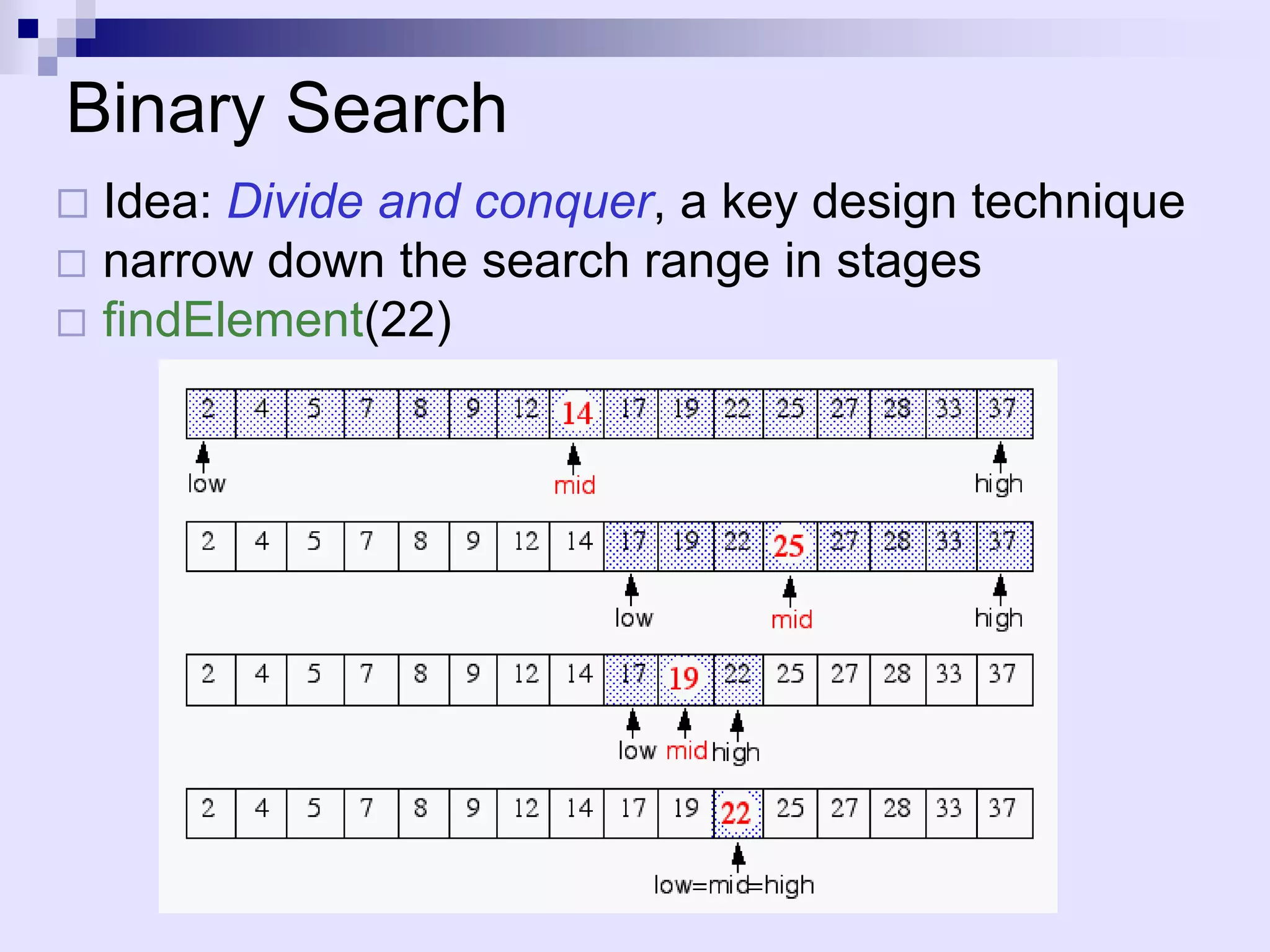
2 4 5 7 8 9 12 14 17 19 22 25 27 28 33 37
low mid high
2 4 5 7 8 9 12 14 17 19 22 25 27 28 33 37
low mid high
2 4 5 7 8 9 12 14 17 19 22 25 27 28 33 37
low mid](https://image.slidesharecdn.com/lec4-101217101202-phpapp01/75/Lec4-8-2048.jpg)
![An iterative procedure
INPUT: A[1..n] – a sorted (non-decreasing) array of
integers, key – an integer.
OUTPUT: an index j such that A[j] = k.
NIL, if j (1 j n): A[j] k
2 4 5 7 8 9 12 14 17 19 22 25 27 28 33 37
low 1 low mid high
high n 2 4 5 7 8 9 12 14 17 19 22 25 27 28 33 37
do 2 4 5 7 8 9 12 14
low
17 19 22
mid
25 27 28 33
high
37
mid (low+high)/2 low mid
if A[mid] = k then return mid
else if A[mid] > k then high mid-1
else low mid+1
while low <= high
return NIL](https://image.slidesharecdn.com/lec4-101217101202-phpapp01/75/Lec4-9-2048.jpg)

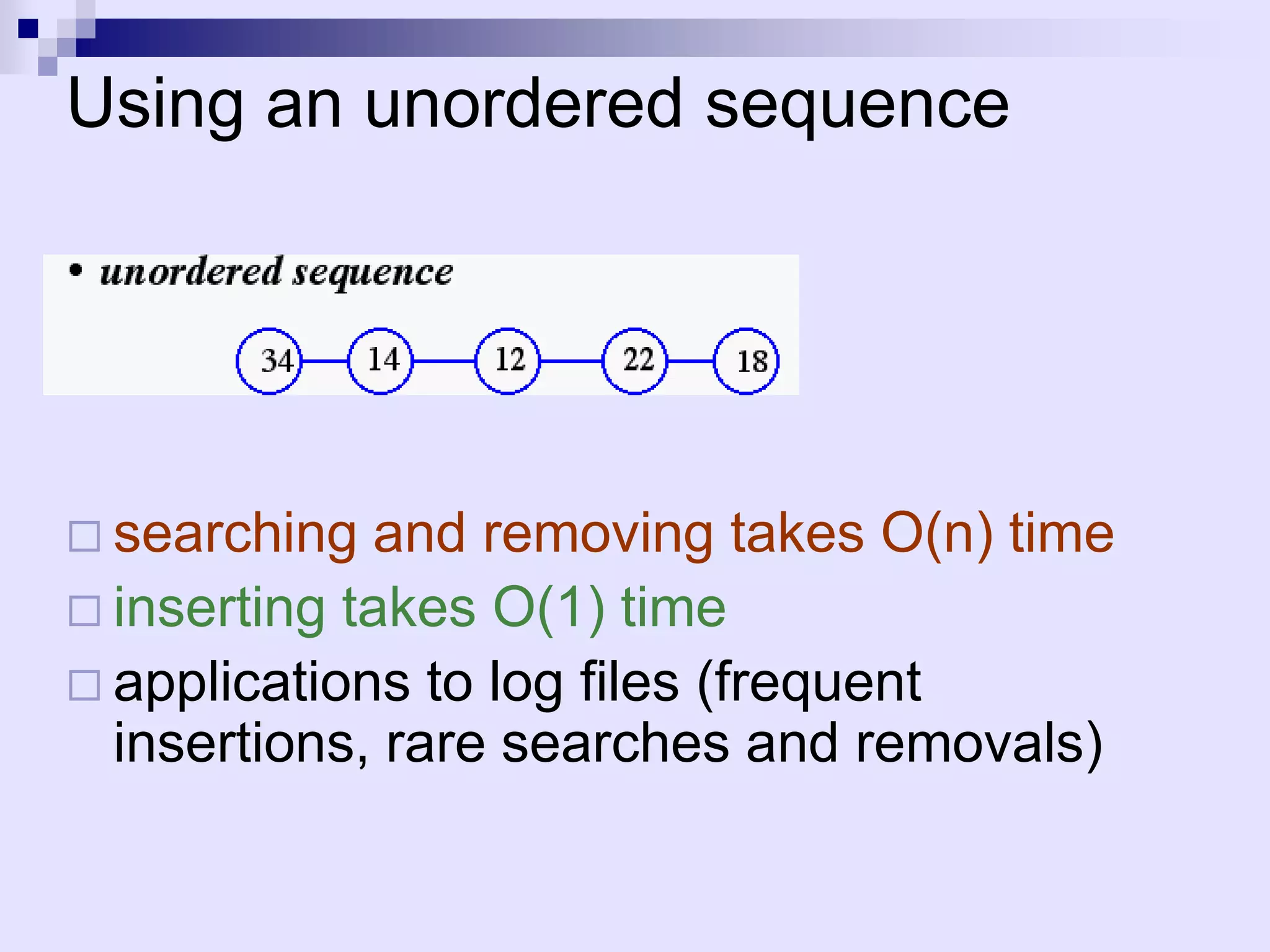
![Searching in an unsorted array
INPUT: A[1..n] – an array of integers, q – an integer.
OUTPUT: an index j such that A[j] = q. NIL, if j (1 j n):
A[j] q
j 1
while j n and A[j] q
do j++
if j n then return j
else return NIL
Worst-case running time: O(n), average-case:
O(n)
We can’t do better. This is a lower bound for the
problem of searching in an arbitrary sequence.](https://image.slidesharecdn.com/lec4-101217101202-phpapp01/75/Lec4-11-2048.jpg)




![Analysis of Hashing
An element with key k is stored in slot
h(k) (instead of slot k without hashing)
The hash function h maps the universe U
of keys into the slots of hash table
T[0...m-1]
h :U 0,1,..., m 1
Assume time to compute h(k) is (1)](https://image.slidesharecdn.com/lec4-101217101202-phpapp01/75/Lec4-20-2048.jpg)






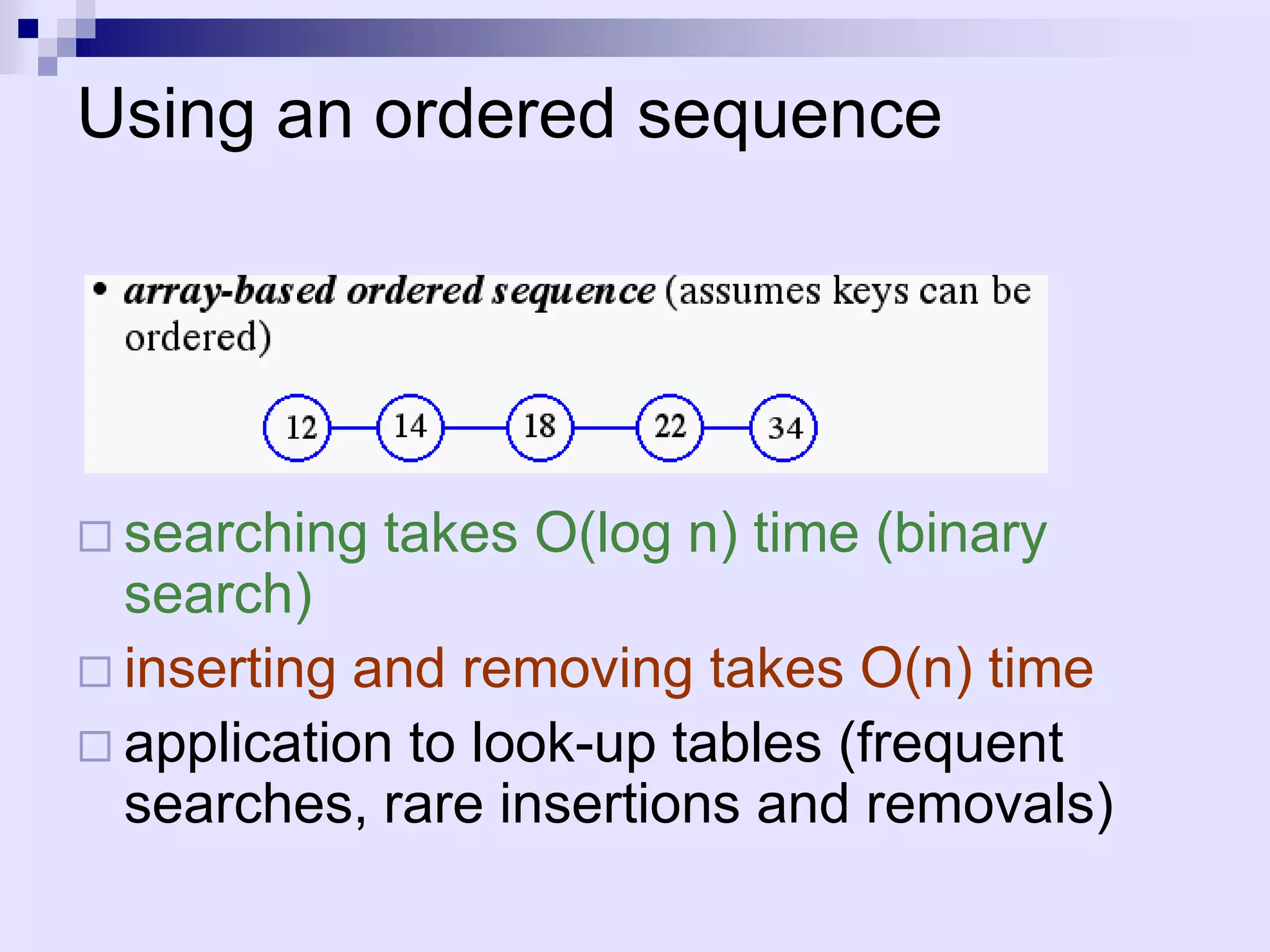
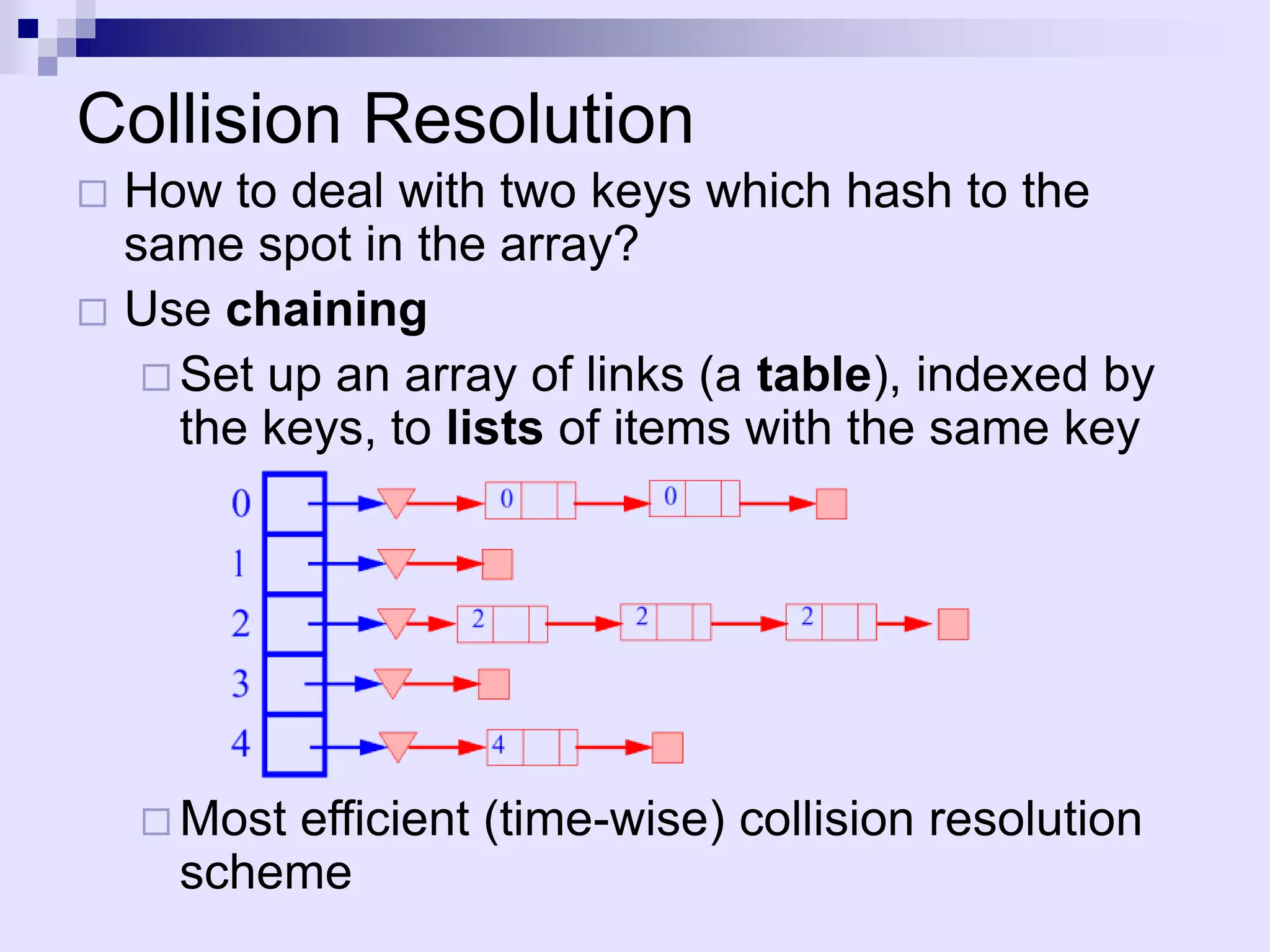
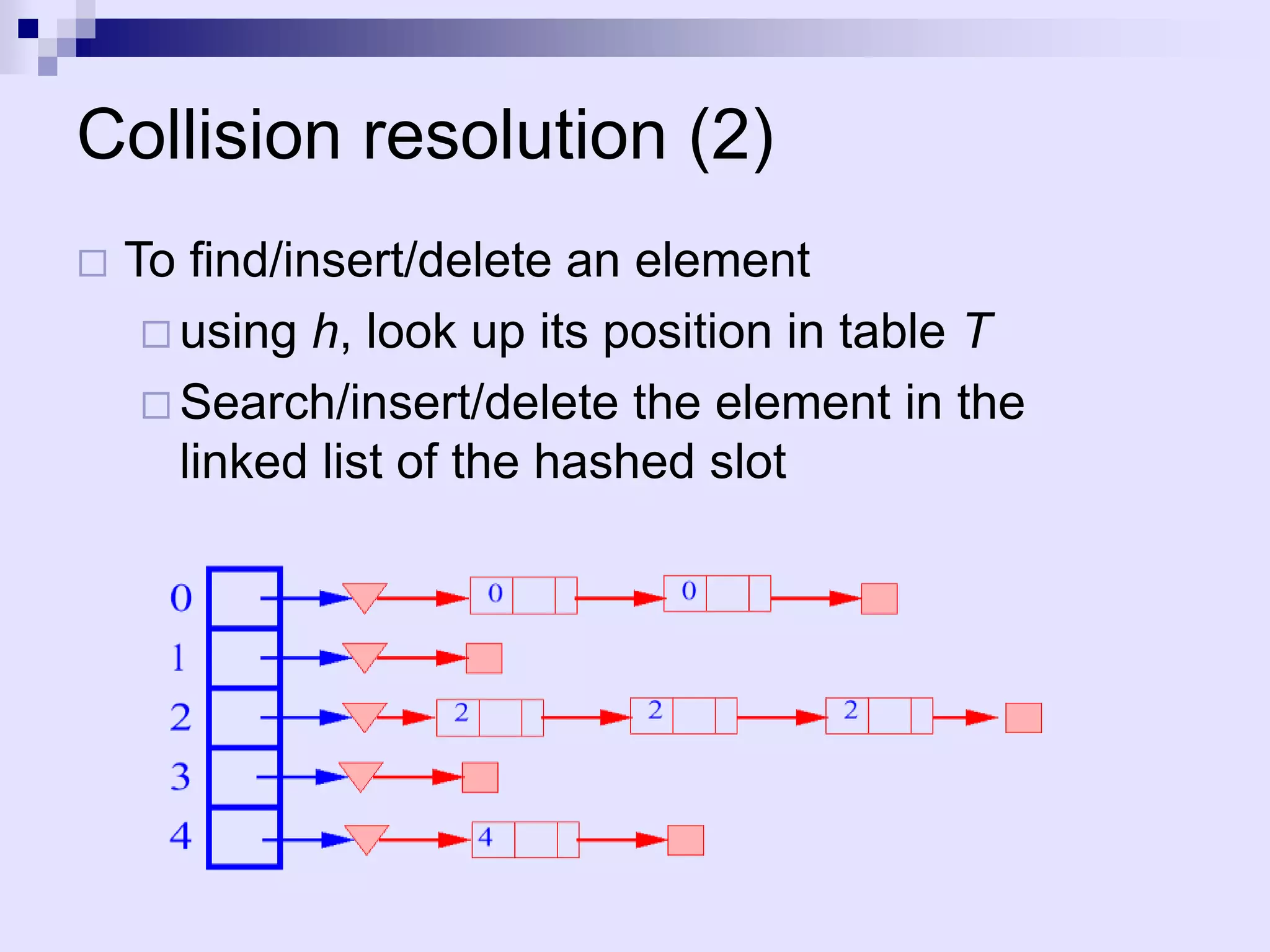
The document discusses dictionaries and different data structures used to implement them efficiently, including hashing. Dictionaries store key-value pairs and support fast retrieval of elements using keys. Hashing is described as an efficient solution to implement dictionaries, where keys are mapped to table slots using a hash function. Hashing provides expected O(1) time for search, insert and delete operations when the load factor is a constant. Collision resolution using chaining is explained, where elements hash to the same slot are stored in a linked list.














































































