Downloaded 65 times



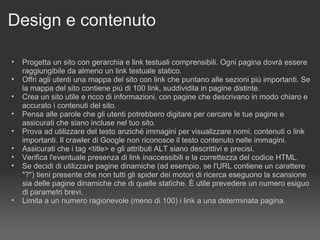
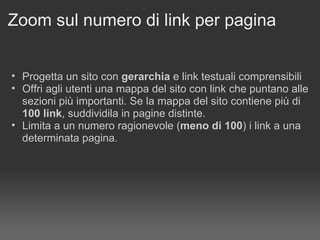
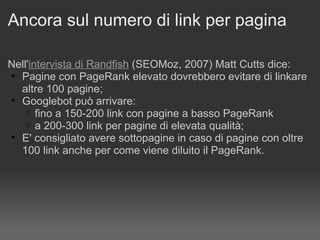

![Megamenu: come evitarlo Riduci il numero di link presenti sul menu Razionalizzi il menu pensando agli utenti Lo aveva detto Matt Cutts nella stessa intervista: The "keep the number of links to under 100" is in the technical guideline section, not the quality guidelines section. That means we're not going to remove a page if you have 101 or 102 links on the page. [...]. Originally, Google only indexed the first 100 kilobytes or so of web documents, so keeping the number of links under 100 was a good way to ensure that all those links would be seen by Google. These days I believe we index deeper within documents, so that's less of an issue. But it is true that if users see 250 or 300 links on a page, that page is probably not as useful for them, so it's a good idea to break a large list of links down (e.g. by category, topic, alphabetically, or chronologically) into multiple pages so that your links don't overwhelm regular users.](https://image.slidesharecdn.com/lepenalizzazionidigoogle-1229431285330525-1/85/Le-Penalizzazioni-Di-Google-8-320.jpg)




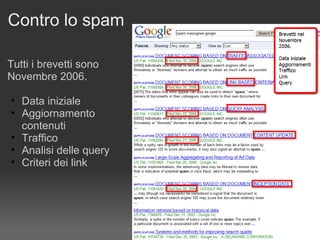

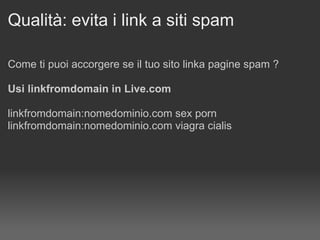
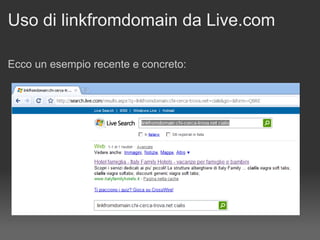
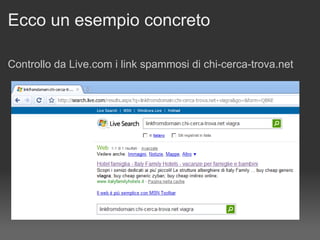
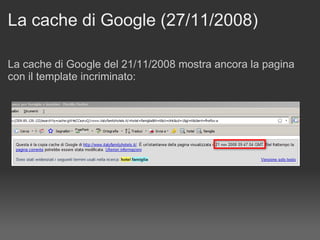
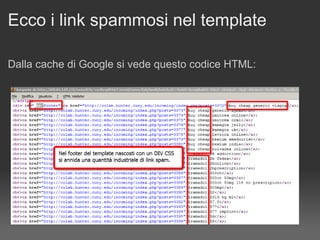
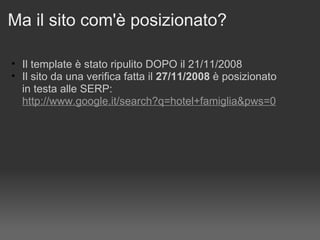
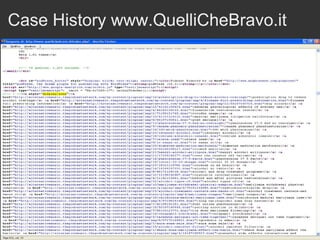




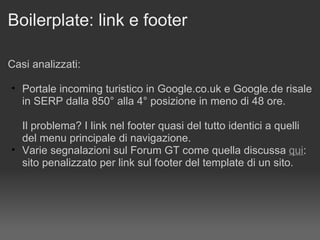








Il documento discute le penalizzazioni di Google e fornisce indicazioni su come creare un sito web di qualità seguendo le linee guida di Google. Sottolinea l'importanza di avere un design ordinato, contenuti utili e limitare il numero di link per pagina per migliorare l'usabilità. Infine, avverte sui rischi associati a link di bassa qualità e duplicati, evidenziando l'evoluzione dell'algoritmo di Google nel trattamento di questi aspetti.






















![+355% traffico organico da Google in 1 anno [Case study SEO]](https://cdn.slidesharecdn.com/ss_thumbnails/355trafficoorganico-casestudyseo-170921105408-thumbnail.jpg?width=640&height=640&fit=bounds)



































