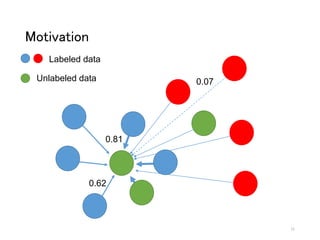
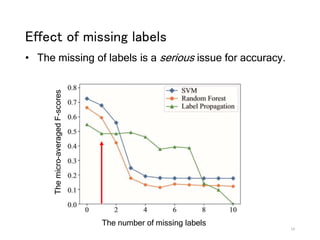
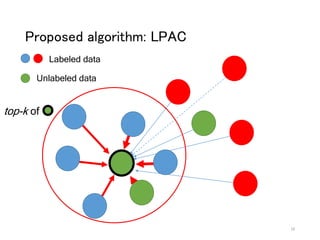
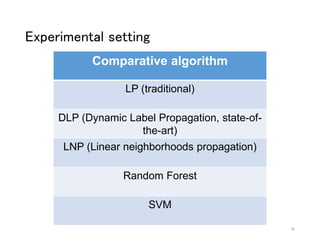
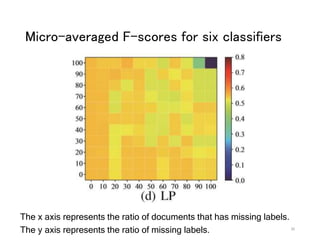
The document discusses a novel approach to label propagation in the context of semi-supervised learning, specifically through a method called amendable clamping (LPAC). This method aims to improve accuracy in multi-label classification by addressing the issues of missing labels, showing a 45% higher performance compared to traditional approaches. The study utilizes the Siam 2007 text mining competition dataset and proposes future work to enhance label correlation utilization and address datasets with incorrect or missing labels.