Download as PDF, PPTX



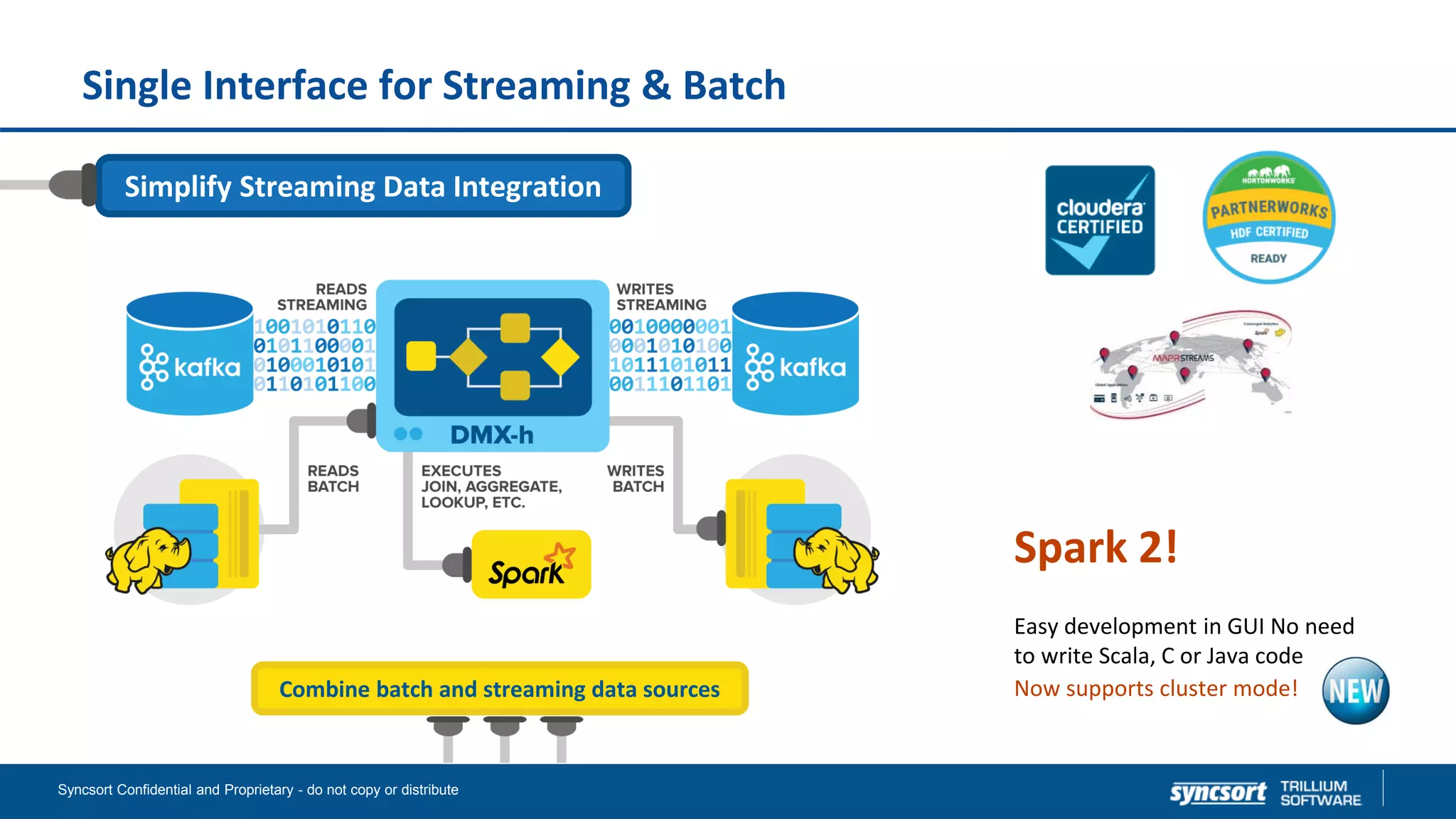
![Progress Monitoring
Track the progress of
DMX/DMX-h jobs as they’re
running!
Settable time intervals
See exactly how fast jobs are running
Know how much memory and CPU jobs
use at any point
Know when there’s a problem, even in
the middle of long-running jobs
5Syncsort Confidential and Proprietary - do not copy or distribute
C:PROGRAM FILESDMEXPRESSPROGRAMSdmsmonitor.exe /jobid J_readVSAM_20171006_001743_13572 /task
T_readVSAM /interactive 2 /logdir .
Timestamp: 2017-10-06 00:19:09
Status: RUNNING for 00:01:28
User: aramachandran
Data directory: C:UsersaramachandranDocumentsProjectsCompanyNameVSAM_test
Memory: 32MB
CPU: 12%
/MVS/WWCDMX/AZR.VSM (Source): 7689557 records [1689372 records/sec], 246065824 bytes [5405992 bytes/sec]
Vsam_out.dat (Target): 7685704 records [1687590 records/sec], 245942528 bytes [54002880 bytes/sec]
C:PROGRAM FILESDMEXPRESSPROGRAMSdmsmonitor.exe /jobid J_readVSAM_20171006_001743_13572 /task
T_readVSAM /interactive 2 /logdir .
Timestamp: 2017-10-06 00:19:11
Status: RUNNING for 00:01:30
User: aramachandran
Data directory: C:UsersaramachandranDocumentsProjectsCompanyNameVSAM_test
Memory: 32MB
CPU: 12%
/MVS/WWCDMX/AZR.VSM (Source): 10718776 records [1514609 records/sec], 343000832 bytes [48467504 bytes/sec]
Vsam_out.dat (Target): 10716748 records [1515522 records/sec], 342935936 bytes [48496704 bytes/sec]](https://image.slidesharecdn.com/hadoopwebcast-keeping-data-in-sync-with-syncsort-120717pdf-171207170356/75/Keeping-Data-in-Sync-with-Syncsort-5-2048.jpg)



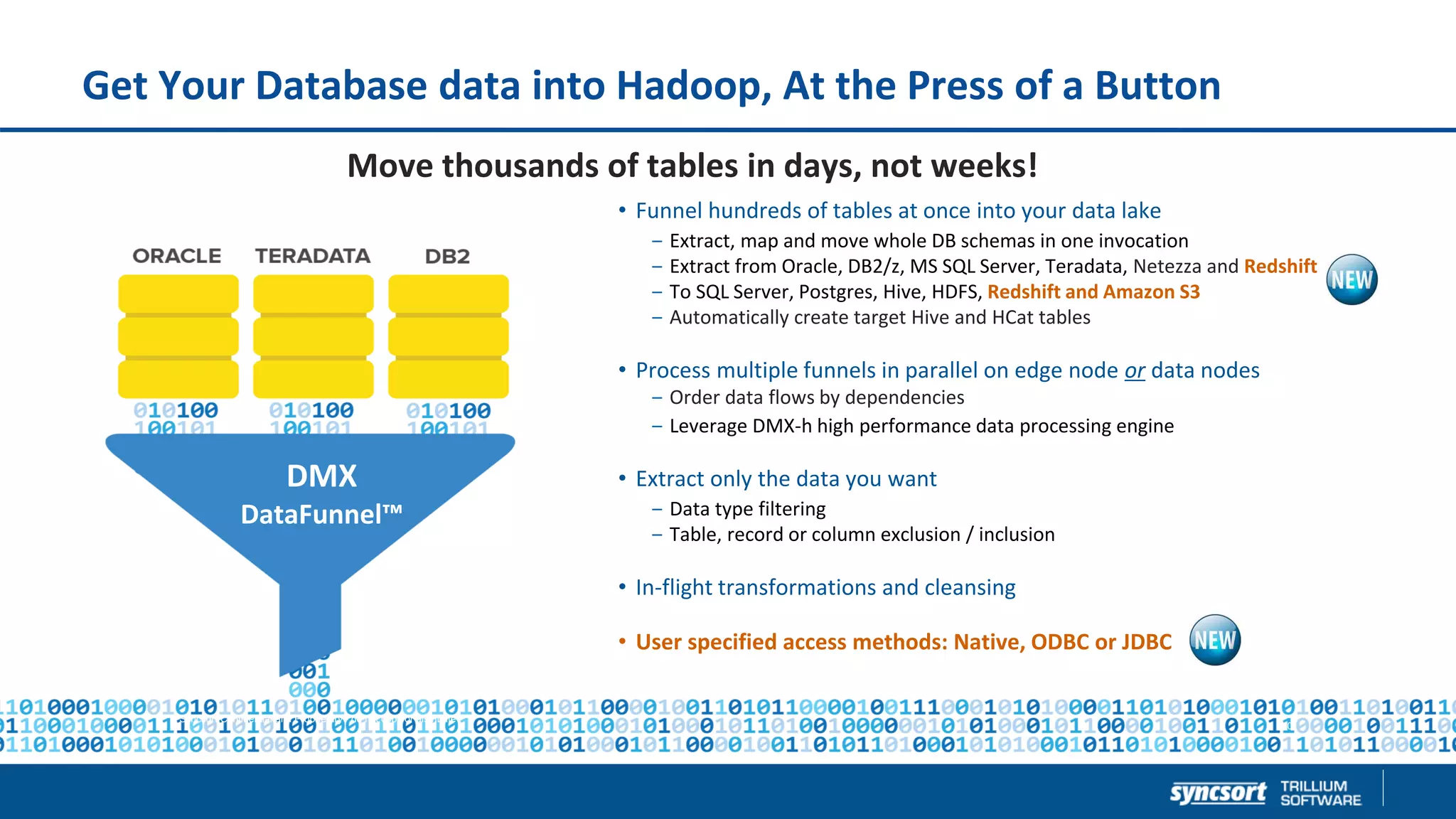
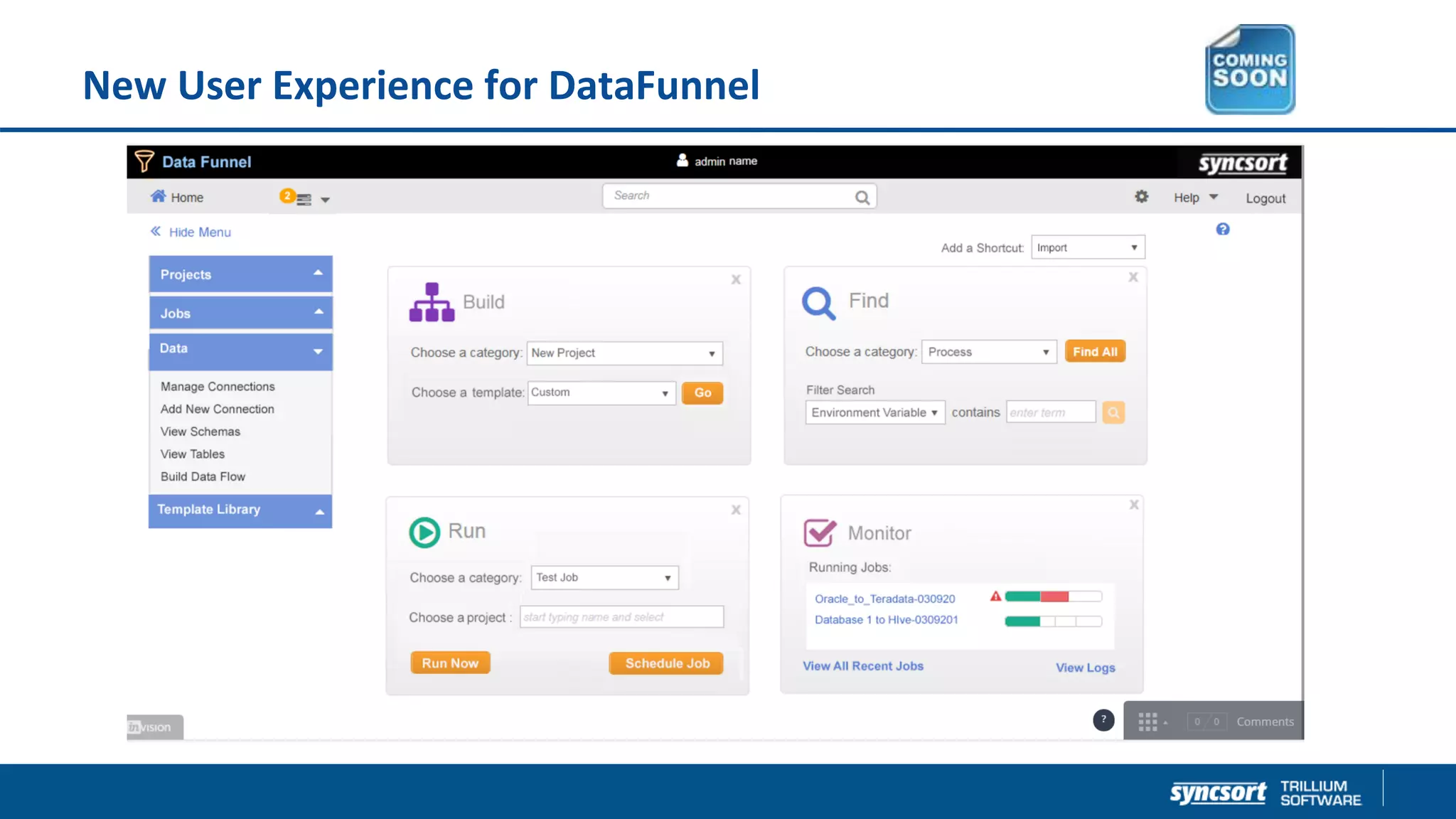
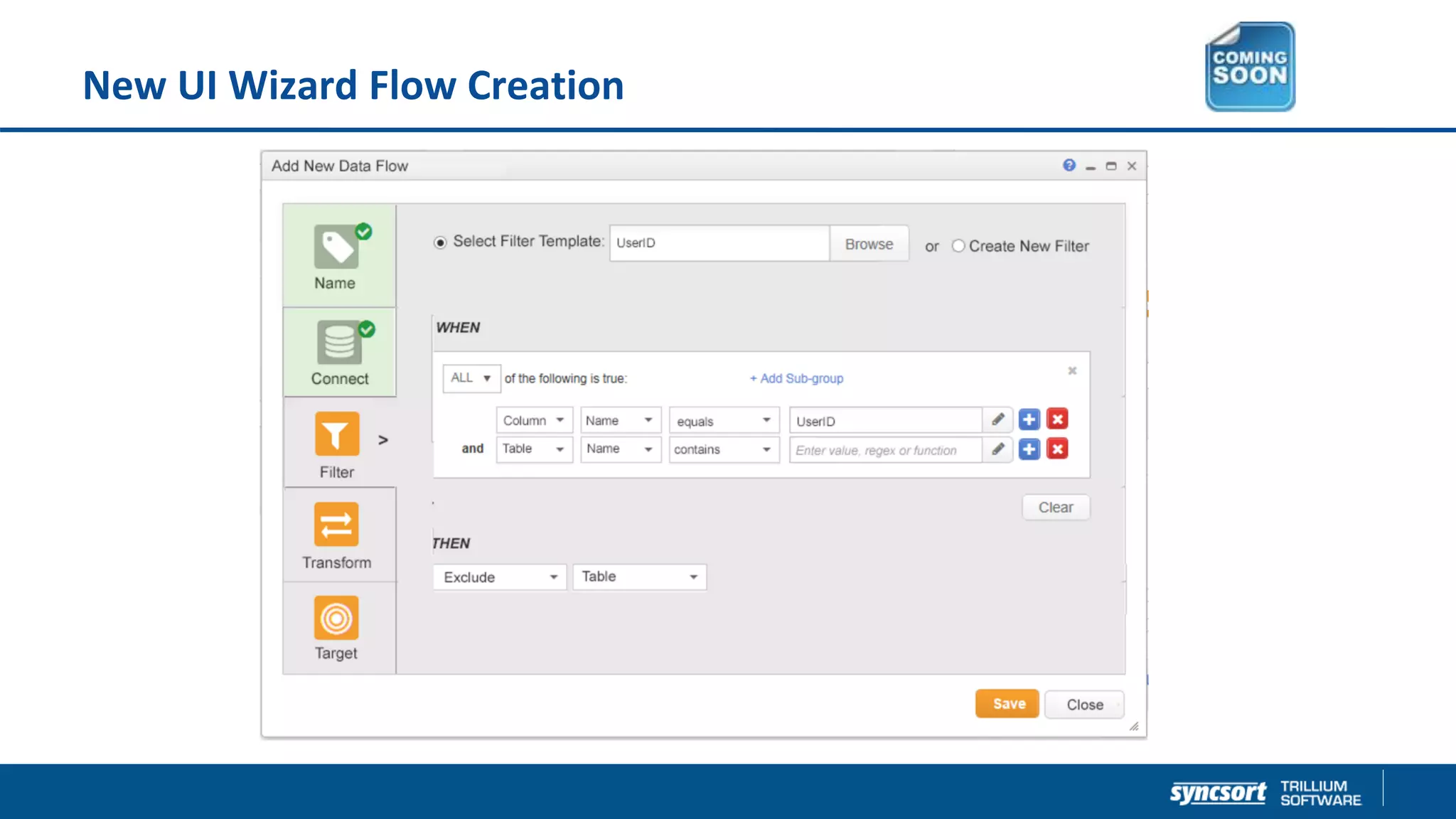

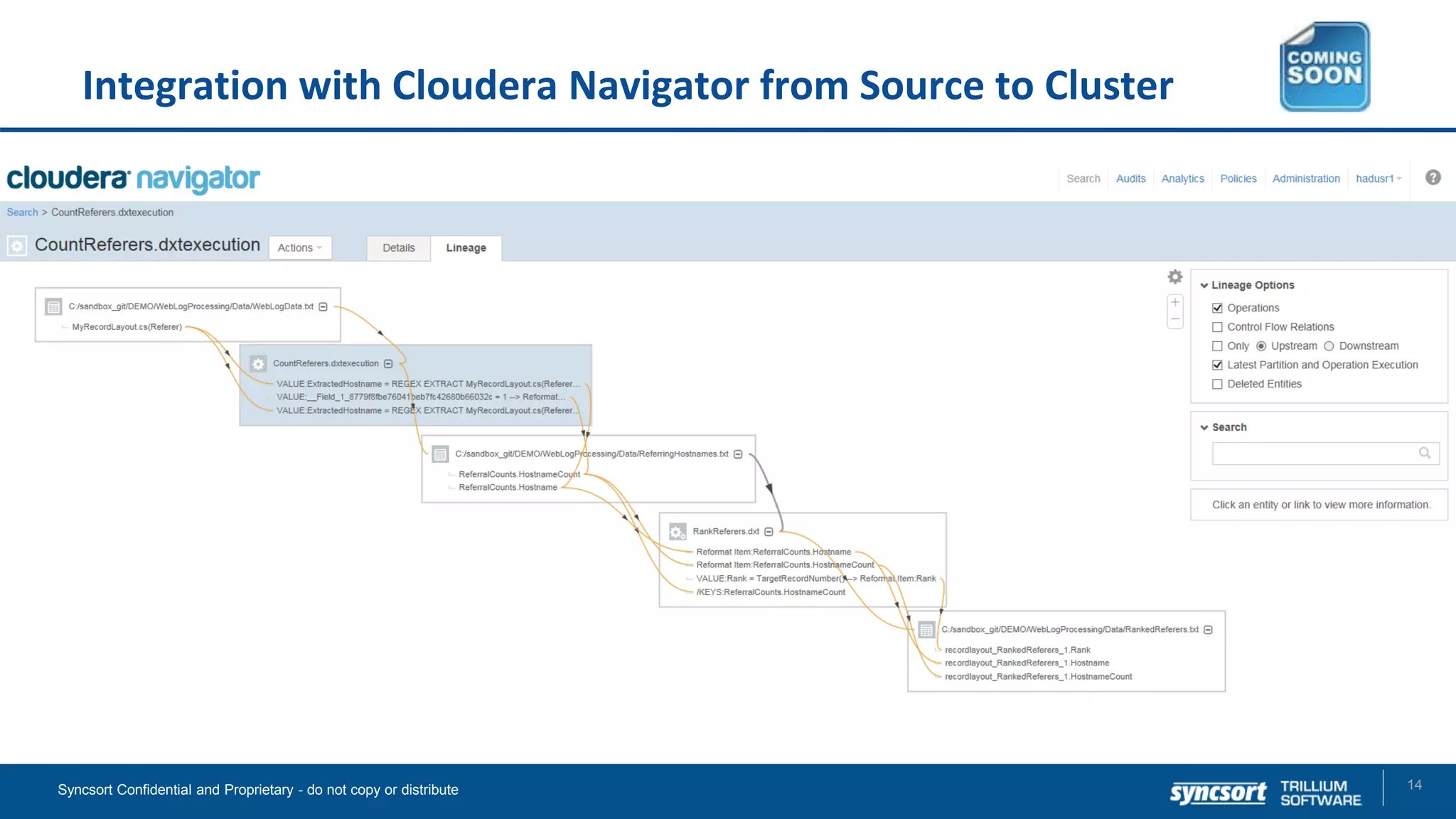

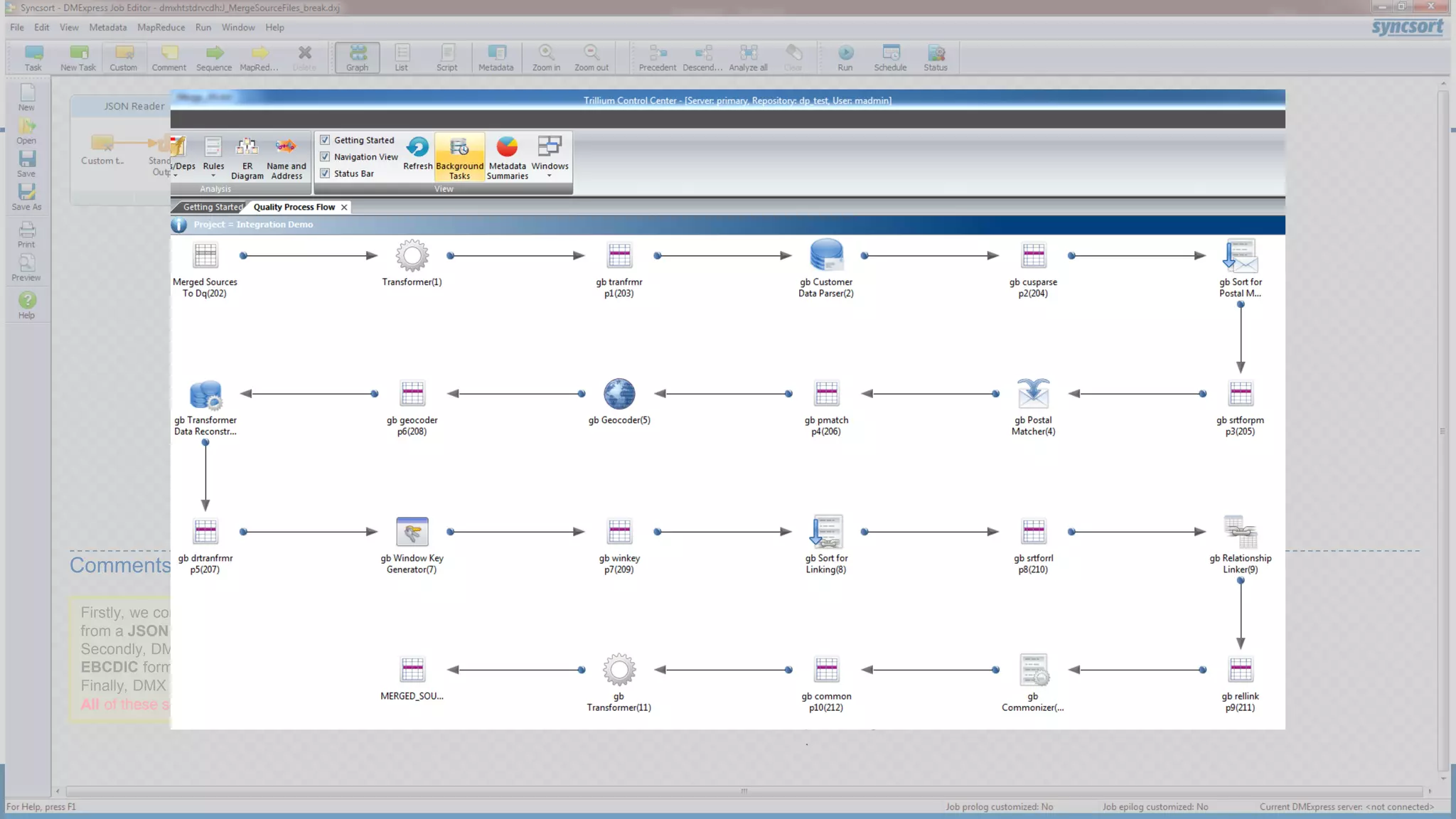



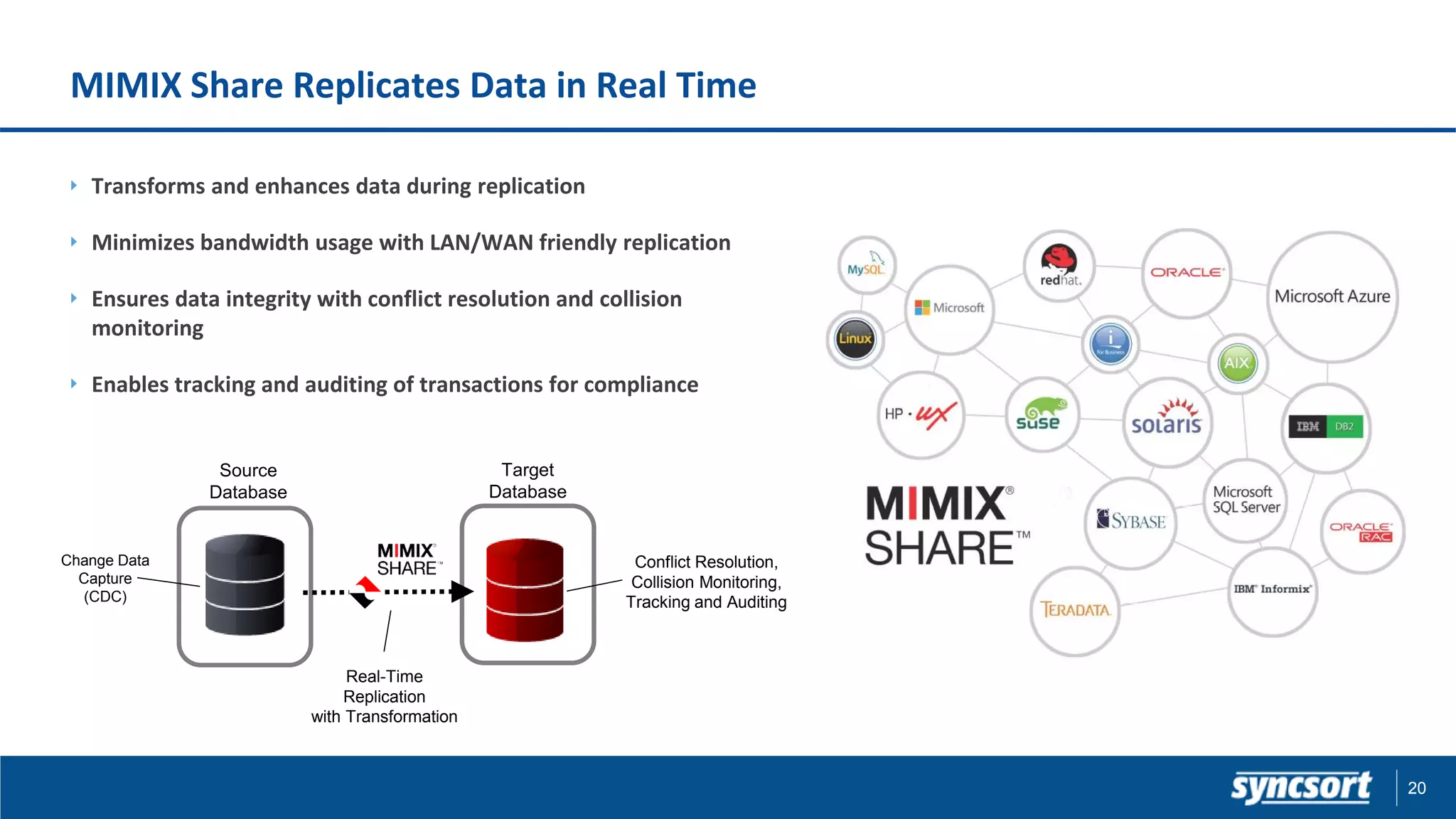

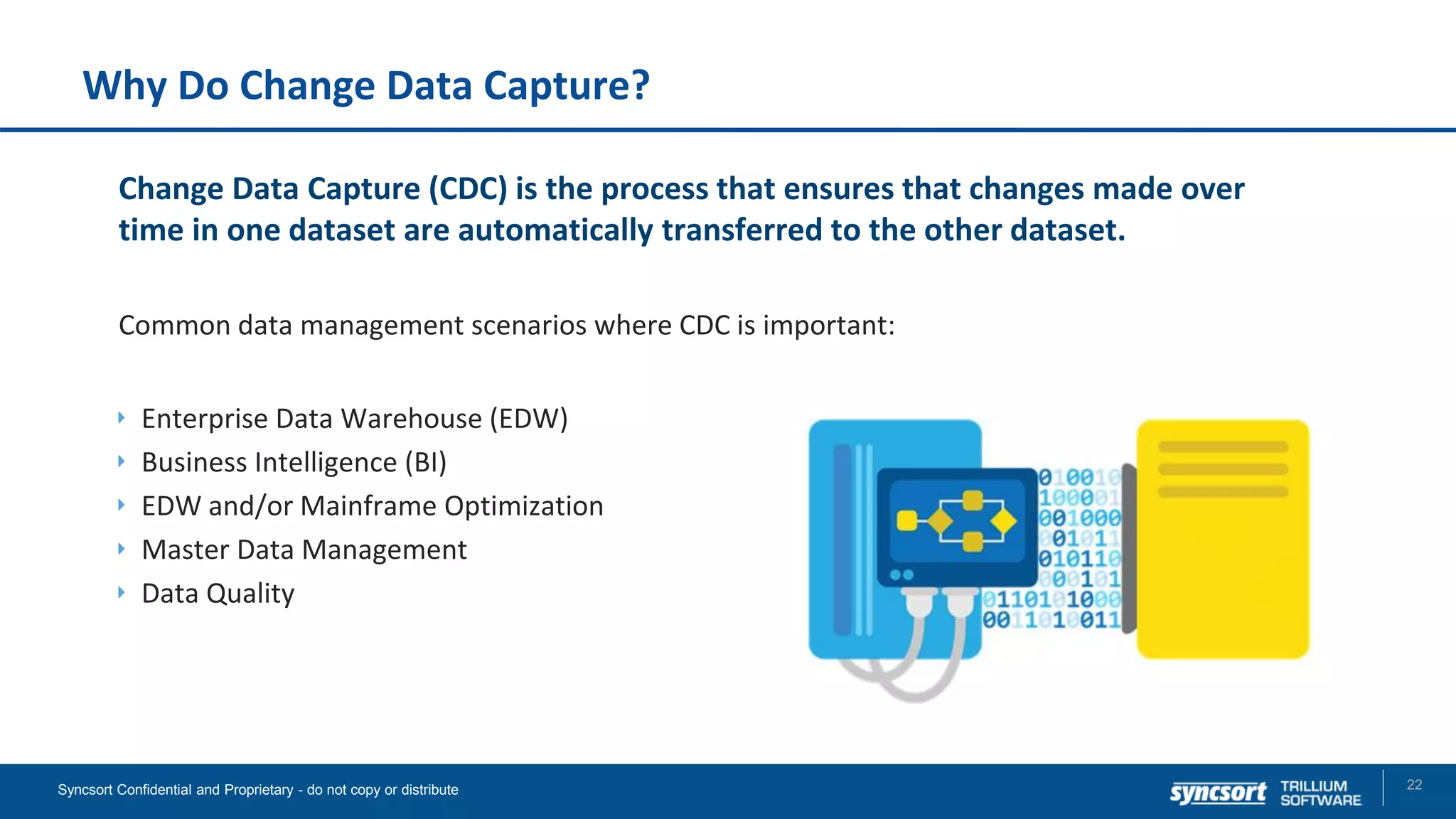

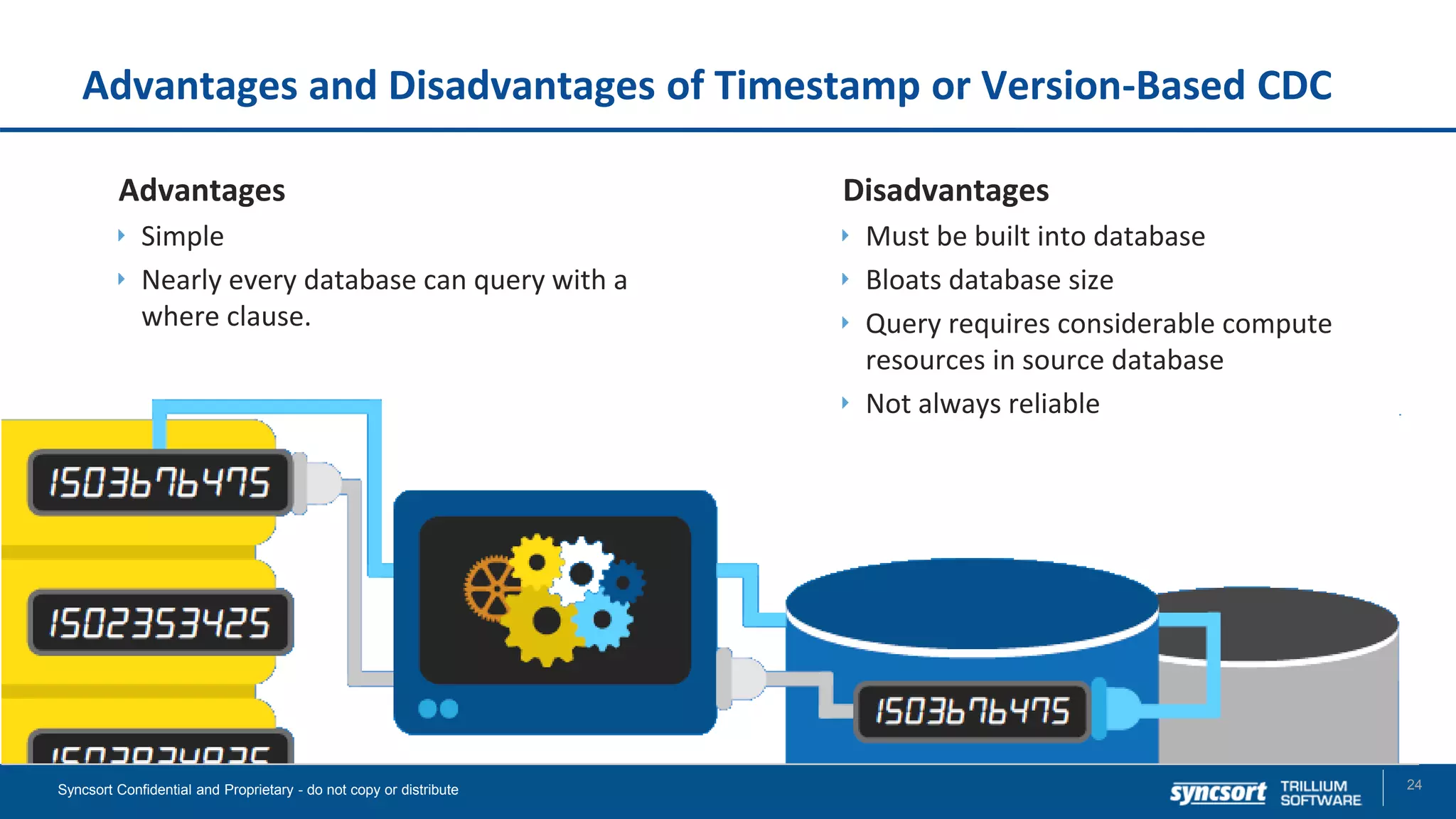




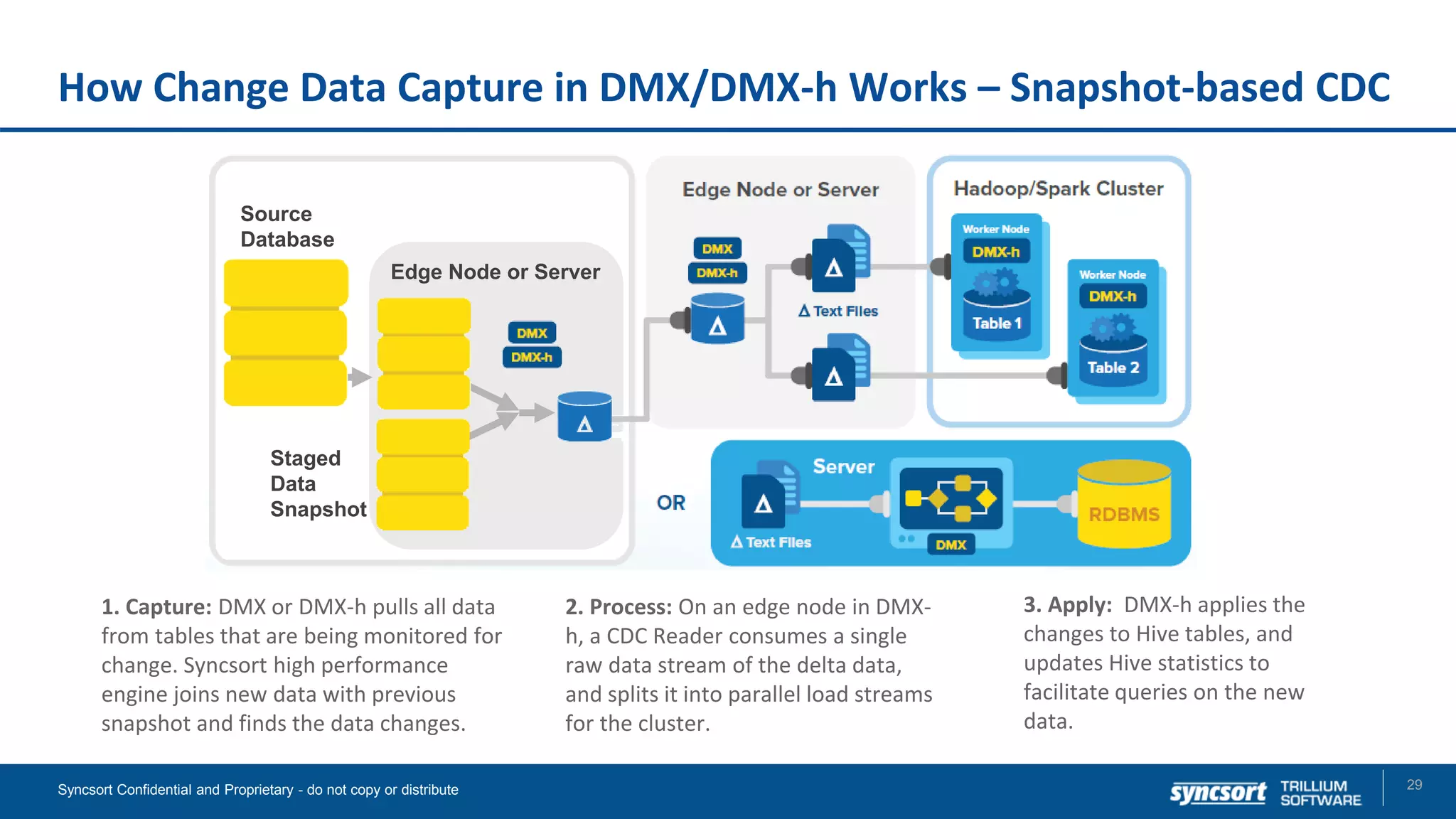
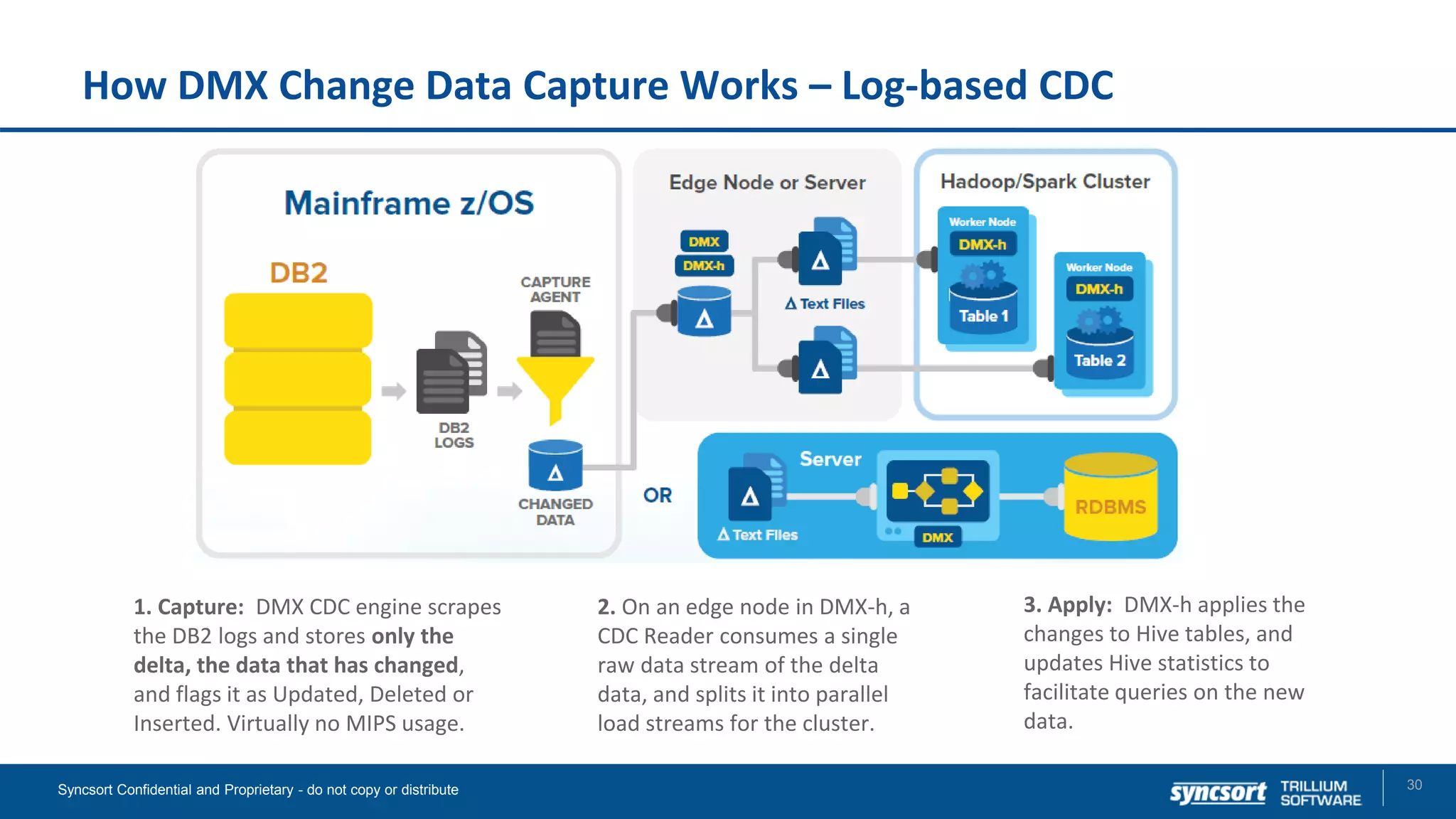



The document presents updates on Syncsort's Big Data products, specifically the new features in DMX/DMX-H version 9.5, including change data capture capabilities and enhancements for data integration. It discusses various strategies for change data capture (CDC) such as snapshot, log-based, and trigger-based methods, outlining their advantages and disadvantages. Additionally, it highlights performance monitoring, data quality management, and integration with other systems like Cloudera Navigator.























































































