Tabeller
Dataene i enrelasjonsdatabase er plassert i
to-dimensjonale tabeller.
En relasjons-database består av tabeller.
3.
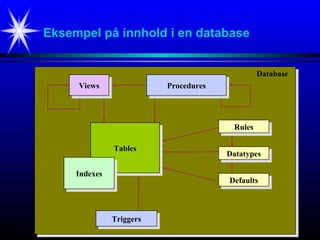
Eksempel på innholdi en database
TablesTables
IndexesIndexes
TriggersTriggers
ViewsViews ProceduresProcedures
RulesRules
DatatypesDatatypes
DefaultsDefaults
Database
4.
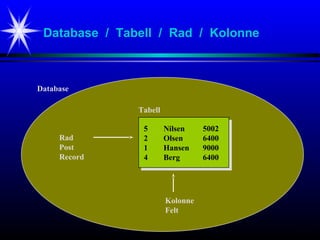
Database / Tabell/ Rad / Kolonne
5 Nilsen 5002
2 Olsen 6400
1 Hansen 9000
4 Berg 6400
Database
Tabell
Rad
Post
Record
Kolonne
Felt
5.
Hva er enrelasjons-database ?
Nr Navn PNr
5 Nilsen 4890
7 Olsen 6400
3 Hansen 4890
8 Karlsen 4890
PNr Sted
4890 Grimstad
5002 Bergen
6400 Molde
En relasjons-database er en database hvor alle dataene er samlet i to-dimensjonale tabeller
og hvor tabellene eventuelt står i en 1:1 eller 1:n relasjon til hverandre.
Tabellene er inndelt i rader (records) og kolonner (felter).
n 1
6.
Viktige fortrinn vedrelasjons-database
Reduserer lagring av redundante data.Reduserer lagring av redundante data.
Data kan lett omorganiseres og kombineres i nyeData kan lett omorganiseres og kombineres i nye
relasjoner,relasjoner,
de er ikke låst til faste relasjoner pga måten de er lagretde er ikke låst til faste relasjoner pga måten de er lagret
på.på.
Data kan lett oppdateres i det disse vil bli oppdatertData kan lett oppdateres i det disse vil bli oppdatert
på et minimum antall steder.på et minimum antall steder.
Reduserer behovet for disk-plass.Reduserer behovet for disk-plass.
7.
3 sentrale gjenfinnings-operasjoner
iCodd’s relasjons-algebra
SelectionSelection Ekstraherer alle rader fra en tabell,Ekstraherer alle rader fra en tabell,
hvor radene oppfyller gitte kriterier.hvor radene oppfyller gitte kriterier.
ProjectionProjection Ekstraherer en eller flere kolonner fra en tabell.Ekstraherer en eller flere kolonner fra en tabell.
JoinJoin Ekstraherer kolonner fra flere relaterte tabeller.Ekstraherer kolonner fra flere relaterte tabeller.
Selection Projection Join
8.
Normal-former
n PNr StedVNr Pris Mg VNr Pris Mg VNr Pris Mg
n 5002 Bergen 8 500 30
n 6400 Molde 1 200 20 3 400 10
en 9000 Tromsø 5 300 50 8 500 40
6400 Molde 1 200 70 3 400 50 5 300
SNr Selger-nummer
Navn Selger-navn
PNr Post-nummer
Sted Post-sted
VNr Vare-nummer
Pris Vare-pris
Mg Vare-mengde
9.
1NF Første normalform
Hvertabell skal ha en fast postlengdeHver tabell skal ha en fast postlengde
Det skal være kun en post-type pr tabellDet skal være kun en post-type pr tabell
Hver post skal ha et eget identifikasjons-feltHver post skal ha et eget identifikasjons-felt
( ID )( ID )
SNr Navn PNr Sted VNr Pris Mg
5 Nilsen 5002 Bergen 8 500 30
2 Olsen 6400 Molde 1 200 20
2 Olsen 6400 Molde 3 400 10
1 Hansen 9000 Tromsø 5 300 50
1 Hansen 9000 Tromsø 8 500 40
4 Berg 6400 Molde 1 200 70
4 Berg 6400 Molde 3 400 50
4 Berg 6400 Molde 5 300 20
10.
2NF Andre normalform
Databasenmå være på 1.normalformDatabasen må være på 1.normalform
Deler av ID skal ikke kunne være determinantfelt for andre felt,Deler av ID skal ikke kunne være determinantfelt for andre felt,
dvs deler av ID skal ikke entydig kunne bestemmedvs deler av ID skal ikke entydig kunne bestemme
verdier i et annet feltverdier i et annet felt
SNr Navn PNr Sted
5 Nilsen 5002 Bergen
2 Olsen 6400 Molde
1 Hansen 9000 Tromsø
4 Berg 6400 Molde
VNr Pris
8 500
1 200
3 400
5 300
SNr VNr Mg
5 8 30
2 1 20
2 3 10
1 5 50
1 8 40
4 1 70
4 3 50
4 5 20
11.
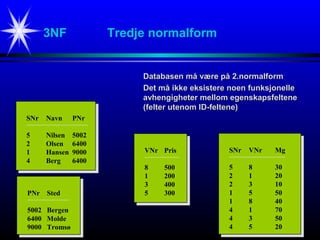
3NF Tredje normalform
Databasenmå være på 2.normalformDatabasen må være på 2.normalform
Det må ikke eksistere noen funksjonelleDet må ikke eksistere noen funksjonelle
avhengigheter mellom egenskapsfelteneavhengigheter mellom egenskapsfeltene
(felter utenom ID-feltene)(felter utenom ID-feltene)
SNr Navn PNr
5 Nilsen 5002
2 Olsen 6400
1 Hansen 9000
4 Berg 6400
VNr Pris
8 500
1 200
3 400
5 300
SNr VNr Mg
5 8 30
2 1 20
2 3 10
1 5 50
1 8 40
4 1 70
4 3 50
4 5 20
PNr Sted
5002 Bergen
6400 Molde
9000 Tromsø
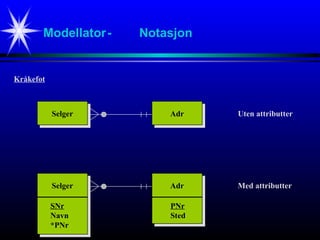
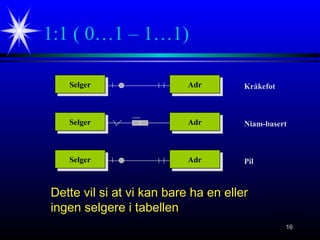
1:1 ( 0…1– 1…1)
1616
SelgerSelger AdrAdr Kråkefot
SelgerSelger AdrAdr Niam-basert
SelgerSelger AdrAdr Pil
Dette vil si at vi kan bare ha en eller
ingen selgere i tabellen
17.
Generell metode fortilordning av
3NF-tabeller (0)
Vi går tilbake til vår opprinnelige Selger-tabell på 1NF form.
Følgende felter er med i denne 1NF-tabellen ( ID er markert med * ).
* SNr Selger-nummer
Navn Selger-navn
PNr Post-nummer
Sted Post-sted
* VNr Vare-nummer
Pris Vare-pris
Mg Vare-mengde
18.
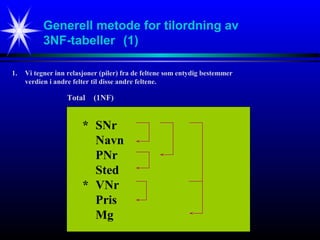
Generell metode fortilordning av
3NF-tabeller (1)
* SNr
Navn
PNr
Sted
* VNr
Pris
Mg
1. Vi tegner inn relasjoner (piler) fra de feltene som entydig bestemmer
verdien i andre felter til disse andre feltene.
Total (1NF)
19.
Generell metode fortilordning av
3NF-tabeller (2)
2. Lag en ny tabell ved å plukke ut alle *-feltene samt alle feltene som er funksjonelt avhengig
av alle disse *-feltene. Denne nye tabellen vil være på 2NF.
* SNr
* VNr
Mg
Salg (2NF)
20.
Generell metode fortilordning av
3NF-tabeller (3)
3. Hvis det i 1NF-tabellen finnes felt som er avhengig av en ekte delmengde av *-feltene,
plukkes disse ut sammen med tilhørende *-felt i egne tabeller.
Disse nye tabellene vil være på 2NF.
* SNr
Navn
PNr
Sted
Selger (2NF)
* VNr
Pris
Vare (2NF)
21.
Generell metode fortilordning av
3NF-tabeller (4)
4. Hvis det i noen av våre 2NF-tabeller ( Salg, Selger, Vare ) finnes ikke-*-felter (ikke ID-felter)
som entydig bestemmer verdier i andre ikke-*-felter, plukkes disse nevnte feltene
ut i egne tabeller. I vårt eksempel gjelder dette tabellen Selger (PNr bestemmer Sted).
Tabellen Selger splittes i to: Tabellene Selger og Adr (Adresse).
Selger-tabellen beholder informasjon om PNr.
ID i disse nye tabellene vil være de feltene som entydig bestemmer
andre felt-verdier. Alle tabellene vil nå være på 3NF.
* SNr
Navn
PNr
Selger (3NF)
* PNr
Sted
Adr (3NF)
22.
Generell metode fortilordning av
3NF-tabeller (5)
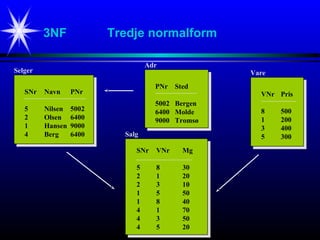
Alle våre 4 tabeller ( Selger, Adr, Vare, Salg ) vil nå oppfylle 3NF.
* SNr
Navn
PNr
Selger (3NF)
* PNr
Sted
Adr (3NF)
* SNr
* VNr
Mg
Salg (3NF)
* VNr
Pris
Vare (3NF)
23.
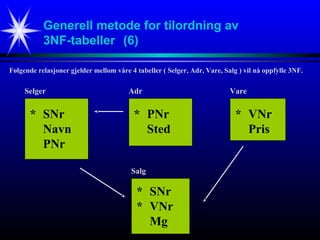
Generell metode fortilordning av
3NF-tabeller (6)
Følgende relasjoner gjelder mellom våre 4 tabeller ( Selger, Adr, Vare, Salg ) vil nå oppfylle 3NF.
* SNr
Navn
PNr
Selger
* PNr
Sted
Adr
* SNr
* VNr
Mg
Salg
* VNr
Pris
Vare
Editor's Notes
#2 I dette kapitlet skal vi benytte kunnskapene våre fra de foregående kapitlene til å utarbeide ulike diskrete sannsynlighetsmodeller.For en gitt oppgave vil det da kunne være hensiktsmessig å finne ut om betingelsene er oppfylt for å kunne benytte en eller flere av disse modellene med tilhørende ferdige utarbeidede metoder.Simuleringer knyttet til dette kapitlet finner du her.
#4 La oss se litt nærmere på selve databasen der dataene ligger lagret.
I en relasjons-database ligger alle dataene lagret i såkalte tabeller.
Dette er to-dimensjonale arrays bestående av rader og kolonner.
Views:Virtuelle tabeller.
Dataene kan være deler av tabell-data eller
en sammenslåing av data fra flere relaterte tabeller.
Indexes:Hjelpetabeller for raskere oppslag i tabeller.
Procedures:Ferdigkompilerte sekvenser av SQL-statement.
Triggers:Ferdigkompilerte rutiner som eksekveres under gitte
forutsetninger.
Rules:Regler for kolonne-verdier (eks: Datoer skal være innen 1-31.
Datatypes:Opplysninger om datatyper i de enkelte kolonner (eks: Number)
Defaults:Kolonne-verdier hvis ingenting annet er spesifisert
(eks: Dagens dato hvis ingenting annet er spesifisert)
#5 En del viktige begrep:
- Database
- Tabell
- Rad / Post / Record
- Kolonne / Felt
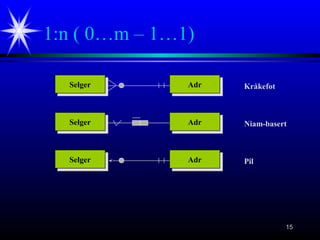
#6 Eksempel på to tabeller Person og Adr som det eksisterer en relasjon mellom.
Relasjonen er innebygget i tabellen Person (kolonnen PNr).
Relasjonen kalles en 1:n (leses: en til n relasjon), fordi det til hver rad (post)
i tabellen Adr finnes 0, 1 eller flere rader (poster) i tabellen Person.
Omvendt vil det til hver rad (post) i tabellen Person finnes nøyaktig
en rad (post) i tabellen Adr.
#7 Noen hovedgrunner til at relasjons-database idag er en standard
blant ulike database-typer.
#8 Gjenfinnings-operasjoner i relasjons-databaser.
#9 Her har vi startet med en stor tabell hvor vi har samlet opplysninger om
hver enkelt selger og de varer som denne selgeren har solgt.
Tabell-formen inneholder flere svakheter:
- Et varierende antall kolonner for hver enkelt selger
- Datadublering
Eks: 6400 Molde er gjentatt flere ganger
Vareprisen på vare nr 8 er gjentatt flere ganger
- Vanskelig å programmere gjenfinning og oppdatering i tabellen.
#10 Tabellen fra foregående side er endret slik at samtlige rader (records)
har samme antall kolonner.
Tabellen sies å være på såkalt første normalform (1NF)
når de tre kravene nevnt ovenfor er oppfylt.
I vår selger-tabell vist ovenfor er disse tre kravene oppfylt.
SNr og VNr utgjør tilsammen ID.
Ulemper:
- Opplysninger om hver enkelt selger må gjentas flere ganger,
en gang for hver vare denne selgeren selger.
- Fortsatt datadublering.
#11 En tabell sies å være på såkalt andre normalform (2NF)
når de to kravene nevnt ovenfor er oppfylt.
Tabellen vist på foregående side oppfyller ikke 2NF.
Hvis vi derimot splitter tabellen i tre slik som vist ovenfor,
så vil hver enkelt av disse tre tabellene være på 2NF.
Vi skal seinere gå nærmere inn på hvordan en slik oppsplitting gjøres.
Vi har fortsatt en del ulemper med tabellene ovenfor selv om disse
oppfyller 2NF, nemlig datadublering ved at sammenhengen mellom
PNr (PostNumer) og Sted er nevnt flere ganger
(6400 Molde er nevnt to ganger).
#12 En tabell sies å være på såkalt tredje normalform (3NF)
når de to kravene nevnt ovenfor er oppfylt.
Tabellen Selger vist på foregående side oppfyller ikke 3NF.
Hvis vi derimot splitter tabellen i to (Selger og Adr) slik som vist ovenfor,
så vil hver enkelt av disse tabellene være på 3NF.
Det finnes flere normalformer enn de tre vi til nå har nevnt,
men vi skal ikke gå nærmere inn på disse her.
#13 Vår opprinnelige selger-tabell er blitt splittet i fire deler.
Hver av de fire tabellene oppfyller 3NF.
Mellom disse tabellene eksisterer det tre 1:n relasjoner.
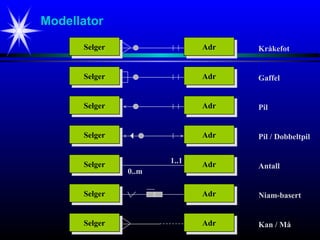
#14 I Modellator kan relasjoner tegnes på ulike vis.
Ovenfor vises 1:n relasjon ved hjelp av såkalte kråkeføtter.
Tabellene er vist med og uten attributter.
#15 Ulike representasjoner av 1:n relasjoner i Modellator.
#18 Vi skal se litt nærmere på en metode for å transformere en 1NF tabell
via 2NF over til 3NF.
Vi starter med vår 1NF selger-tabell.
Denne tabellen består av 7 kolonner.
To av kolonnene, SNr og VNr danner til sammen ID (markert med *)
#19 Vi tegner inn relasjoner (vha piler) fra de feltene som entydig bestememer
verdien i andre felter.
#20 Lag en ny tabell ved å plukke ut alle *-feltene samt alle feltene
som er funksjonelt avhengig av disse *-feltene.
Denne nye tabellen vil være på 2NF.
#21 Hvis det i 1NF tabellene finnes felt som er avhengig av en ekte delmengde
av *-feltene, plukkes disse ut sammen med tilhørende *-felt i egne tabeller.
Disse nye tabellene vil være på 2NF.
#22 Hvis det i noen av våre 2NF-tabeller (Salg, Selger, Vare) finnes
ikke-*-felter (ikke ID-felter) som entydig bestemmer verdier i andre
ikke-*-felter, plukkes disse nevnte feltene ut i egne tabeller.
I vårt eksempel gjelder dette tabellene Selger(PNr bestemmer Sted).
Tabellen Selger splittes i to: Tabellene Selger og Adr (Adresse).
Selger-tabellen beholder informsjonen PNr.
ID i disse nye tabellene vil være de feltene som entydig bestemmer
andre felt-verdier.
Alle tabellene vil nå være på 3NF.
#23 Alle våre 4 tabeller (Selger, Adr, Vare, Salg) vil nå oppfylle 3NF.
#24 Figuren viser relasjonene mellom de 4 3NF-tabellene
Selger, Adr, Vare, Salg.
Relasjons-informasjonen er inneholdt i tabellene slik at pilene (som skal
illustrere relasjonene) ikke inneholder noen ny informasjon.