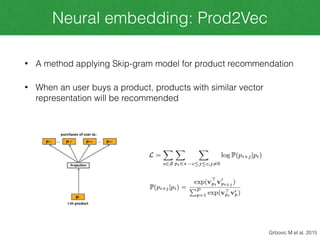
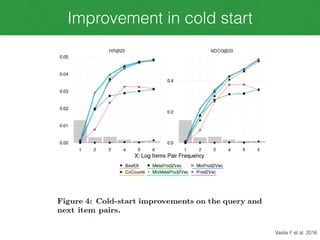
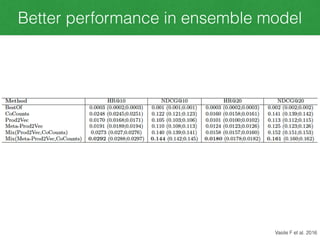
This document discusses Meta-Prod2Vec, a method for product recommendation that uses product embeddings learned from both co-purchase data and side information (metadata). It extends Prod2Vec, which learns embeddings from co-purchase data alone. Meta-Prod2Vec uses a loss function that incorporates both embedding similarities and metadata similarities to generate recommendations. The experiments show Meta-Prod2Vec improves recommendations for cold start products and performs best when combined with traditional collaborative filtering in an ensemble model.