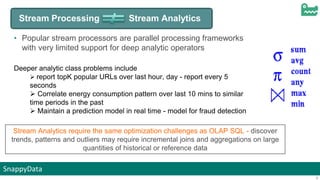
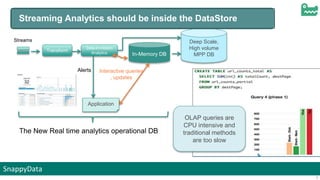
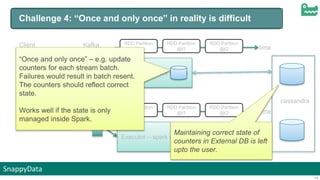
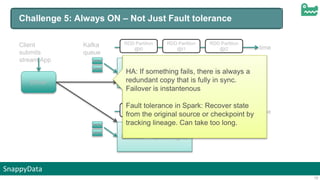
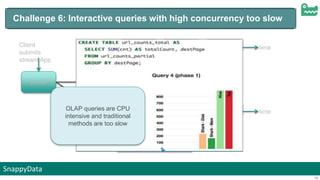
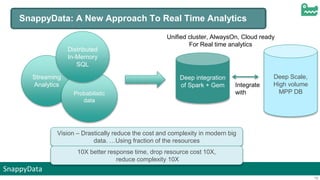
The document discusses SnappyData's integration of Spark with in-memory data management to enhance real-time operational analytics. It outlines the challenges Spark faces in stream processing, including state management, high availability, and interactive queries, while proposing SnappyData as a solution to overcome these issues. Key features of SnappyData include support for high write rates, probabilistic data techniques, and a unified architecture for both OLTP and OLAP workloads.








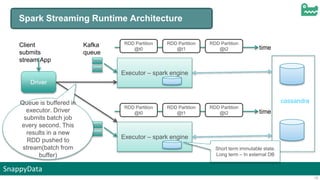


- Built in capability to update state as batches
arrive requires iteration of the full data set](https://image.slidesharecdn.com/snappysparkmeetuppune-151012100217-lva1-app6891/85/Jags-Ramnarayan-s-presentation-12-320.jpg)



![SnappyData
21
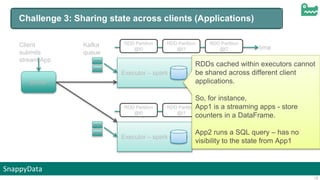
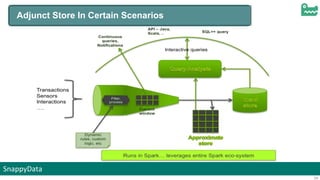
Key Differentiation– OLTP + OLAP with Synopsis
CQ
Subscriptions
OLAP Query
Engine
Micro Batch
Processing
Module
(Plugins)
Sliding Window
Emits Batches
[ ]
User
Applications
processing
Events &
Issuing
Interactive
Queries
Summary DB
Time Series with decay
TopK, Frequency Summary
Structures
Counters
Histograms
Stratified Samples
Raw Data Windows
Exact DB
(Row + column
oriented)](https://image.slidesharecdn.com/snappysparkmeetuppune-151012100217-lva1-app6891/85/Jags-Ramnarayan-s-presentation-21-320.jpg)


















































![[Strata] Sparkta](https://cdn.slidesharecdn.com/ss_thumbnails/stratasparktav3-150507092440-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)























