Download as PDF, PPTX













![SnappyData Confidential – Do Not Distribute
Full Spark Compatibility
● Any table is also visible as a DataFrame
● Any RDD[T]/DataFrame can be stored in SnappyData
tables
● Tables appear like any JDBC sourced table
○ But, in executor memory by default
● Addtional API for updates, inserts, deletes
//Save a dataFrame using the spark context …
context.createExternalTable(”T1", "ROW", myDataFrame.schema, props );
//save using DataFrame API
dataDF.write.format("ROW").mode(SaveMode.Append).options(props).saveAsTable(”T1");](https://image.slidesharecdn.com/bigdatameetupdeck-160330143310/85/Getting-Spark-ready-for-real-time-operational-analytics-26-320.jpg)

![SnappyData Confidential – Do Not Distribute
Key feature: Synopses Data
● Maintain stratified samples
○ Intelligent sampling to keep error bounds low
● Probabilistic data
○ TopK for time series (using time aggregation CMS, item
aggregation)
○ Histograms, HyperLogLog, Bloom Filters, Wavelets
CREATE SAMPLE TABLE sample-table-name USING columnar
OPTIONS (
BASETABLE ‘table_name’ // source column table or stream table
[ SAMPLINGMETHOD "stratified | uniform" ]
STRATA name (
QCS (“comma-separated-column-names”)
[ FRACTION “frac” ]
),+ // one or more QCS](https://image.slidesharecdn.com/bigdatameetupdeck-160330143310/85/Getting-Spark-ready-for-real-time-operational-analytics-28-320.jpg)
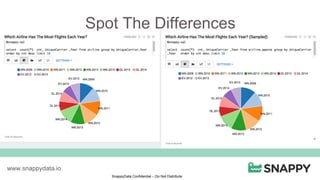
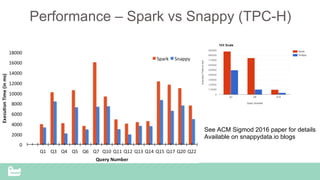
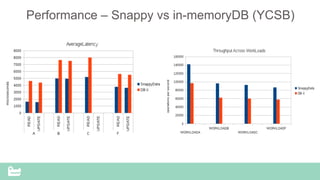



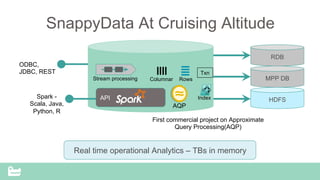
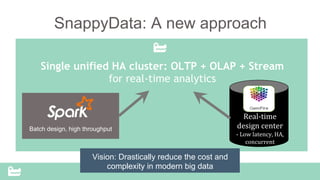
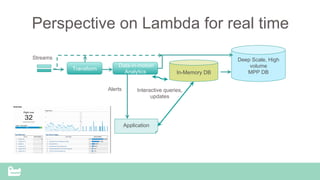
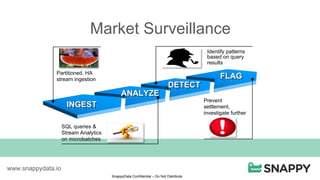
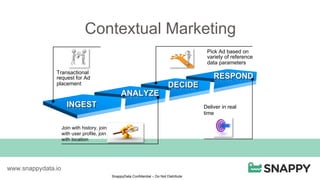
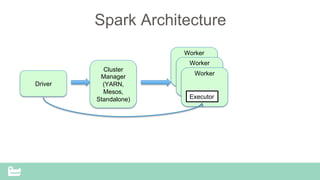
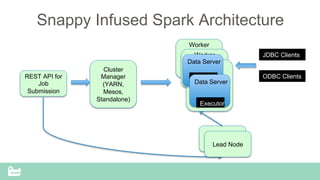
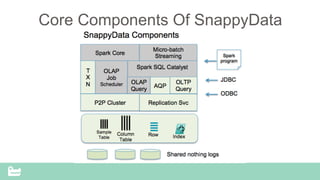
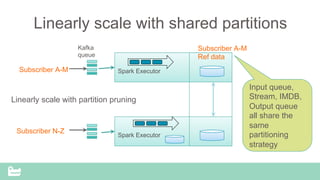
SnappyData provides a unified cluster for operational analytics that can handle OLTP, OLAP and streaming workloads. It integrates an in-memory columnar store with Spark to allow for real-time queries and analytics. SnappyData aims to drastically reduce the cost and complexity of modern big data systems by combining streaming, interactive and batch processing workloads in a single cluster. It offers high performance and scalability for use cases such as market surveillance, real-time recommendations and sensor analytics.



































































