Downloaded 152 times



















![Problems with Cached Tables
Still have to read the data from Cassandra first, which is slow
Amount of RAM: your entire data + extra for conversion to
cached table
Cached tables only live in Spark executors - by default
tied to single context - not HA
once any executor dies, must re-read data from C*
Caching takes time: convert from RDD[Row] to compressed
columnar format
Cannot easily combine new RDD[Row] with cached tables
(and keep speed)](https://image.slidesharecdn.com/2015-09-breakthrougholapperformancewithcassandraandspark-150926064221-lva1-app6892/75/FiloDB-Breakthrough-OLAP-Performance-with-Cassandra-and-Spark-20-2048.jpg)









![So, why isn't everybody doing this?
No columnar storage format designed to work with NoSQL
stores
Efficient conversion to/from columnar format a hard problem
Most infrastructure is still row oriented
Spark SQL/DataFrames based on RDD[Row]
Spark Catalyst is a row-oriented query parser](https://image.slidesharecdn.com/2015-09-breakthrougholapperformancewithcassandraandspark-150926064221-lva1-app6892/75/FiloDB-Breakthrough-OLAP-Performance-with-Cassandra-and-Spark-31-2048.jpg)

















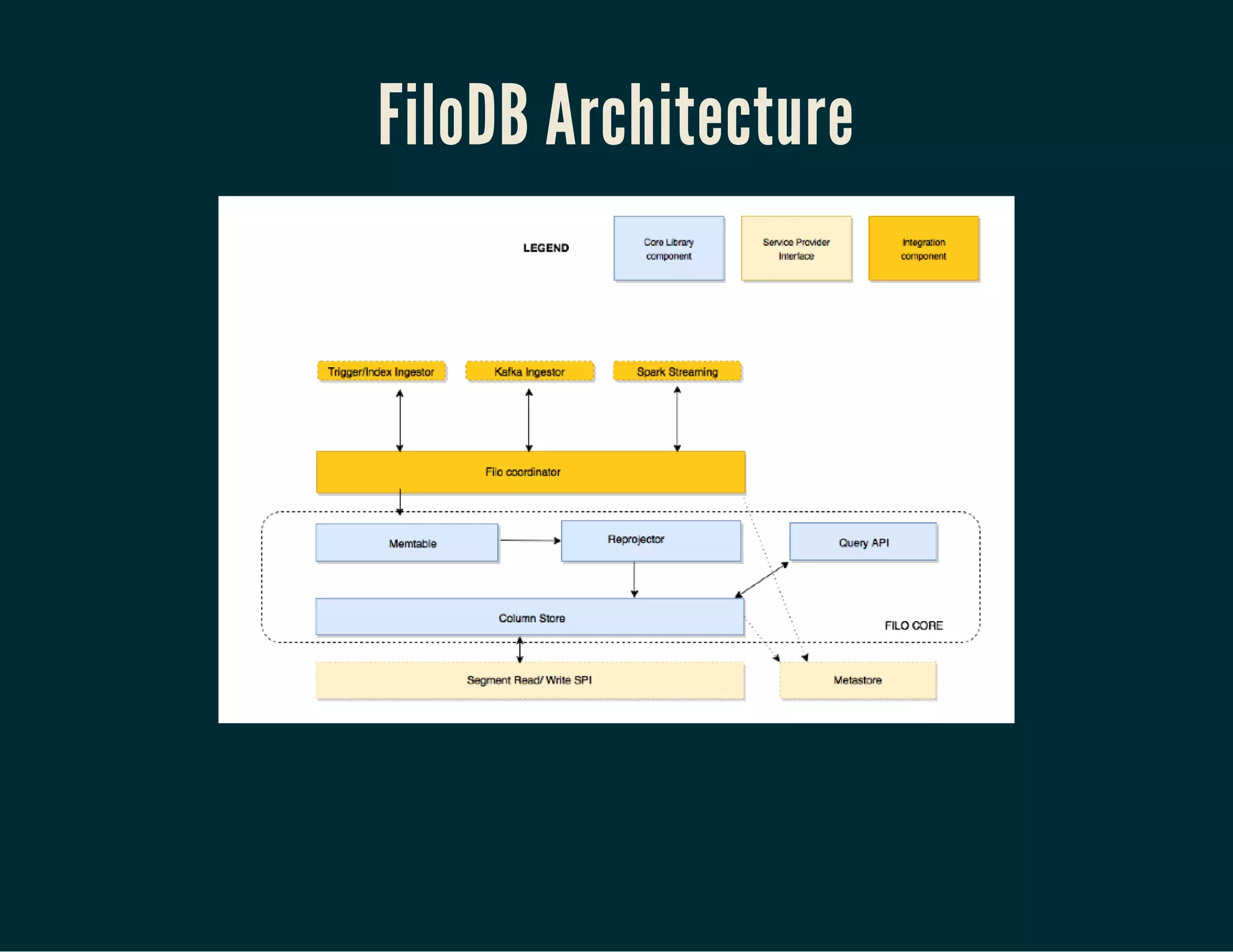



















The document discusses the integration of Apache Cassandra and Apache Spark to enhance OLAP performance for real-time analytics on structured big data. It introduces Filodb, a columnar storage solution that provides efficient query performance and seamless ingestion for time-series and event data, emphasizing the advantages of columnar storage over traditional row-based storage. The presentation highlights various techniques for optimizing Spark queries on Cassandra, including caching and the use of columnar formats to improve speed and reduce I/O costs.
































































































