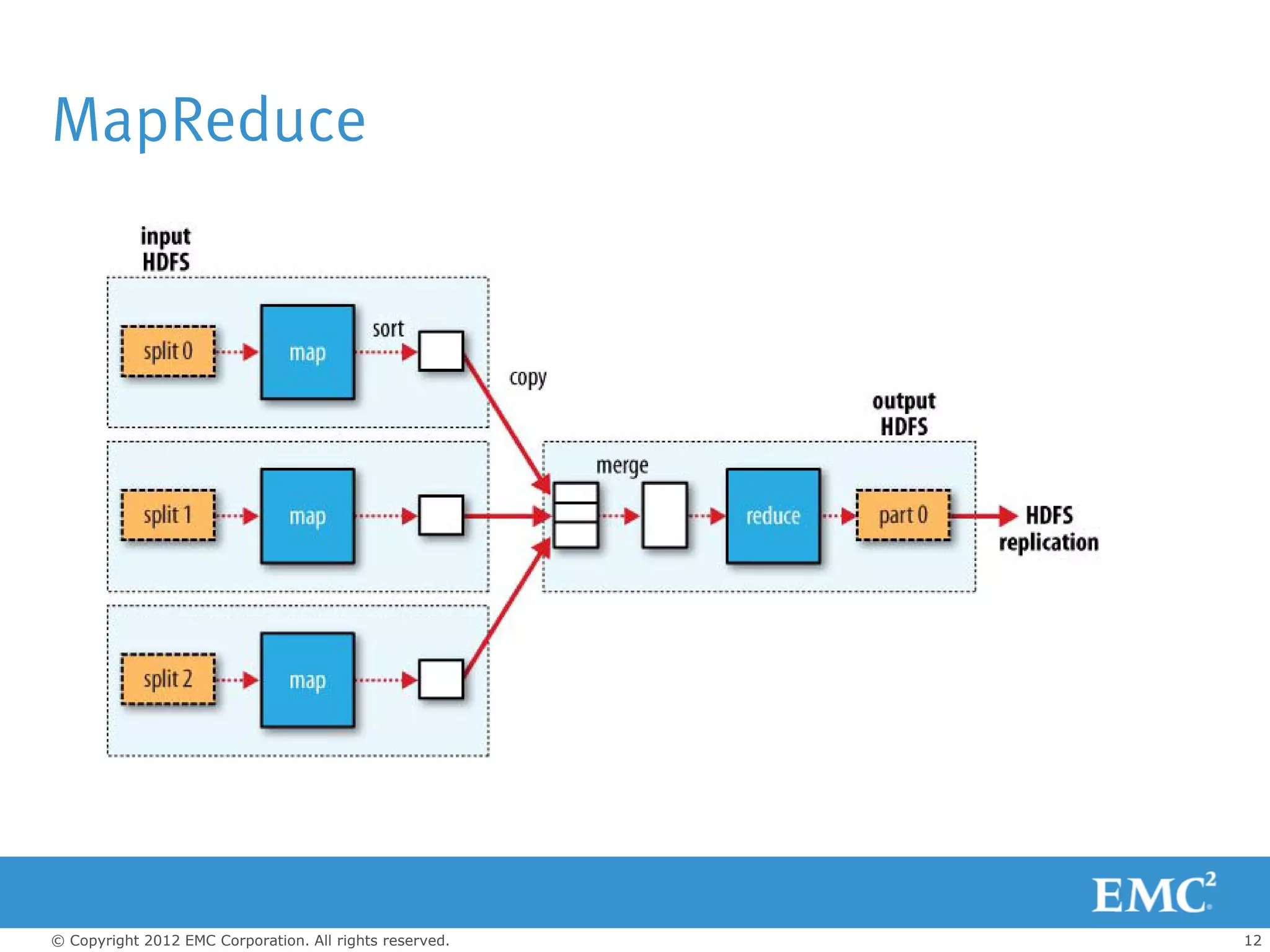
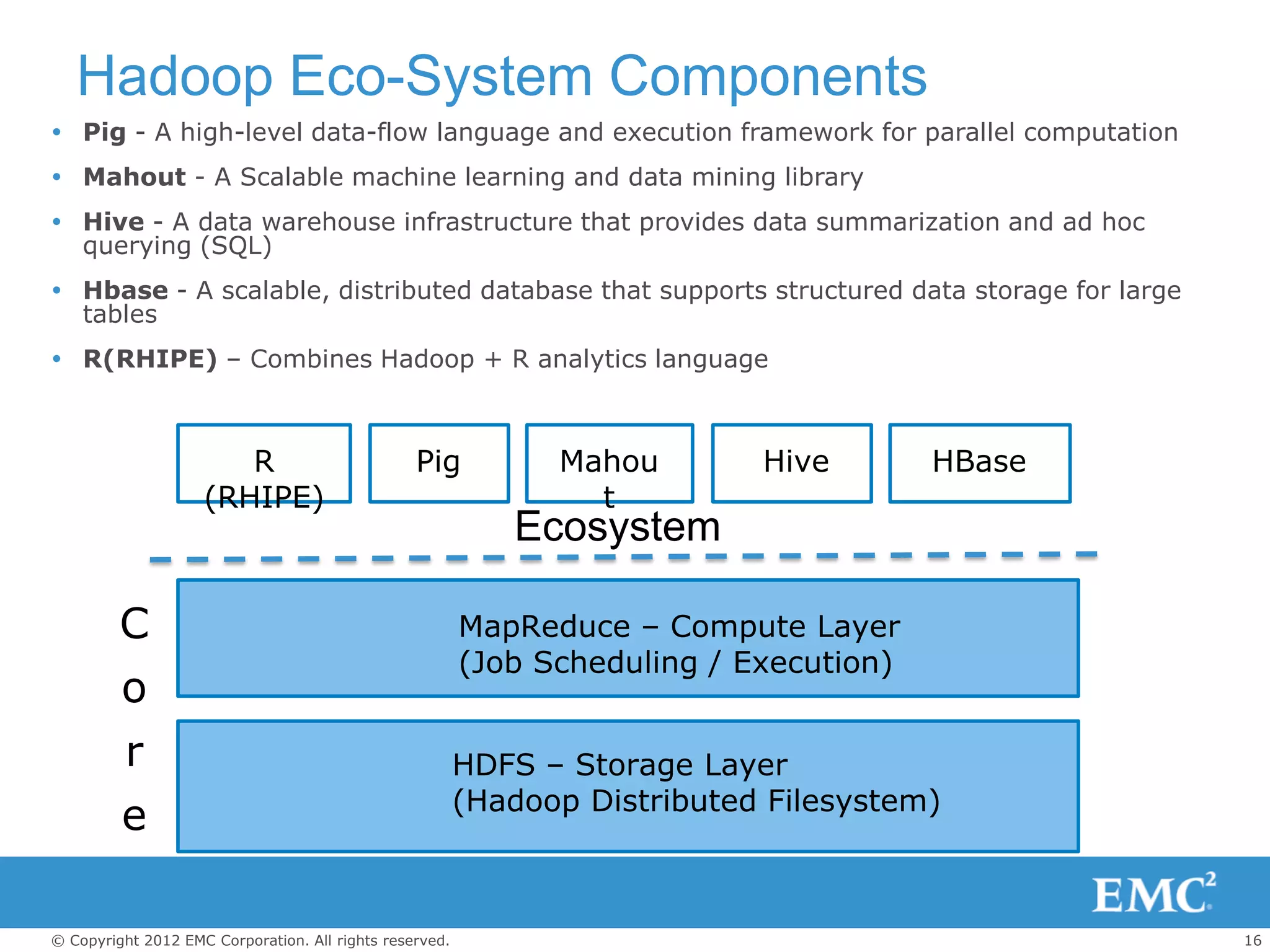
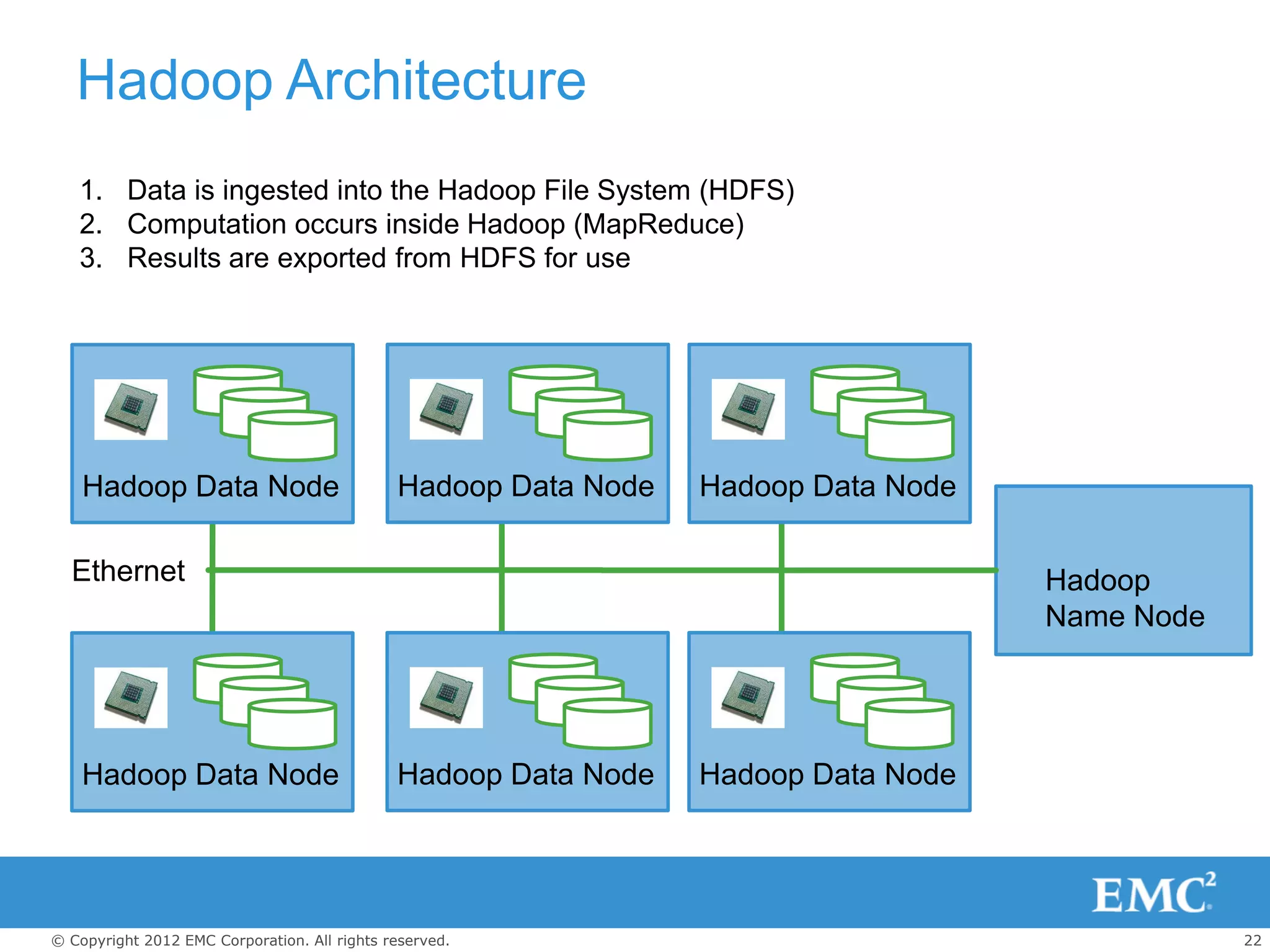
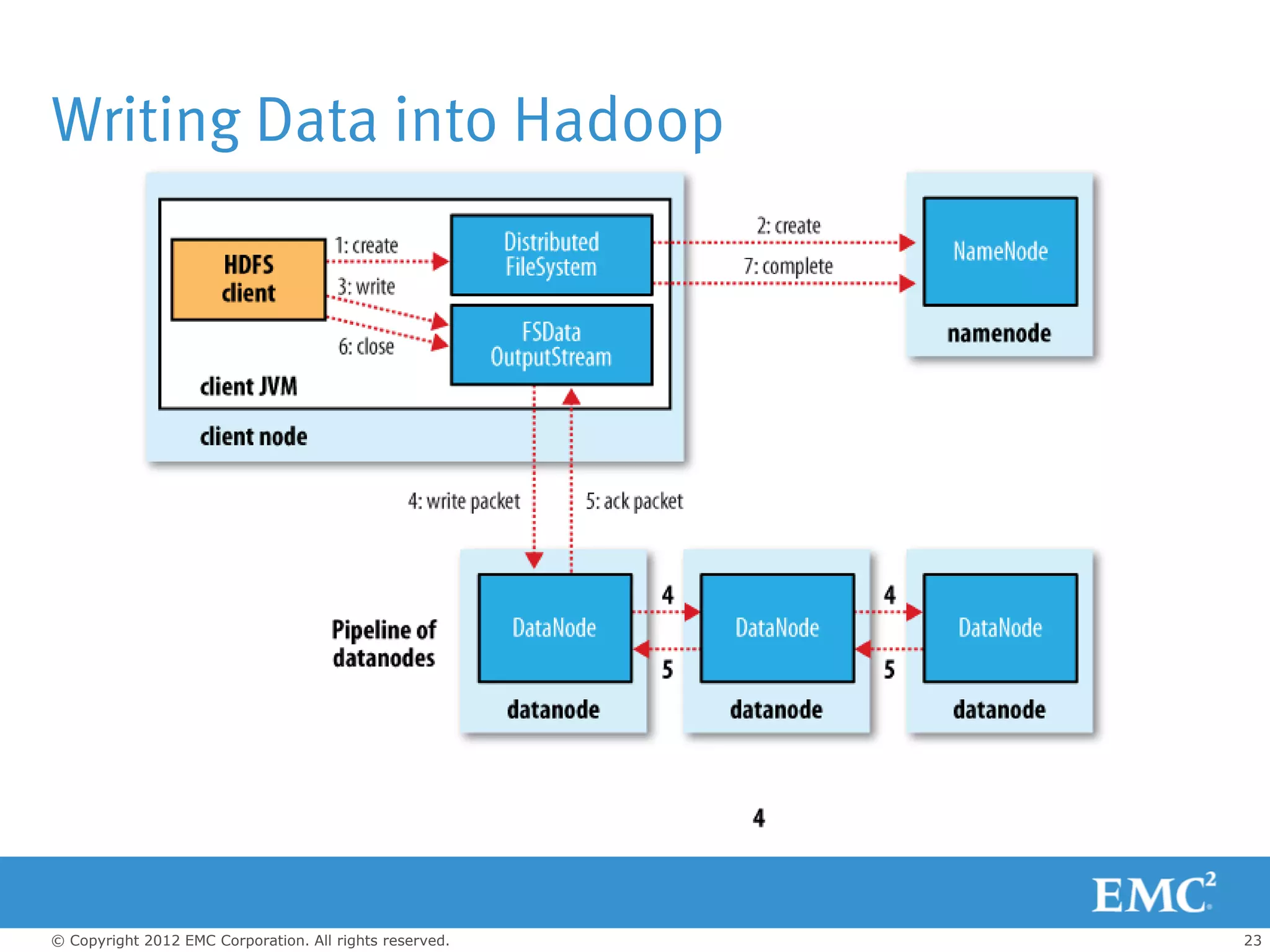
The document outlines the role of big data and Hadoop analytics in transforming business operations. It discusses the functionality of Hadoop, its architecture, and various components such as HDFS and MapReduce, alongside the technology challenges it faces. Additionally, it highlights EMC's solutions, including the Isilon storage platform, which enhances Hadoop's capabilities for enterprise use.














































































































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)










