Download to read offline






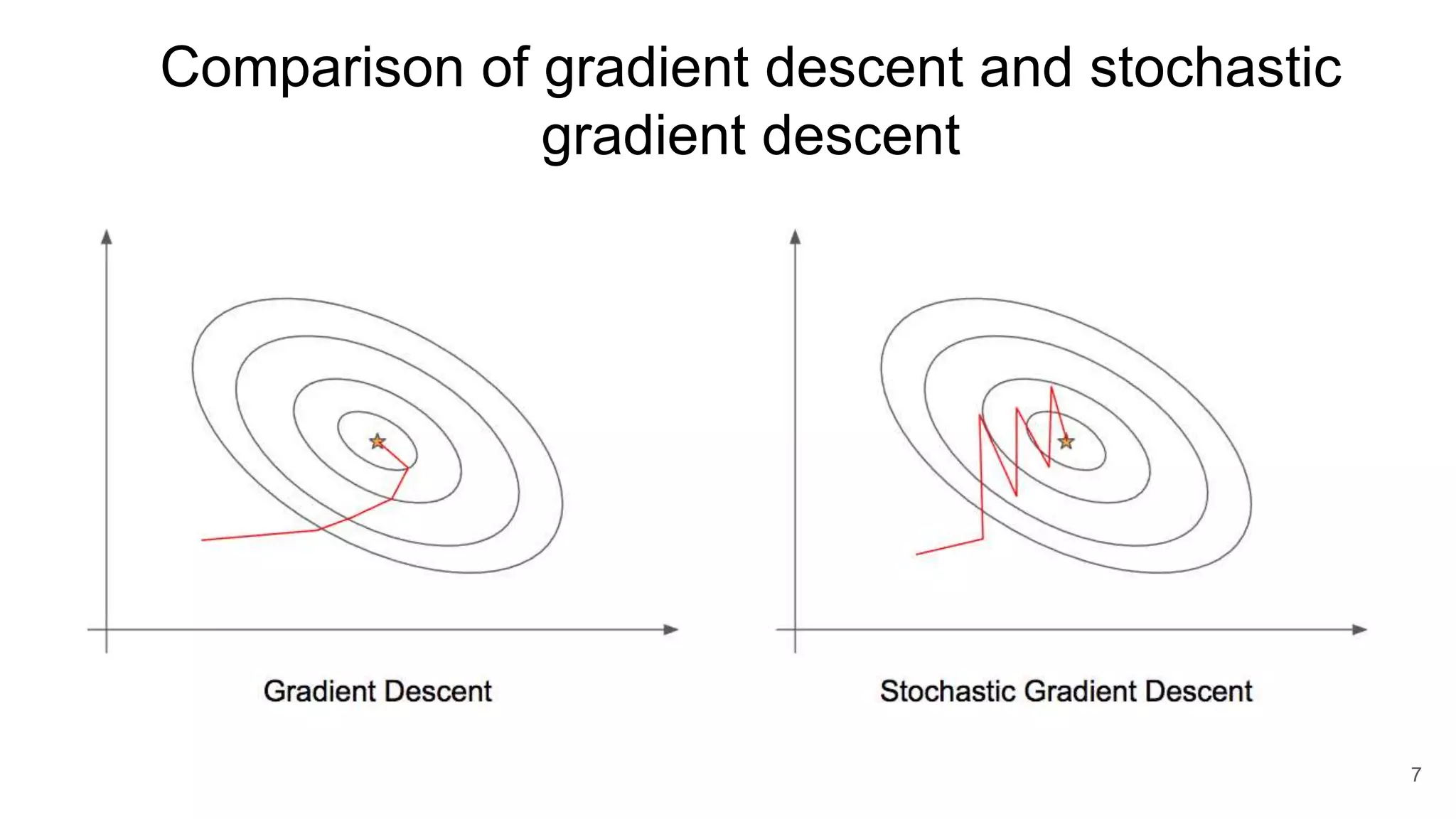




The document discusses optimization techniques for deep learning, specifically focusing on gradient descent and its variants such as stochastic gradient descent and mini-batch gradient descent. It emphasizes the importance of cost functions and learning rates in adjusting parameters to minimize costs efficiently. The comparison of gradient descent and its alternatives aims to highlight strategies for achieving better local minima more effectively.















































