What is
MLOps?
• MLOps(Machine Learning Operations)
is a set of practices that combines
Machine Learning, DevOps, and Data
Engineering to streamline the lifecycle
of ML models—from development to
deployment and monitoring.
Definition:
• Automate, govern, and scale ML in
production.
Key Idea:
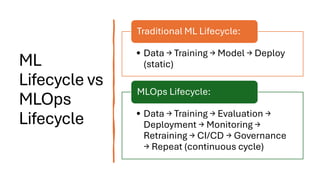
ML
Lifecycle vs
MLOps
Lifecycle
• Data→ Training → Model → Deploy
(static)
Traditional ML Lifecycle:
• Data → Training → Evaluation →
Deployment → Monitoring →
Retraining → CI/CD → Governance
→ Repeat (continuous cycle)
MLOps Lifecycle:
6.
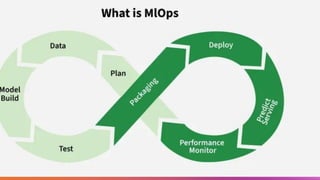
Components of
MLOps
• Dataengineering
• Feature engineering & store
• Experiment tracking
• Model versioning
• CI/CD for ML (CI/CD/CT)
• Model registry
• Deployment pipelines
• Monitoring (drift, data & model)
• Governance & documentation
7.
Defining
MLOps
• MLOps isthe operational backbone for
machine learning systems that
ensures:
• Repeatability
• Reproducibility
• Scalability
• Governance
• Automation across the ML lifecycle
• It brings DevOps concepts into ML, but
with unique ML challenges.
8.
Unique
Challenges
in ML (vs
Software
Dev)
Changingdata → needs retraining
Model drift
Data quality issues
Feature inconsistency between train vs prod
High compute cost
Complex dependencies (GPU, frameworks)
Long-running training
Hard to reproduce experiments
Governance
Challenges
• ML requiresgovernance for:
• Bias detection
• Explainability (XAI)
• Auditability
• Regulatory compliance
(GDPR, HIPAA, PDPA)
• Security of data & models
11.
What Risks Existin ML
Projects?
• Data privacy & leakage
• Bias & fairness issues
• Incorrect predictions → business damage
• Drift & model degradation
• Operational downtime
• High compute cost waste
• Unreliable experiments (no reproducibility)
12.
MLOps
Mitigation
Strategy
• MLOps reducesrisk using:
• Automated Data Validation
• Model Evaluation Gates
• Approval Workflows
• CI/CD/CT Pipelines
• Model Registry with Version
Control
• Observability (logging,
metrics, traces)
• Automated retraining
13.
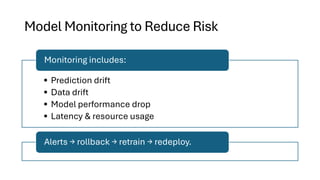
Model Monitoring toReduce Risk
• Prediction drift
• Data drift
• Model performance drop
• Latency & resource usage
Monitoring includes:
Alerts → rollback → retrain → redeploy.
14.
Governance &
Compliance
• MLOpsenforces:
• Version history
• Audit trail
• Access control
• Explainability reports
• Reproducibility of experiments
• Risk documentation
15.
Scaling ML
Beyond POCs• Most ML starts as small POCs but fails at scale
because:
• Manual processes
• Cannot handle large datasets
• No automated pipelines
• Limited compute resources
• Lack of standardization
• MLOps solves this.
16.
What
Scaling
Means
• Scaling MLincludes:
• Handling millions of
predictions
• Running parallel experiments
• Supporting multiple
teams/projects
• Orchestrating GPUs/TPUs
• Managing distributed training
• Deploying globally across
environments










































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)
