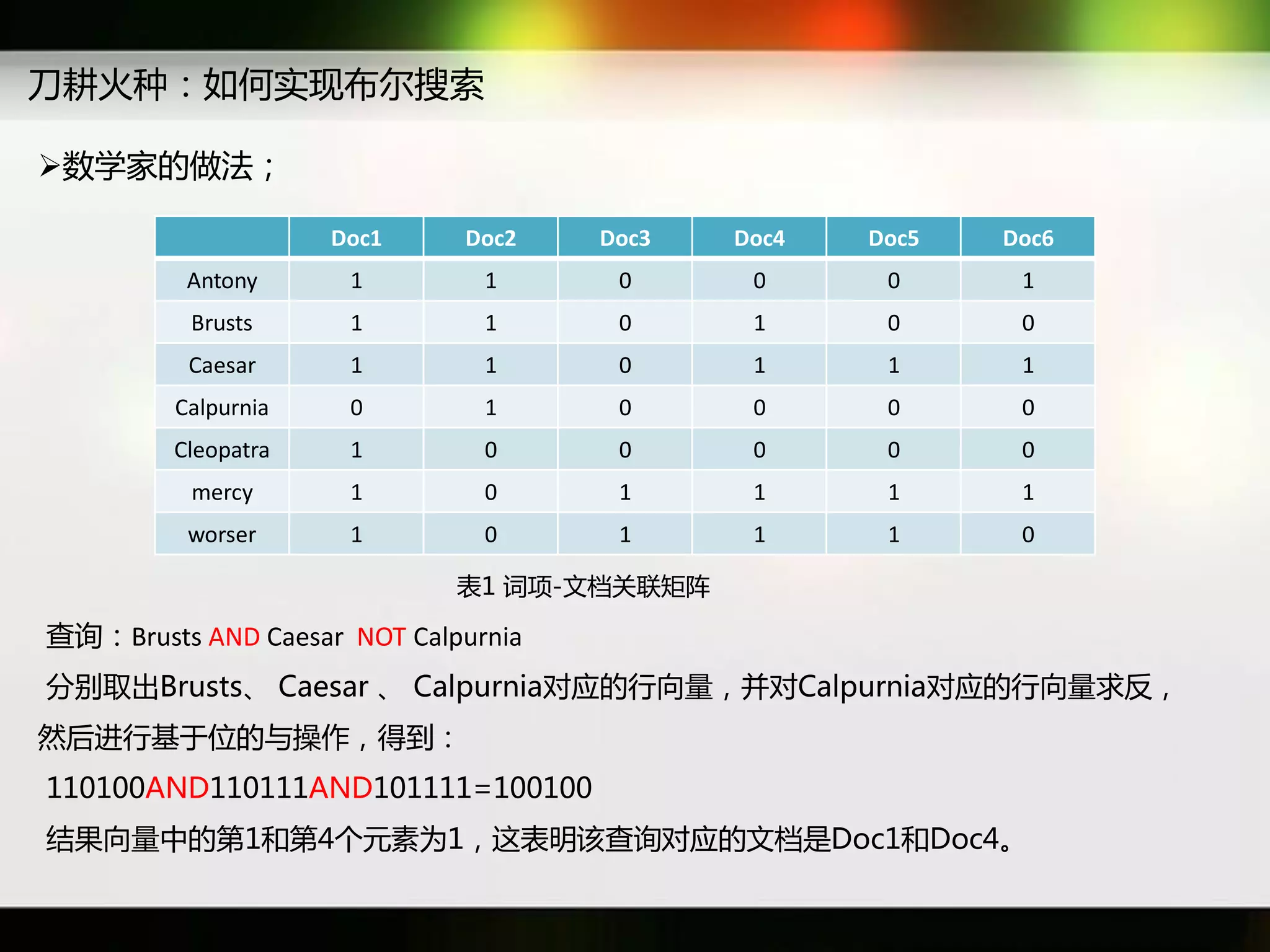
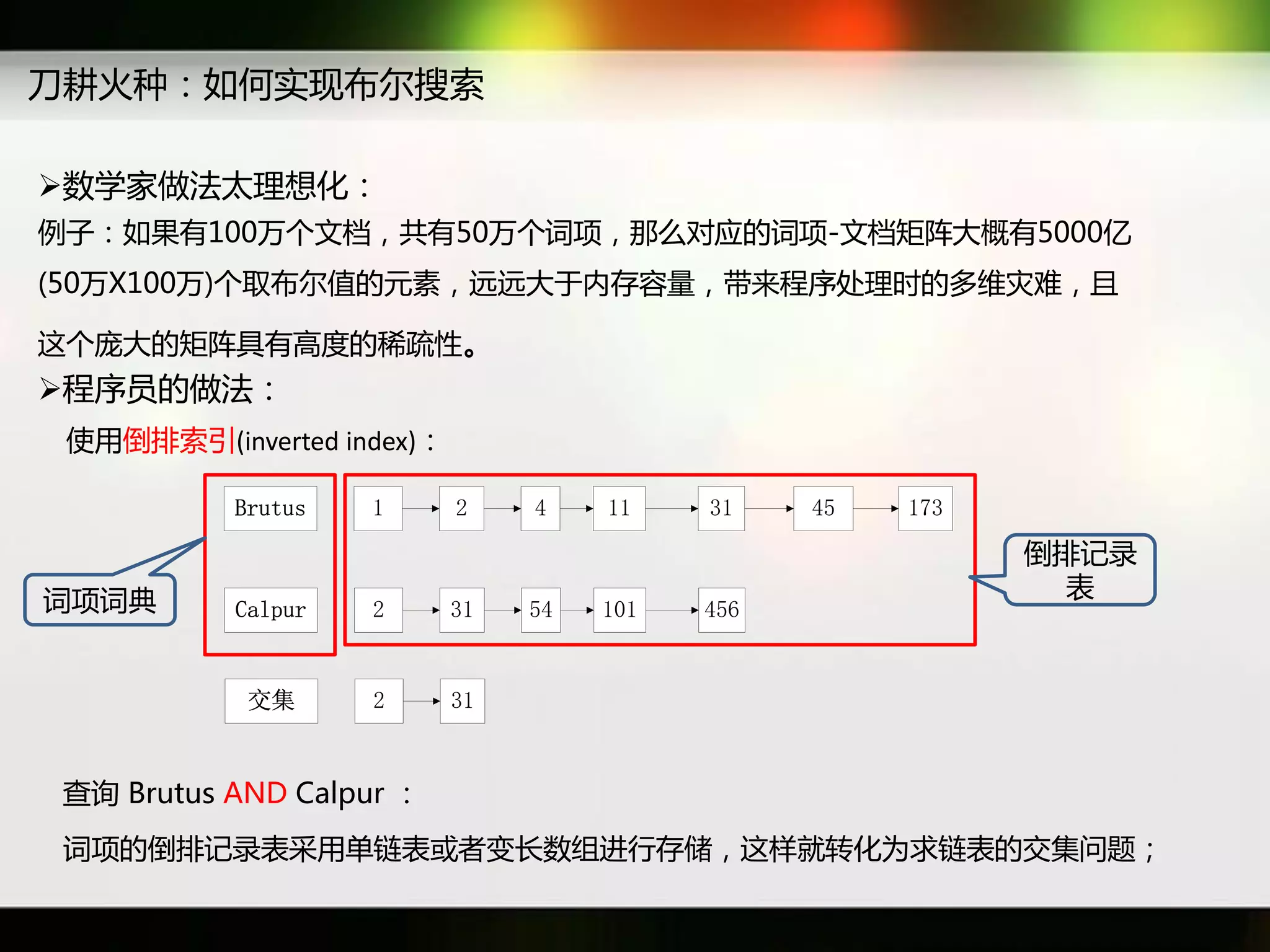
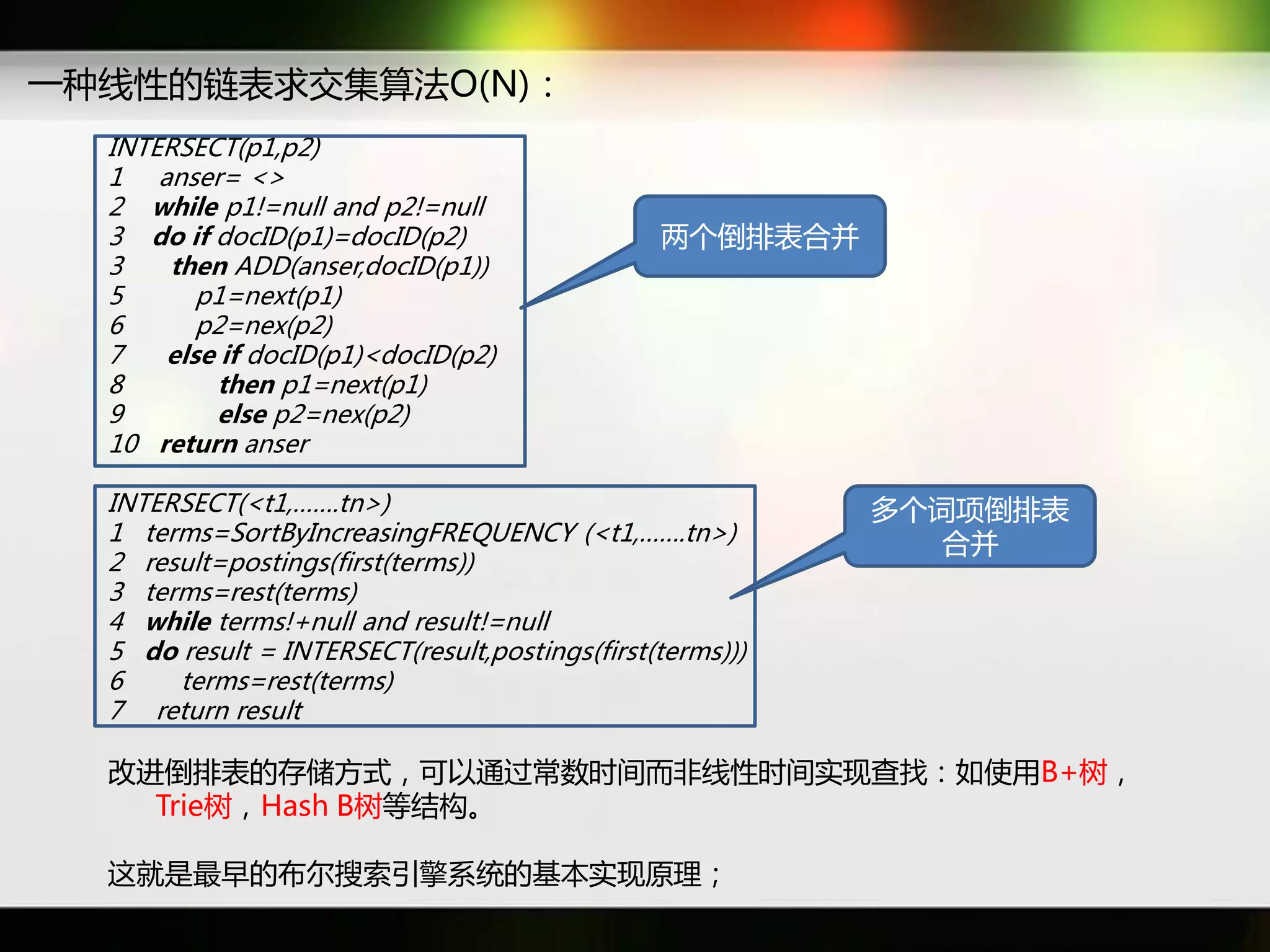
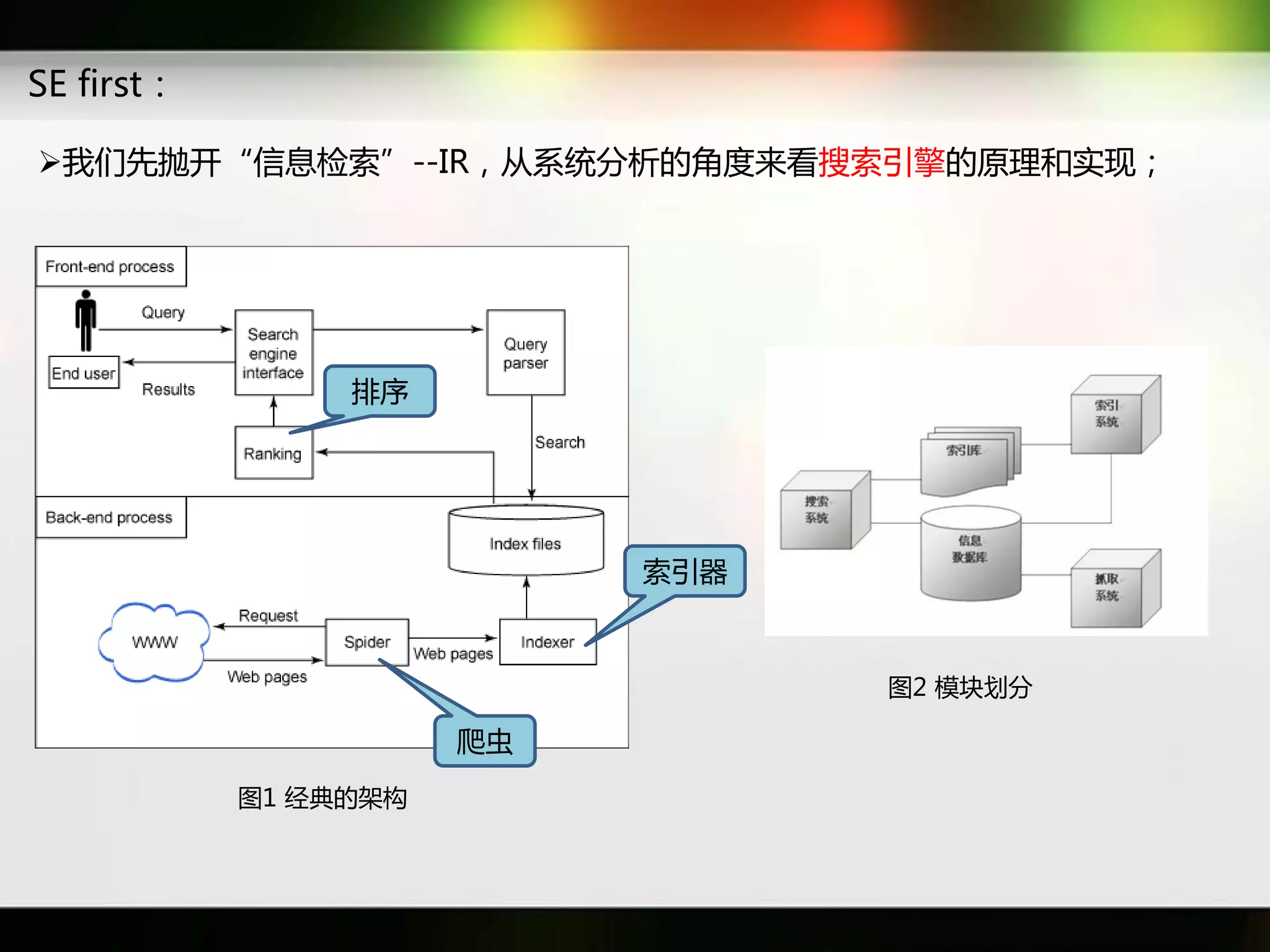
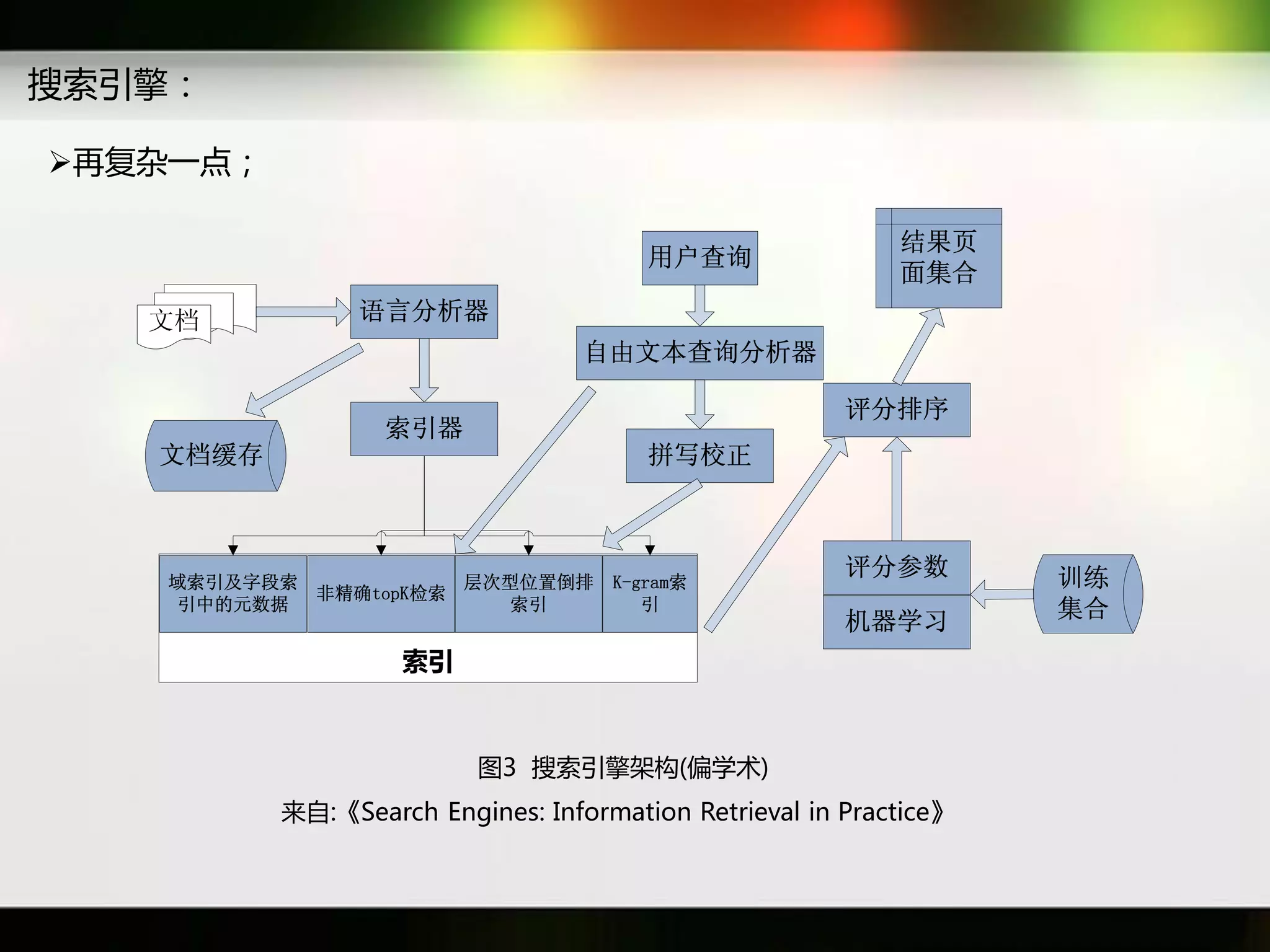
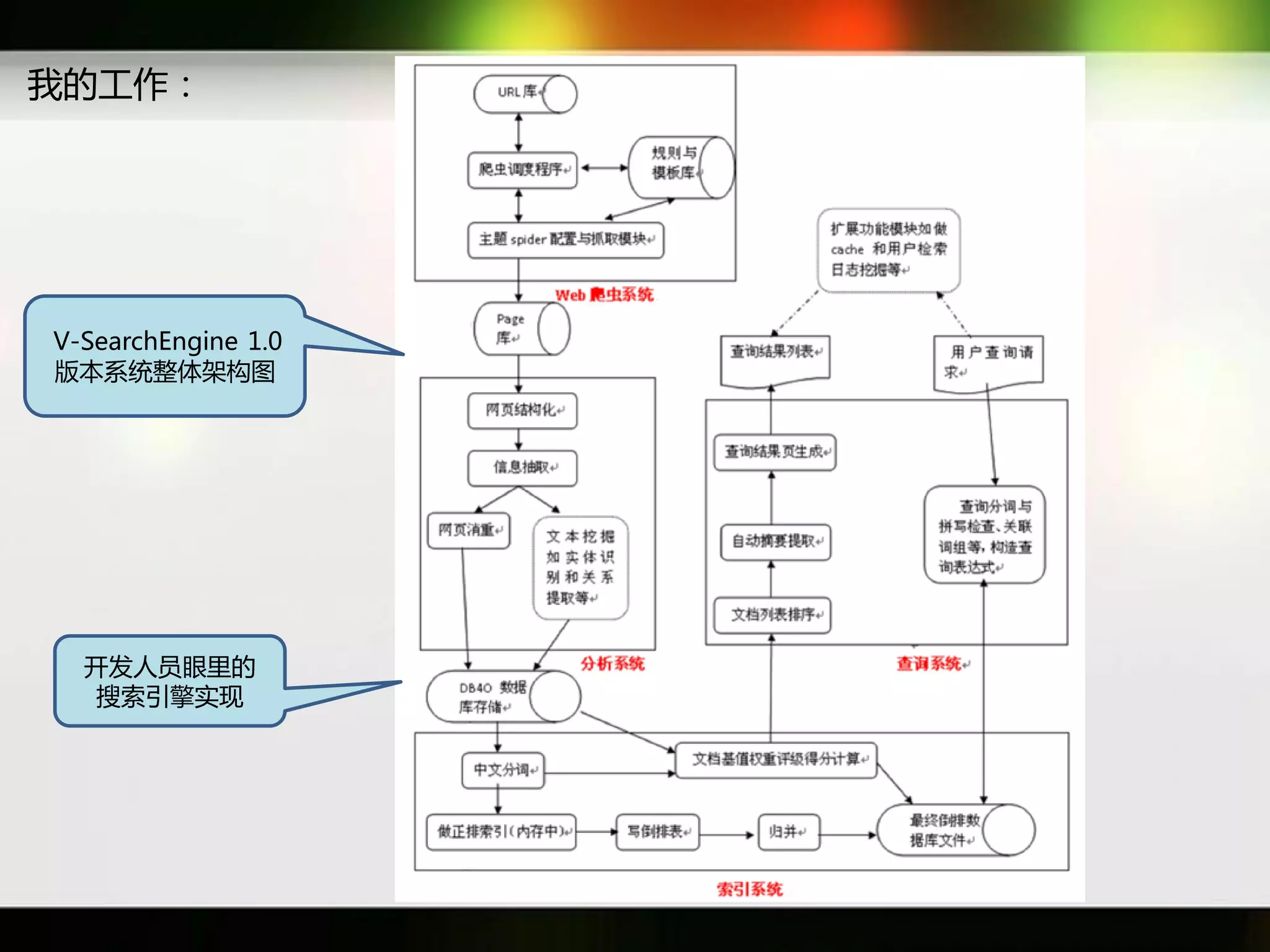
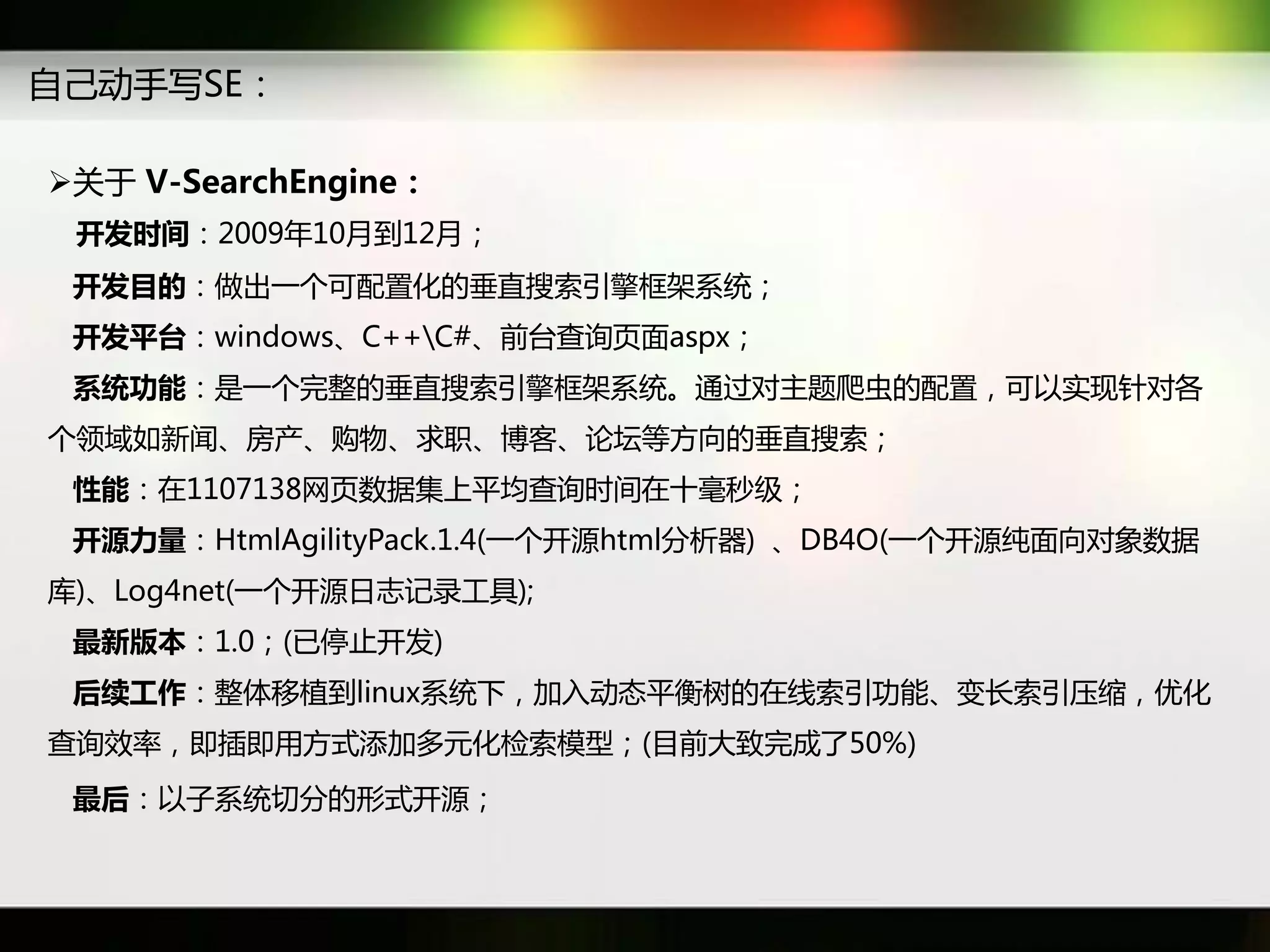
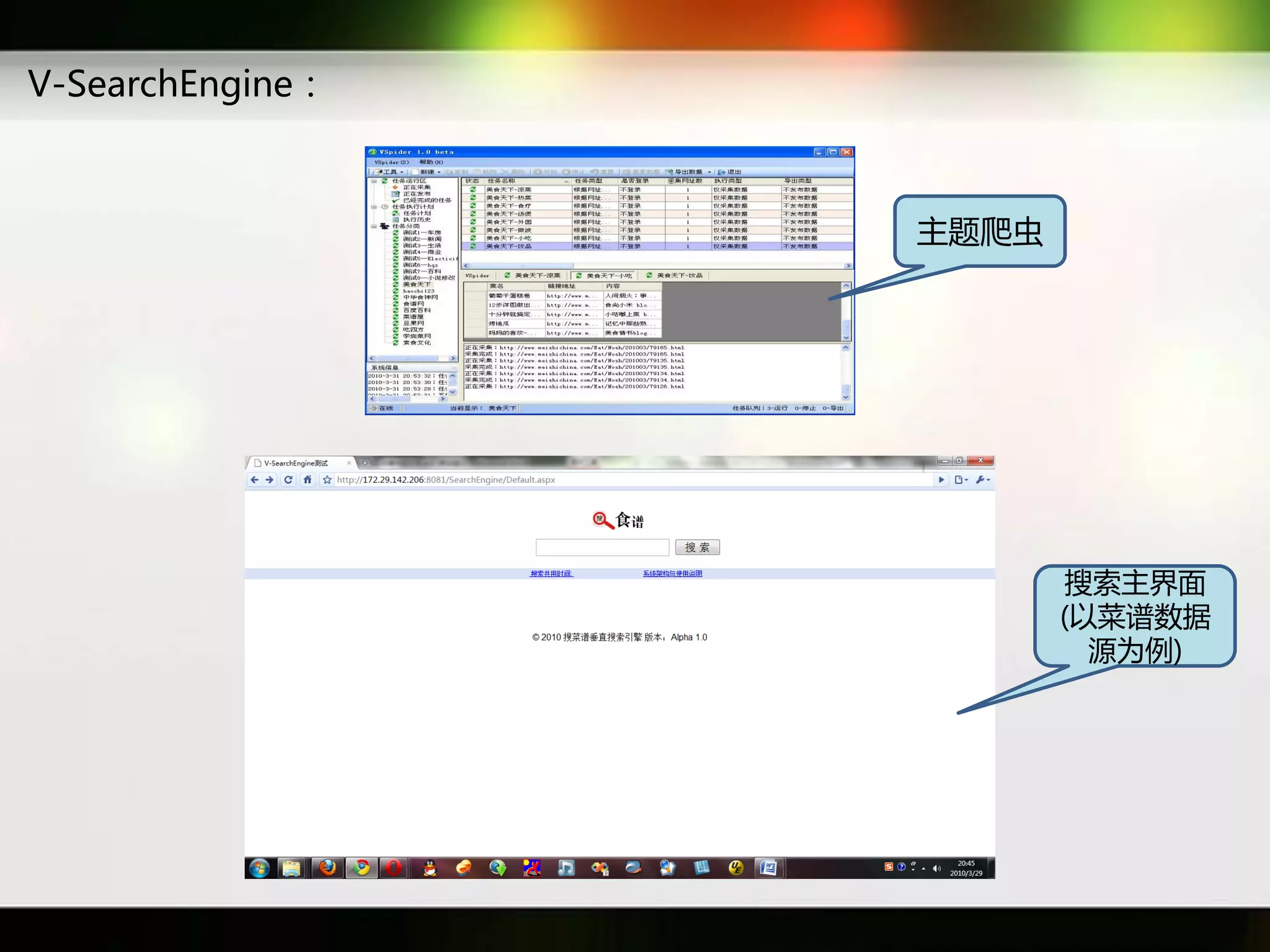
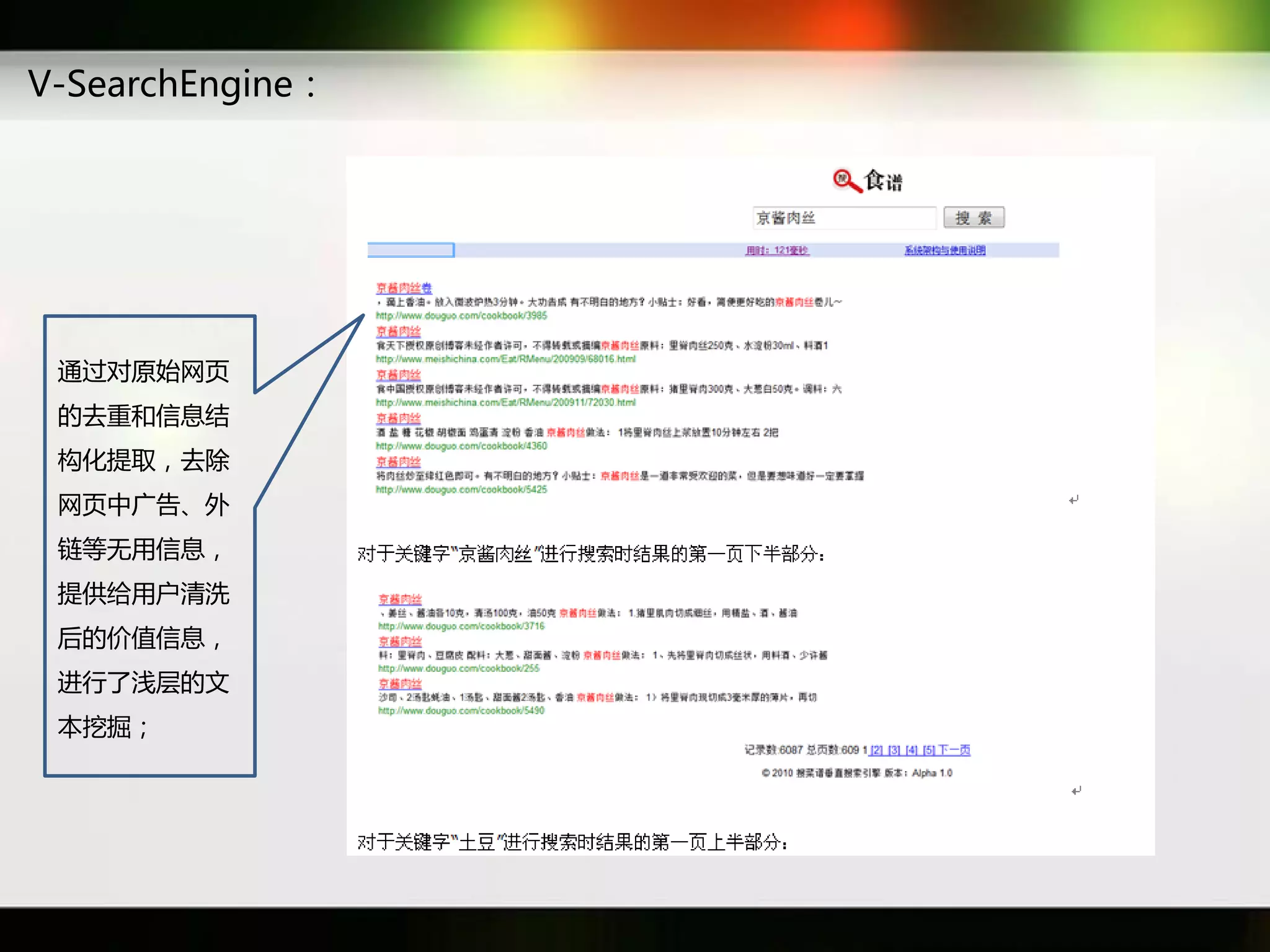
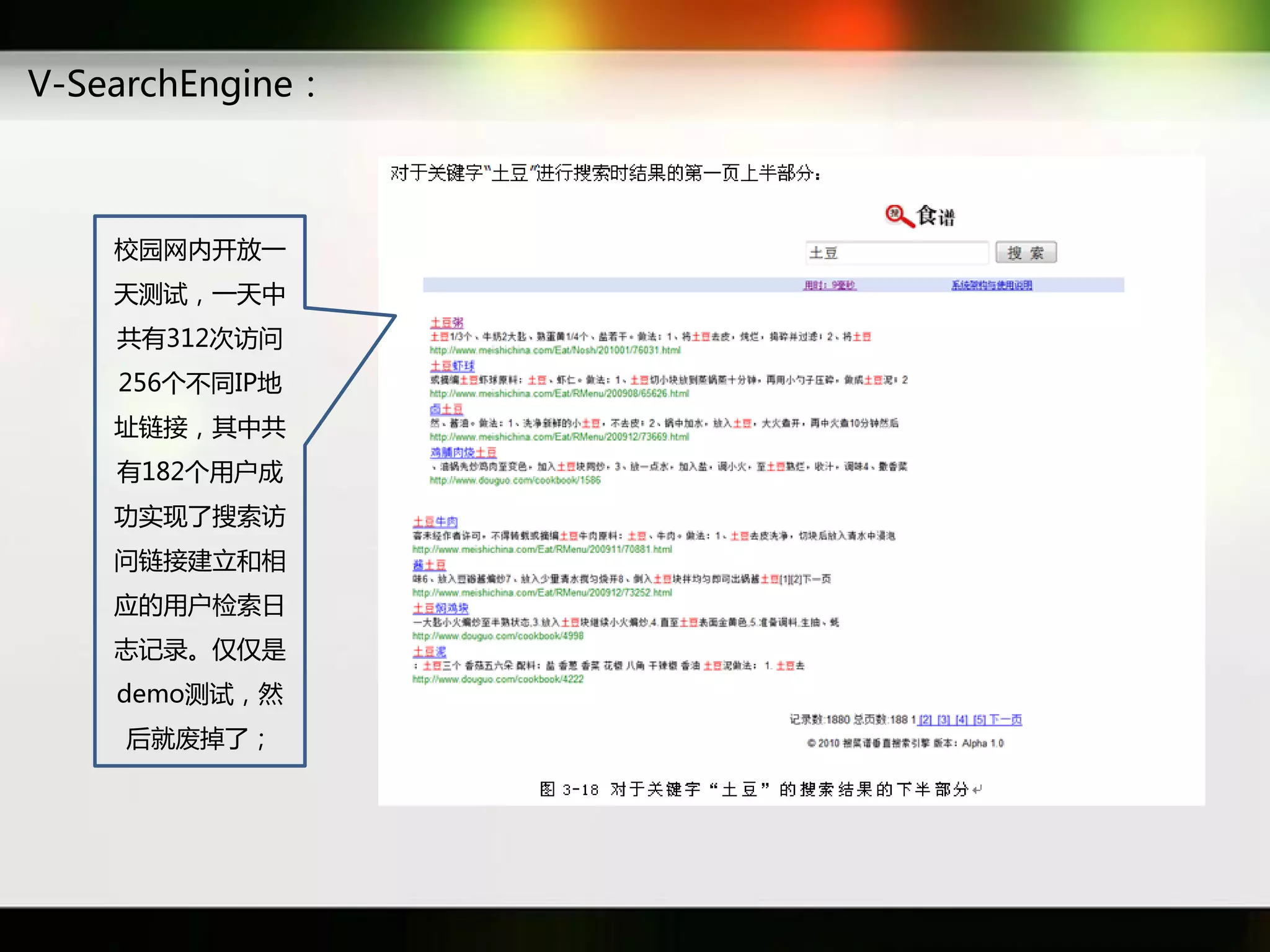
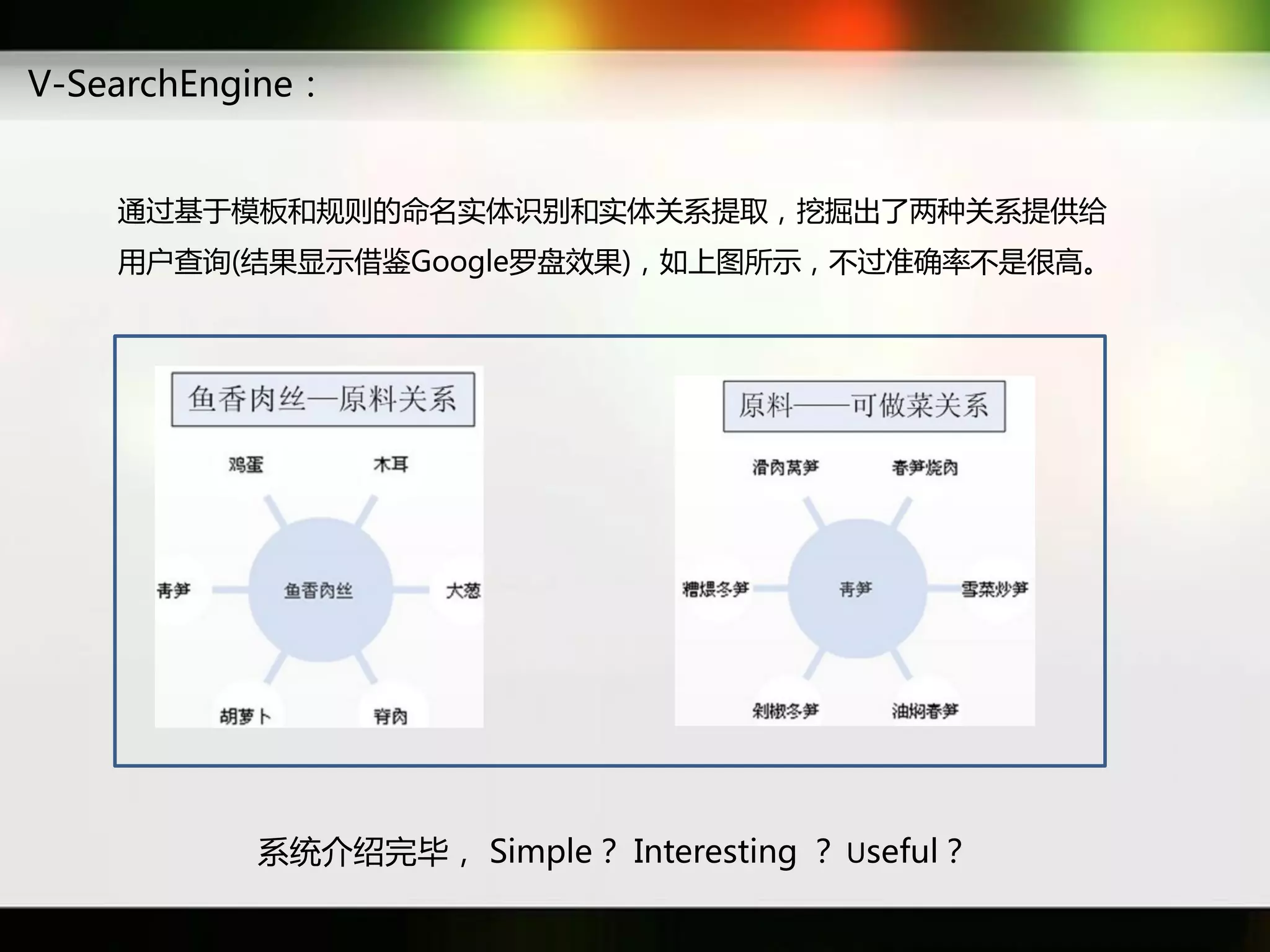
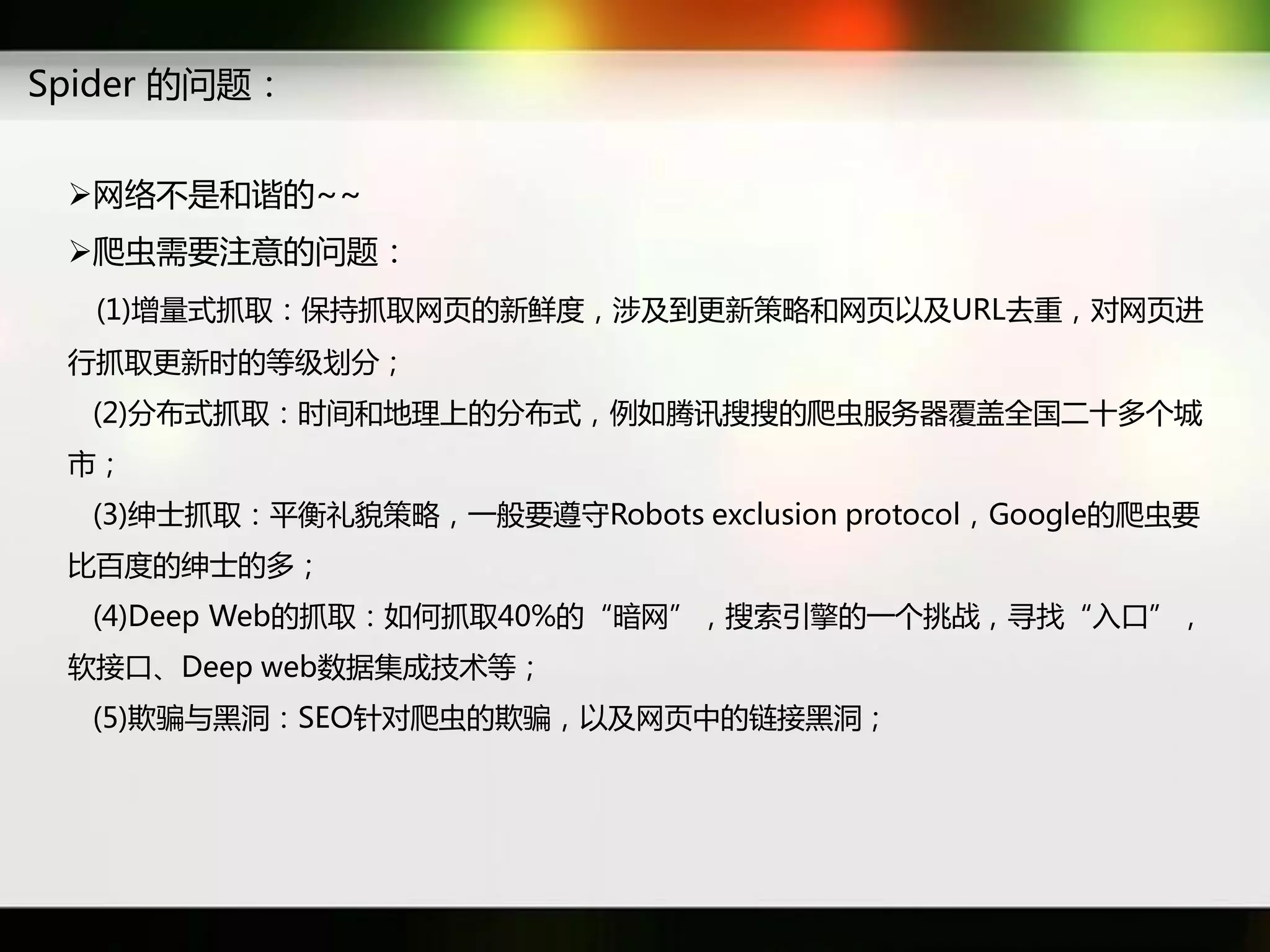
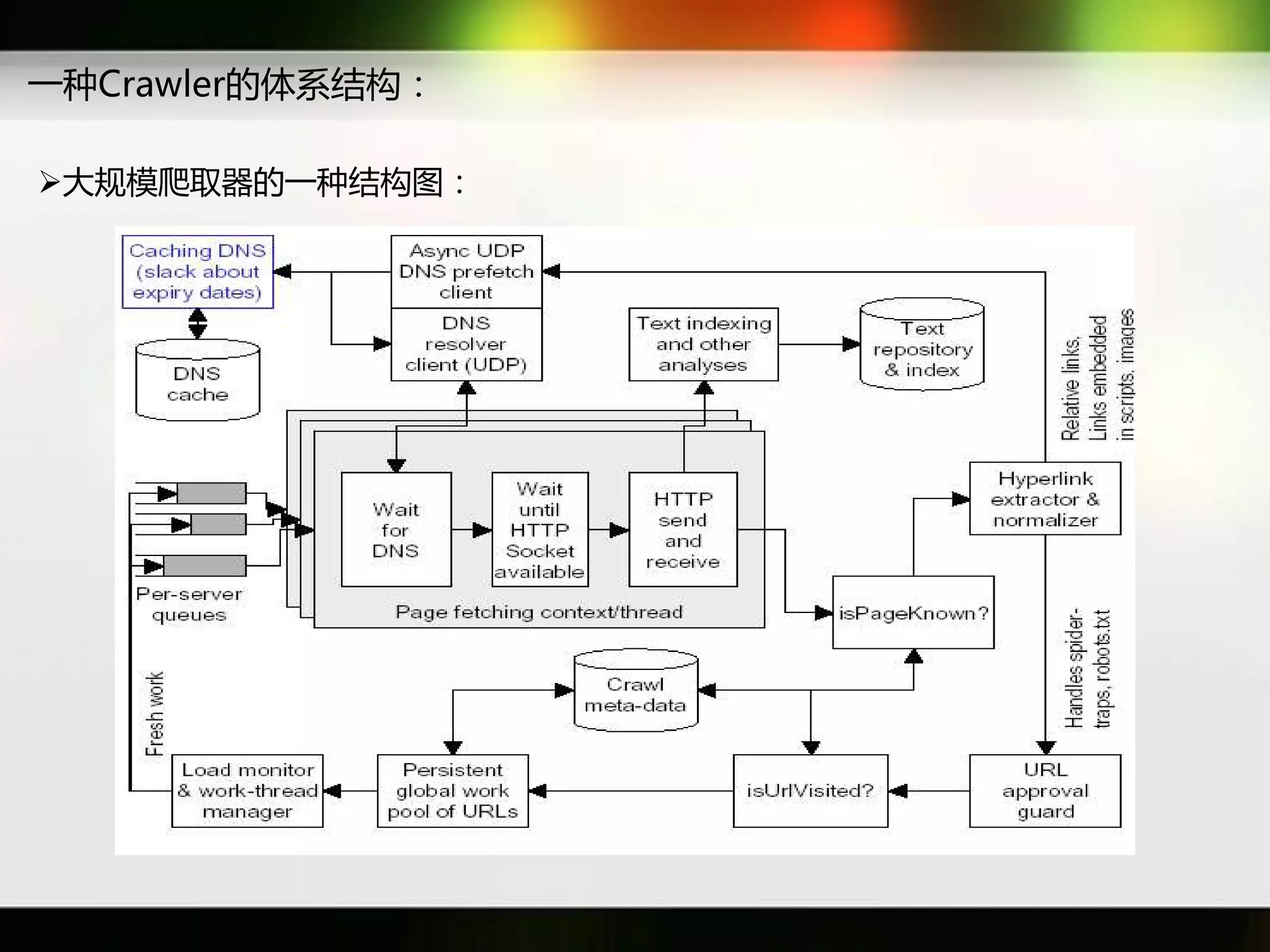
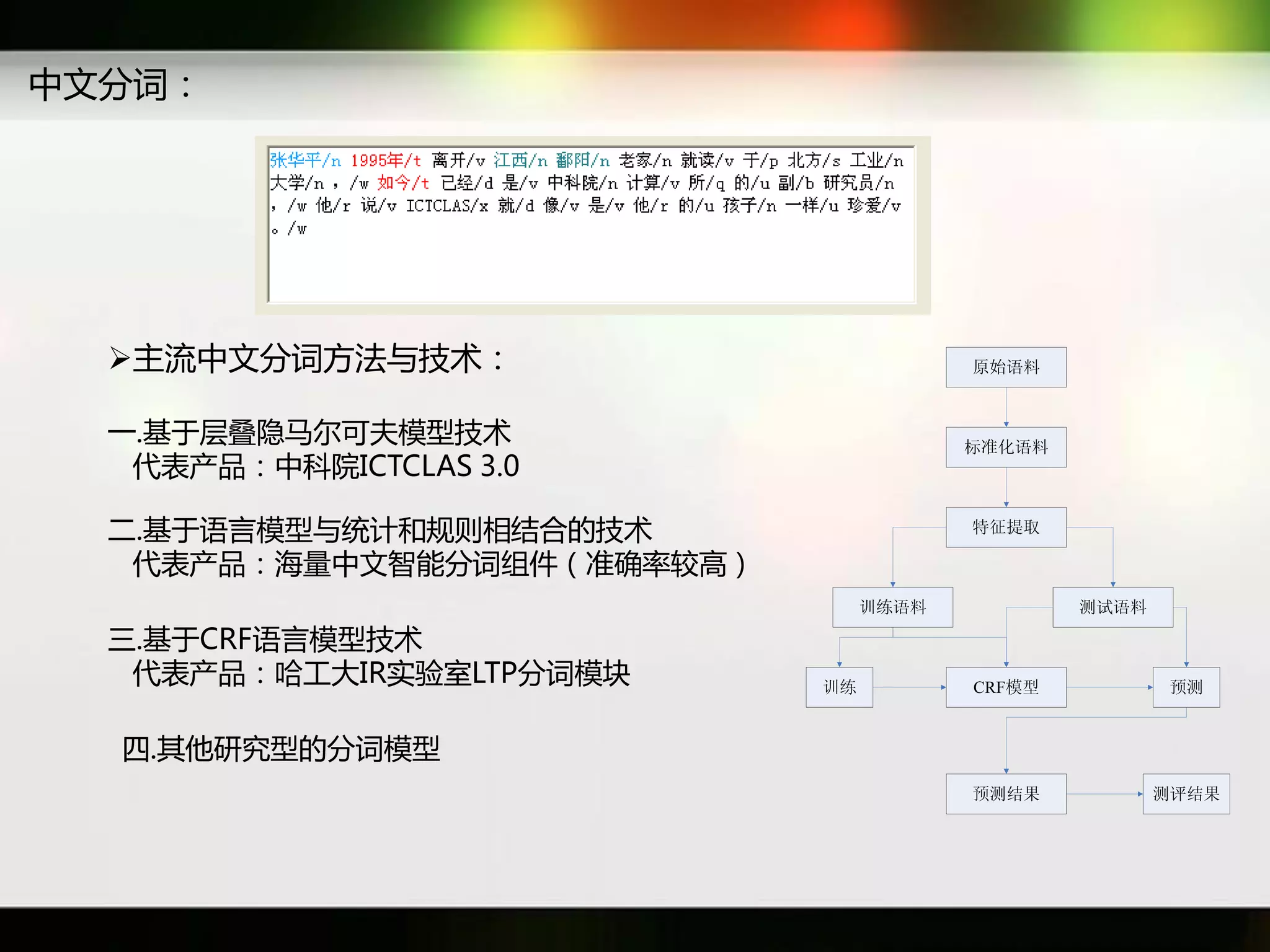
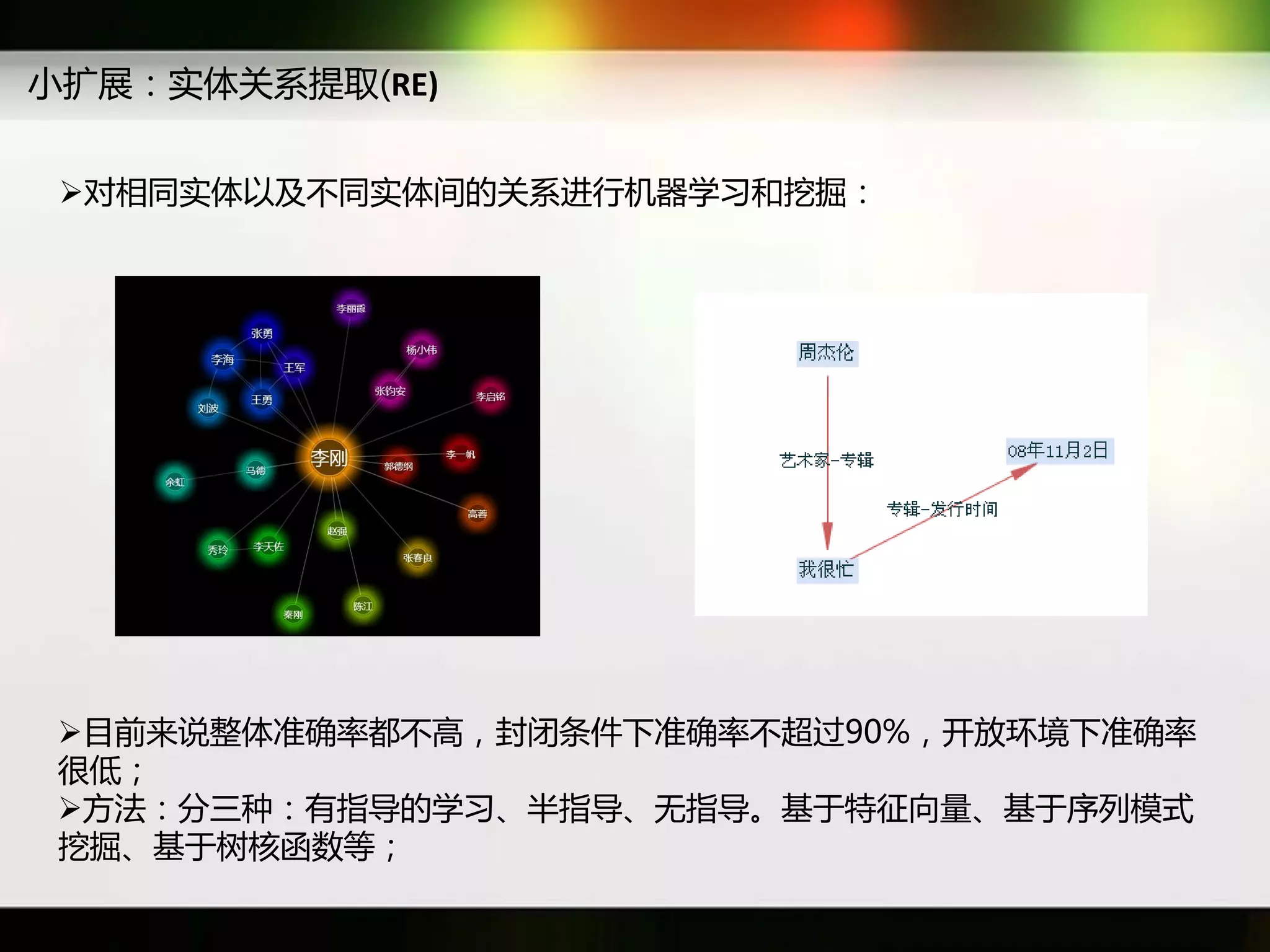
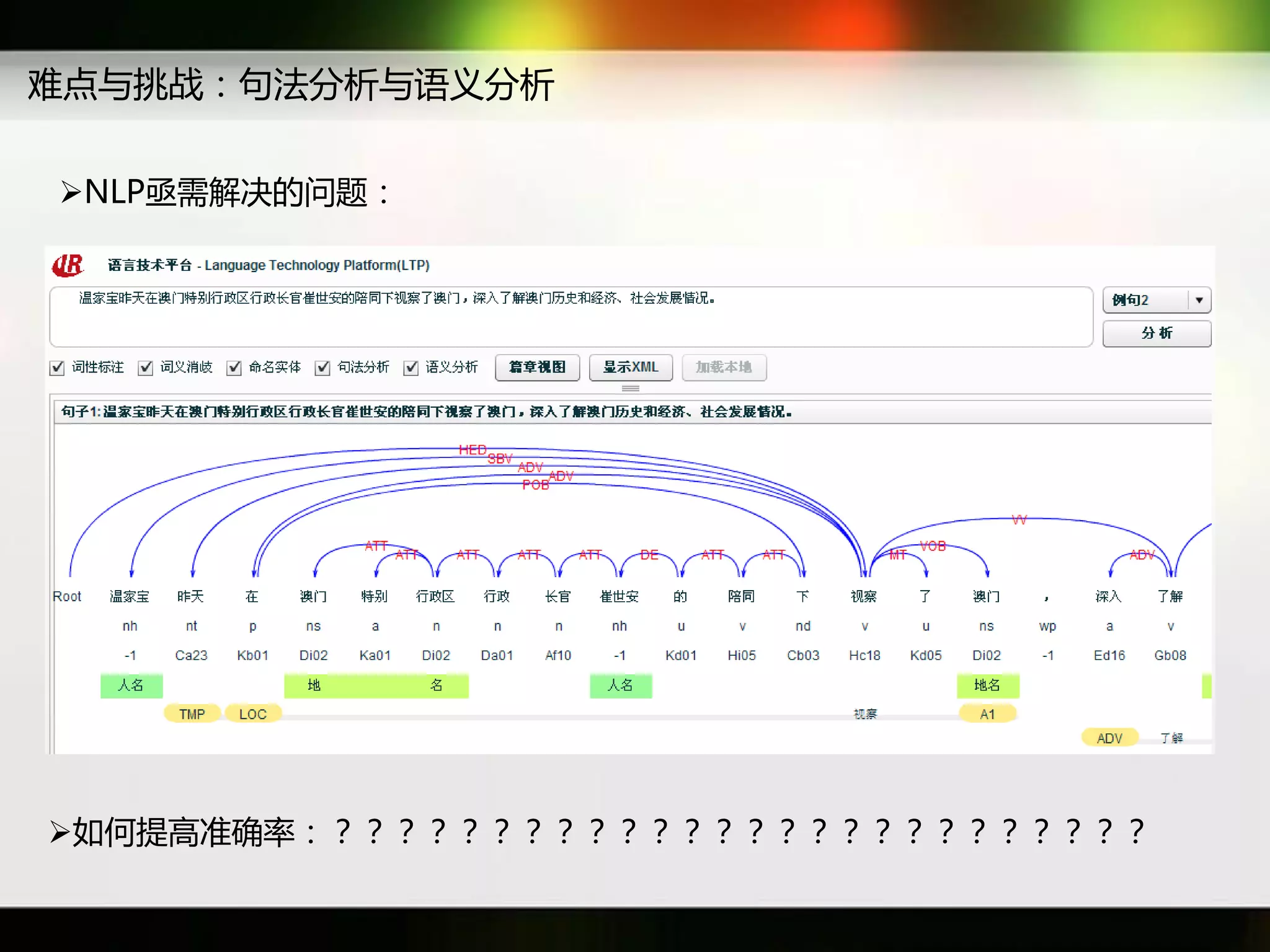
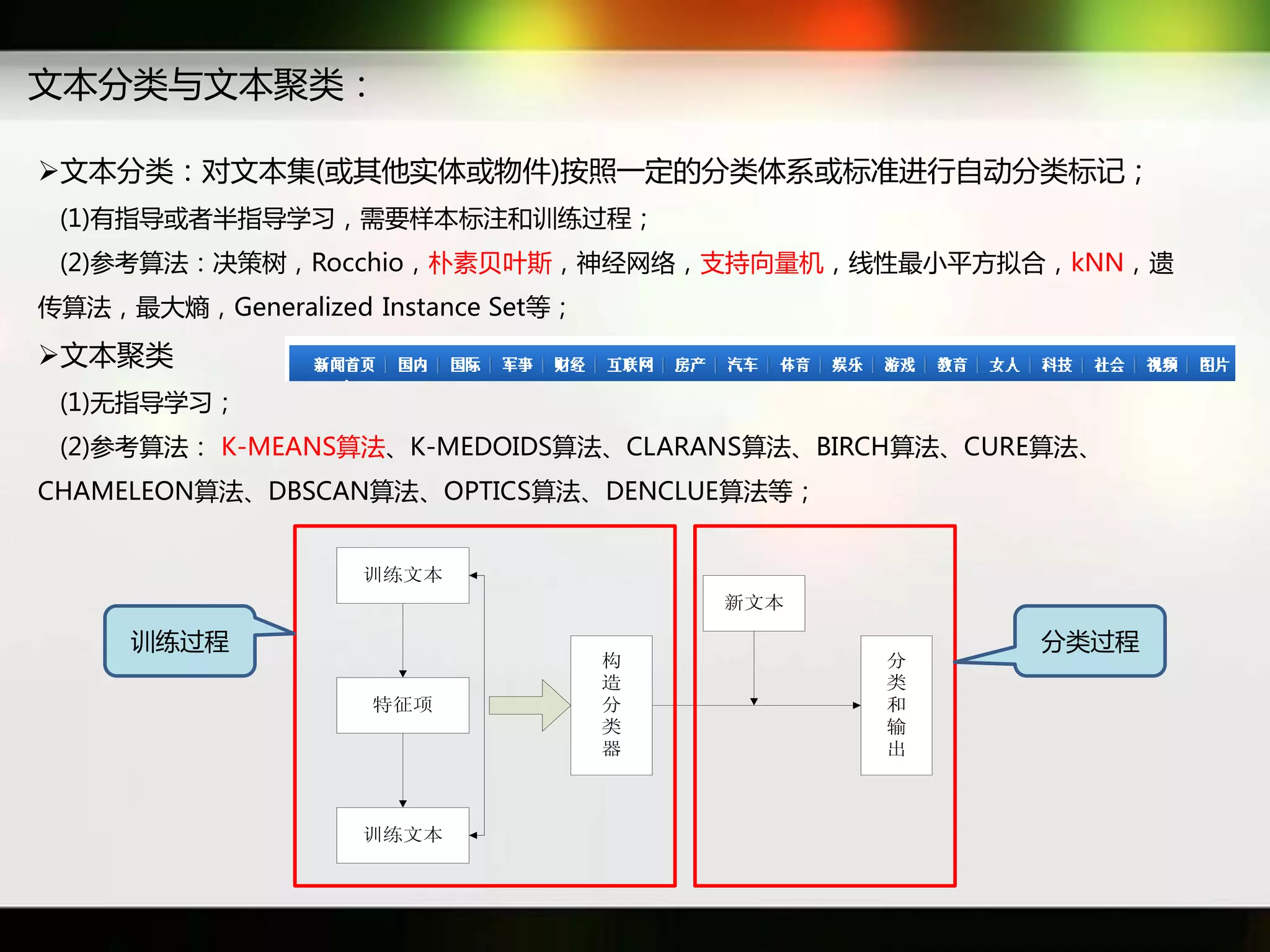
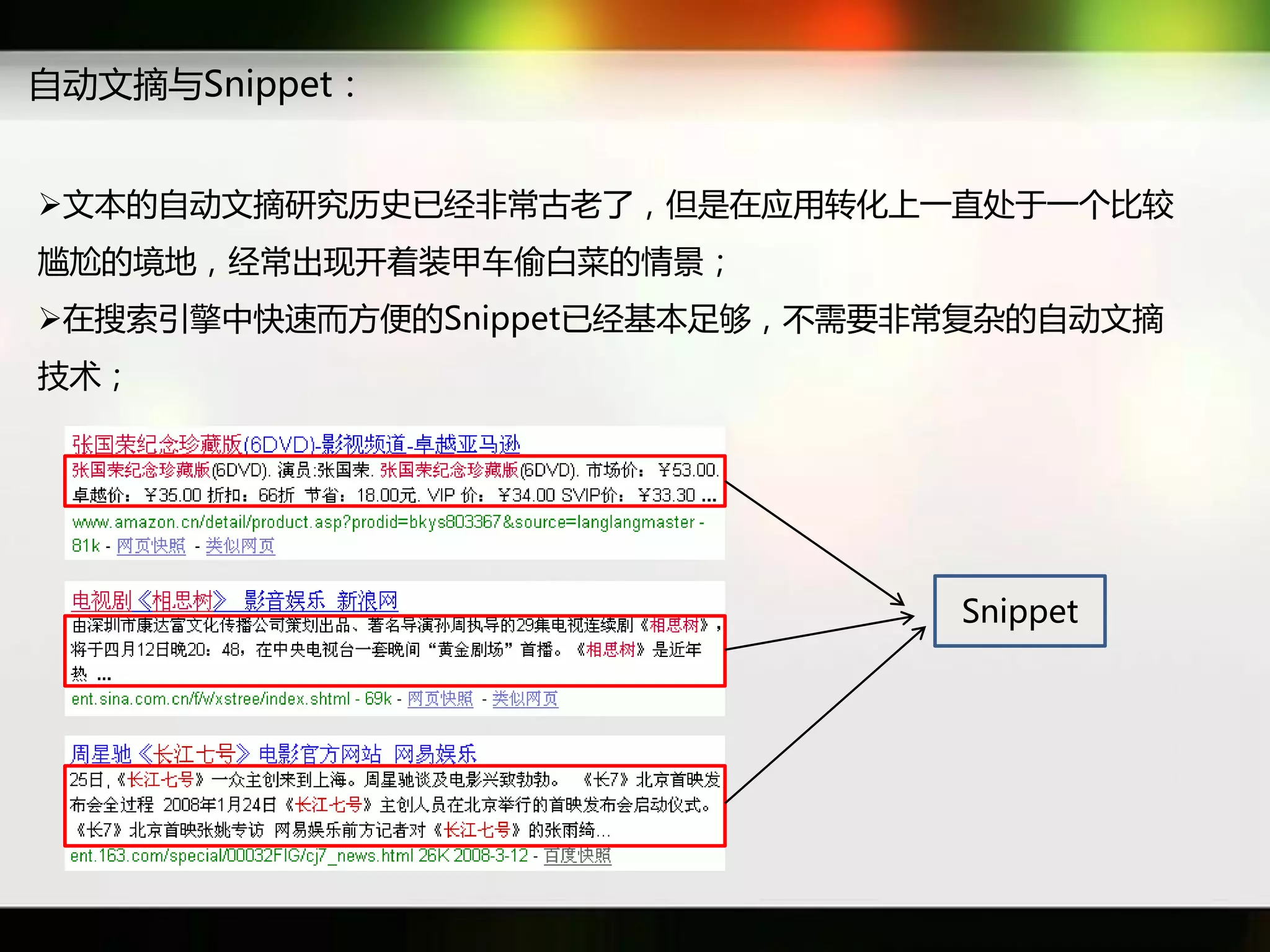
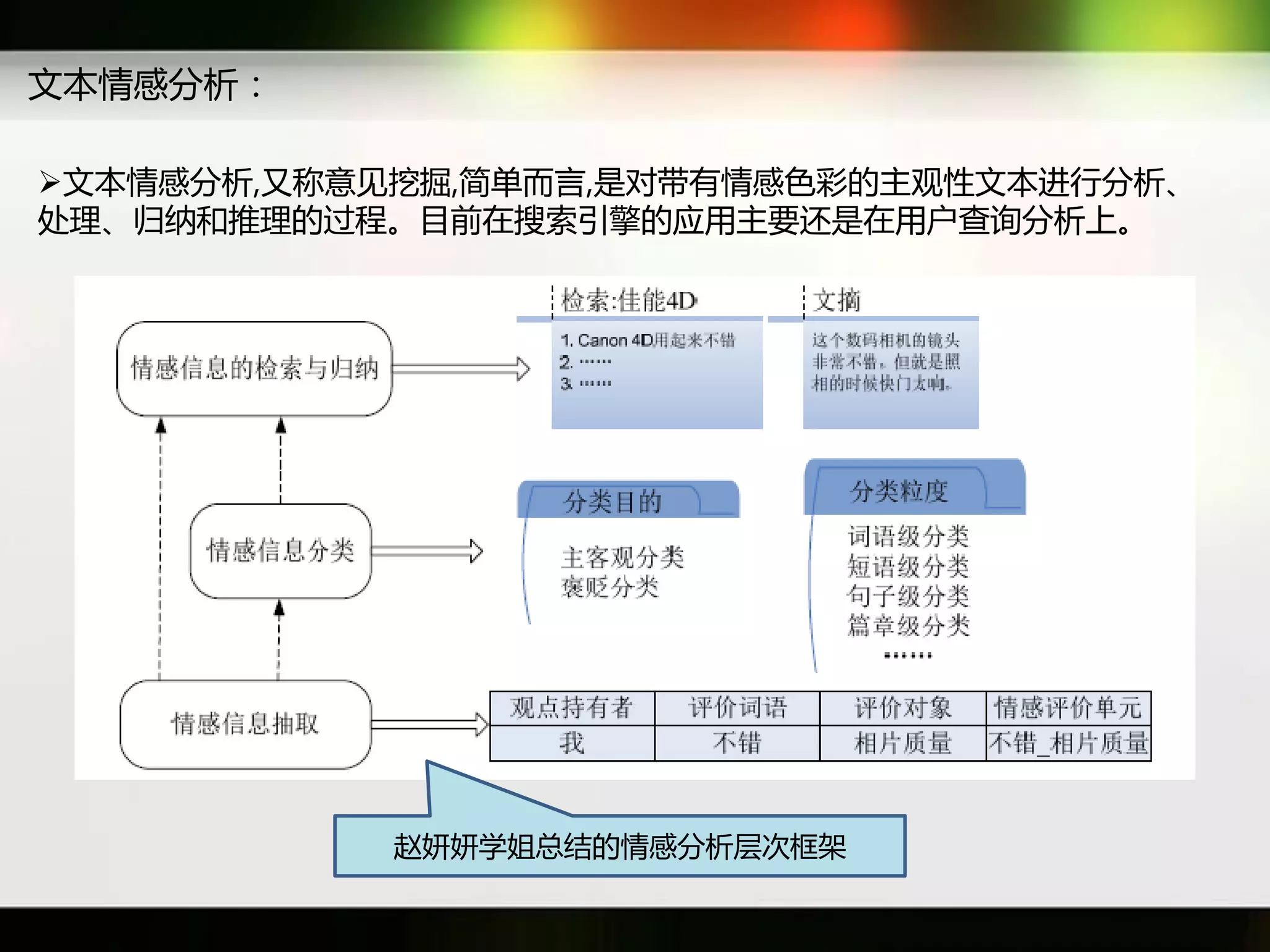
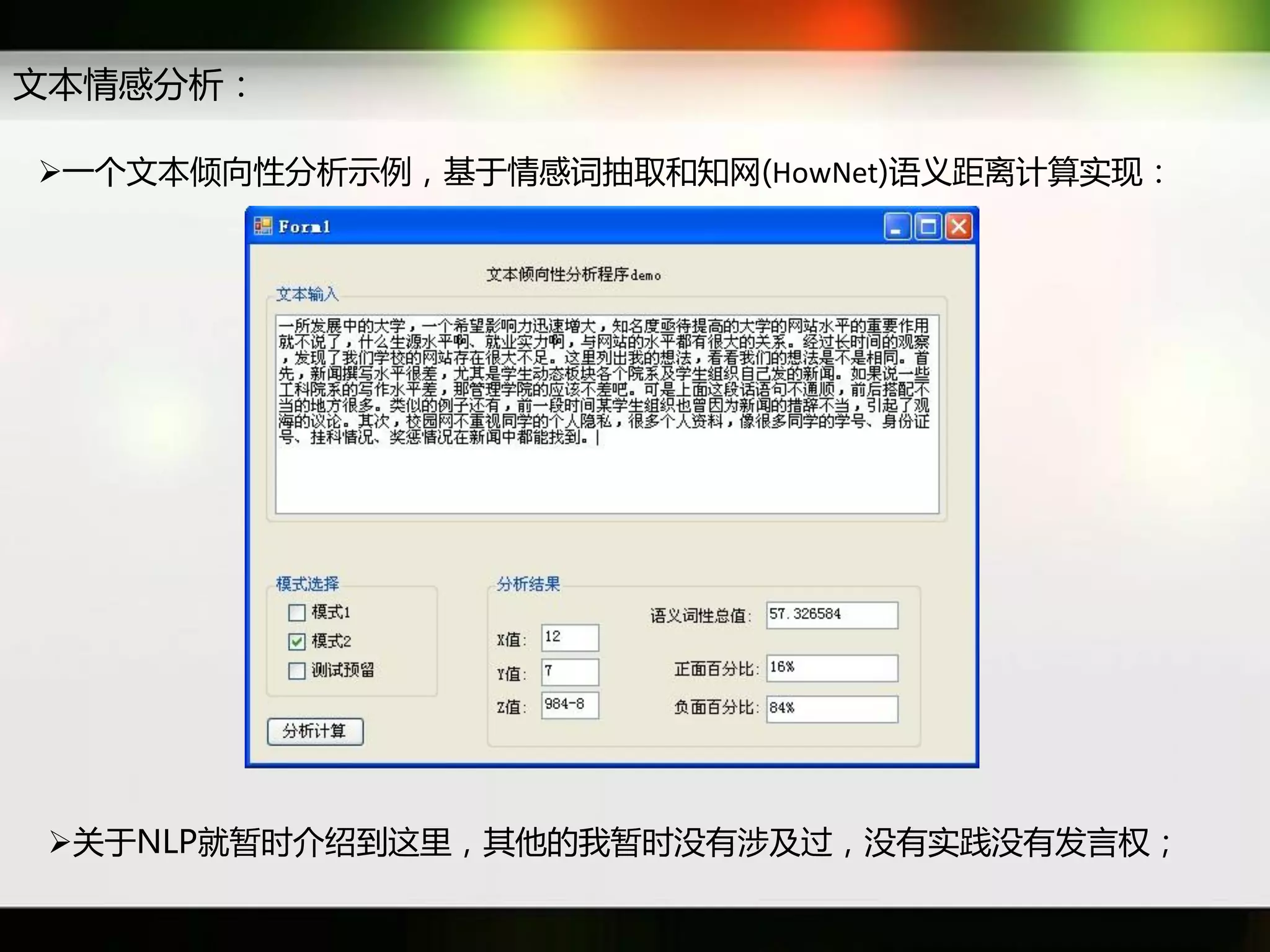
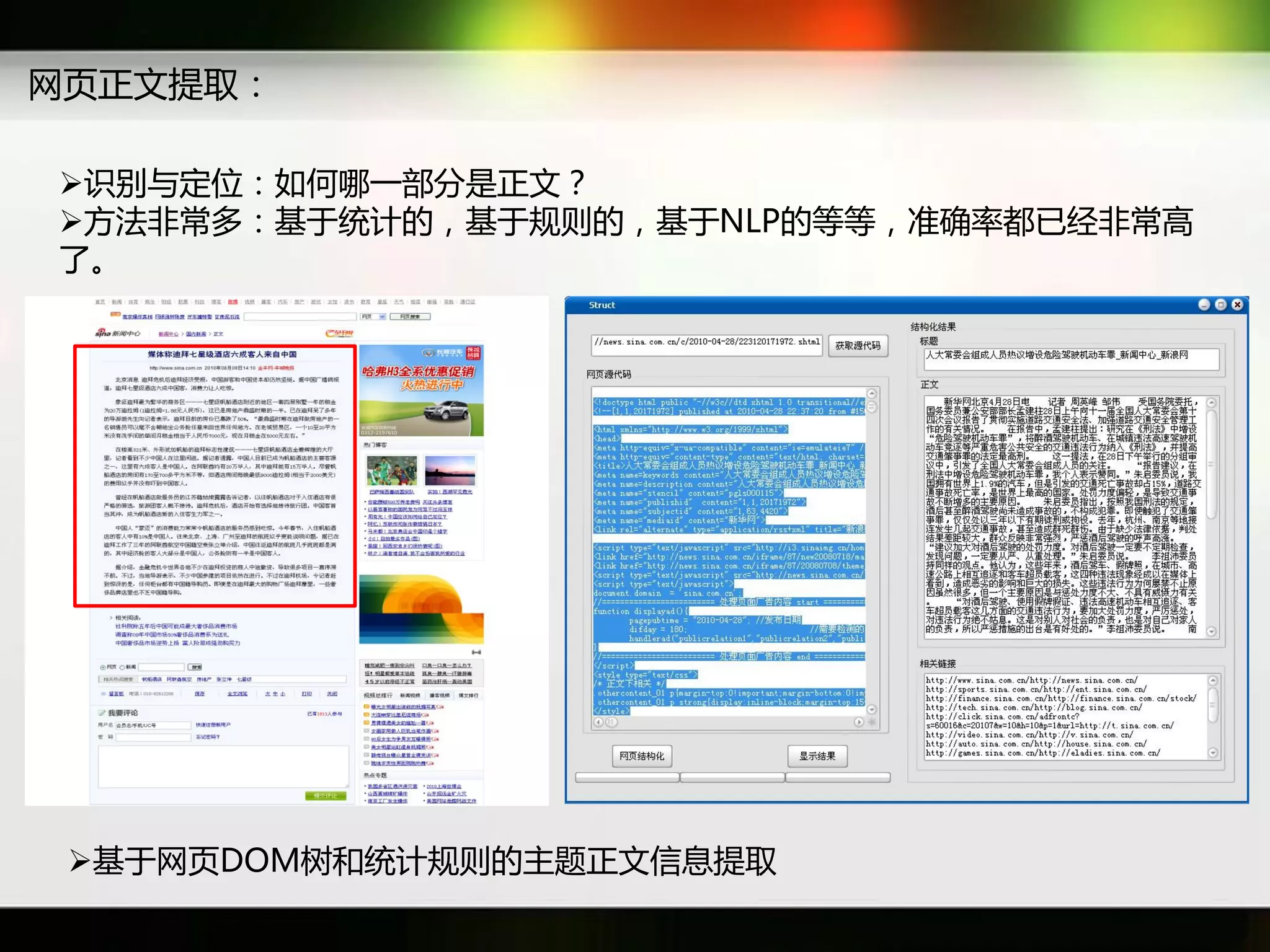
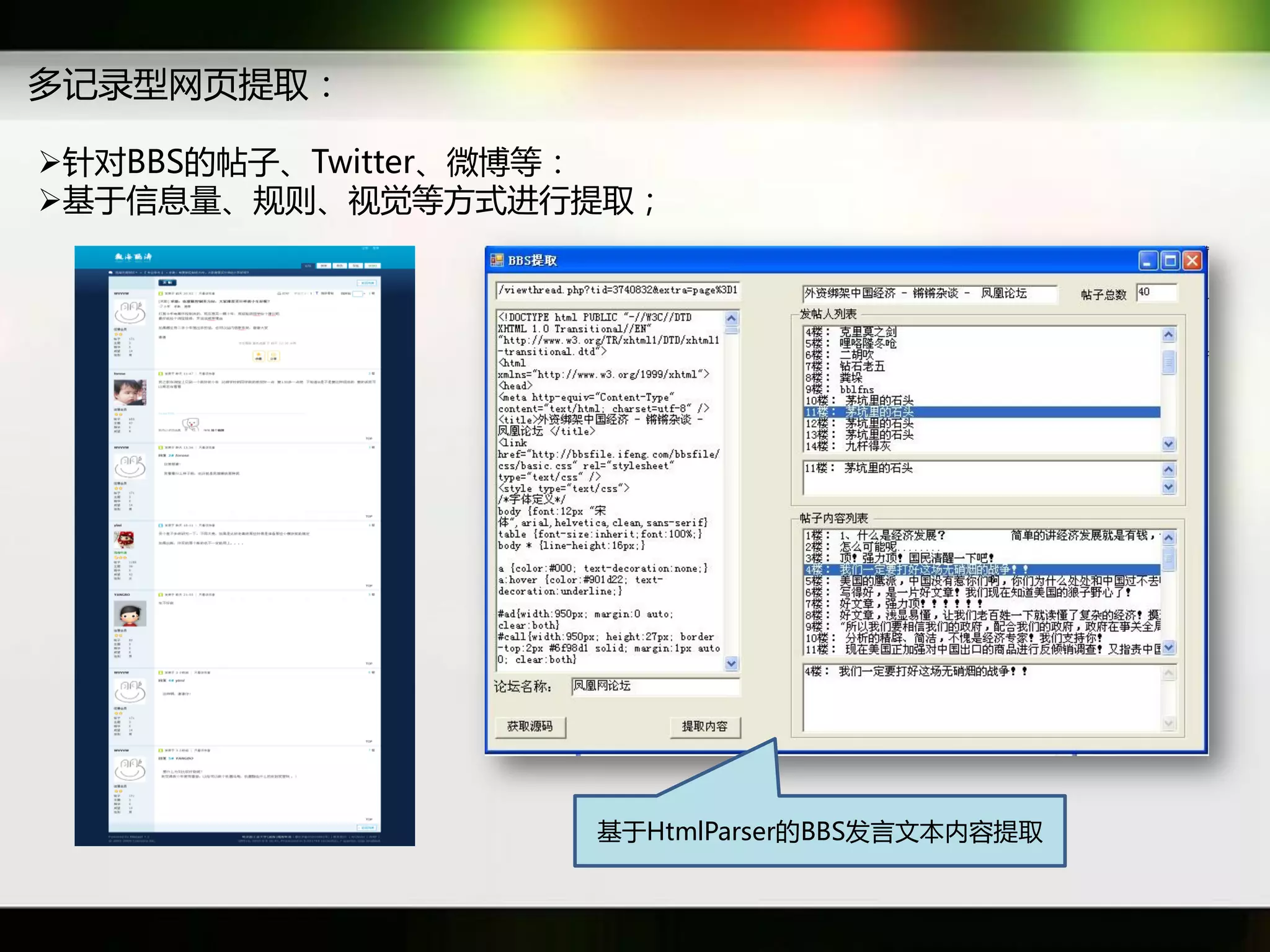
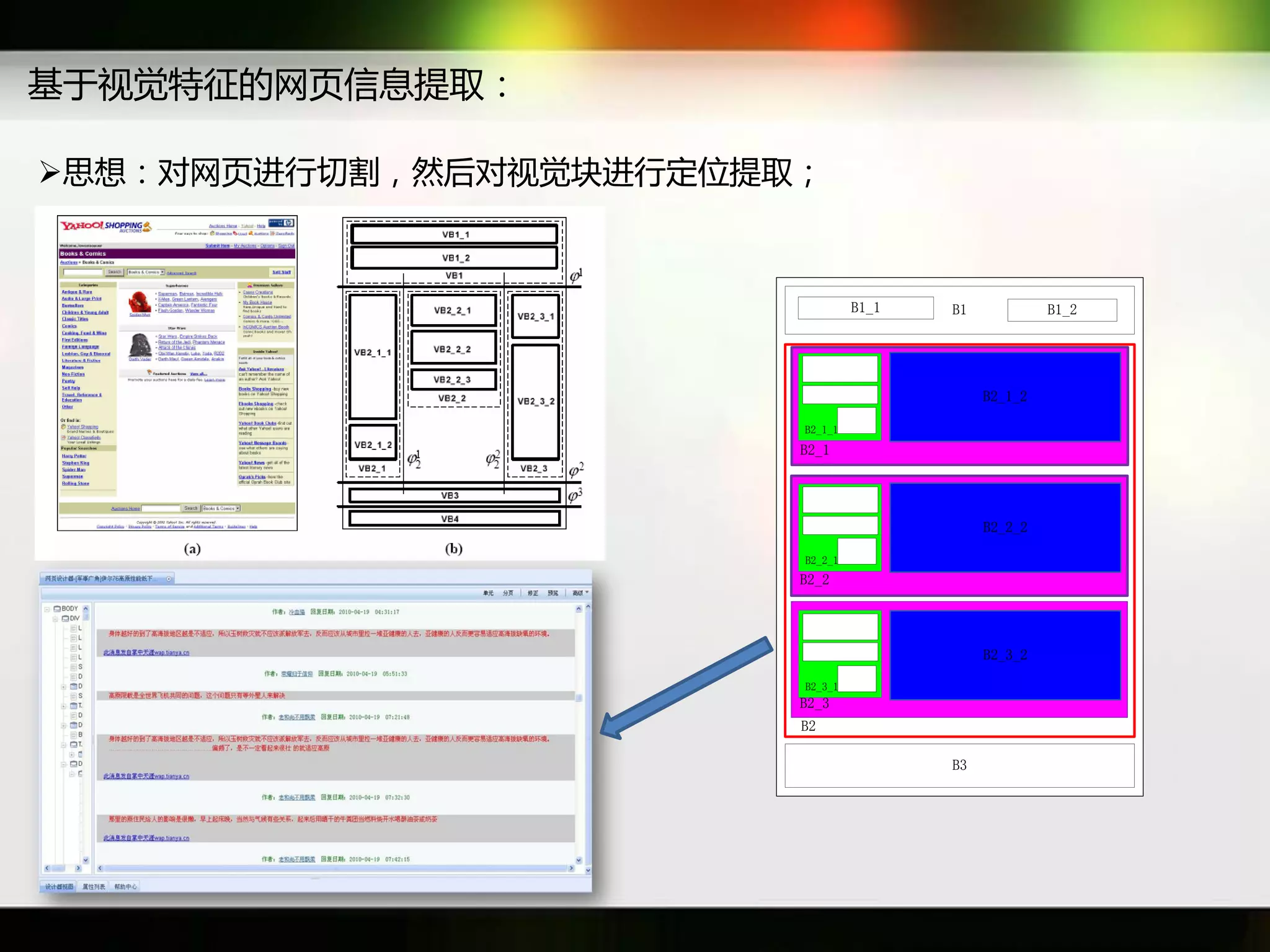
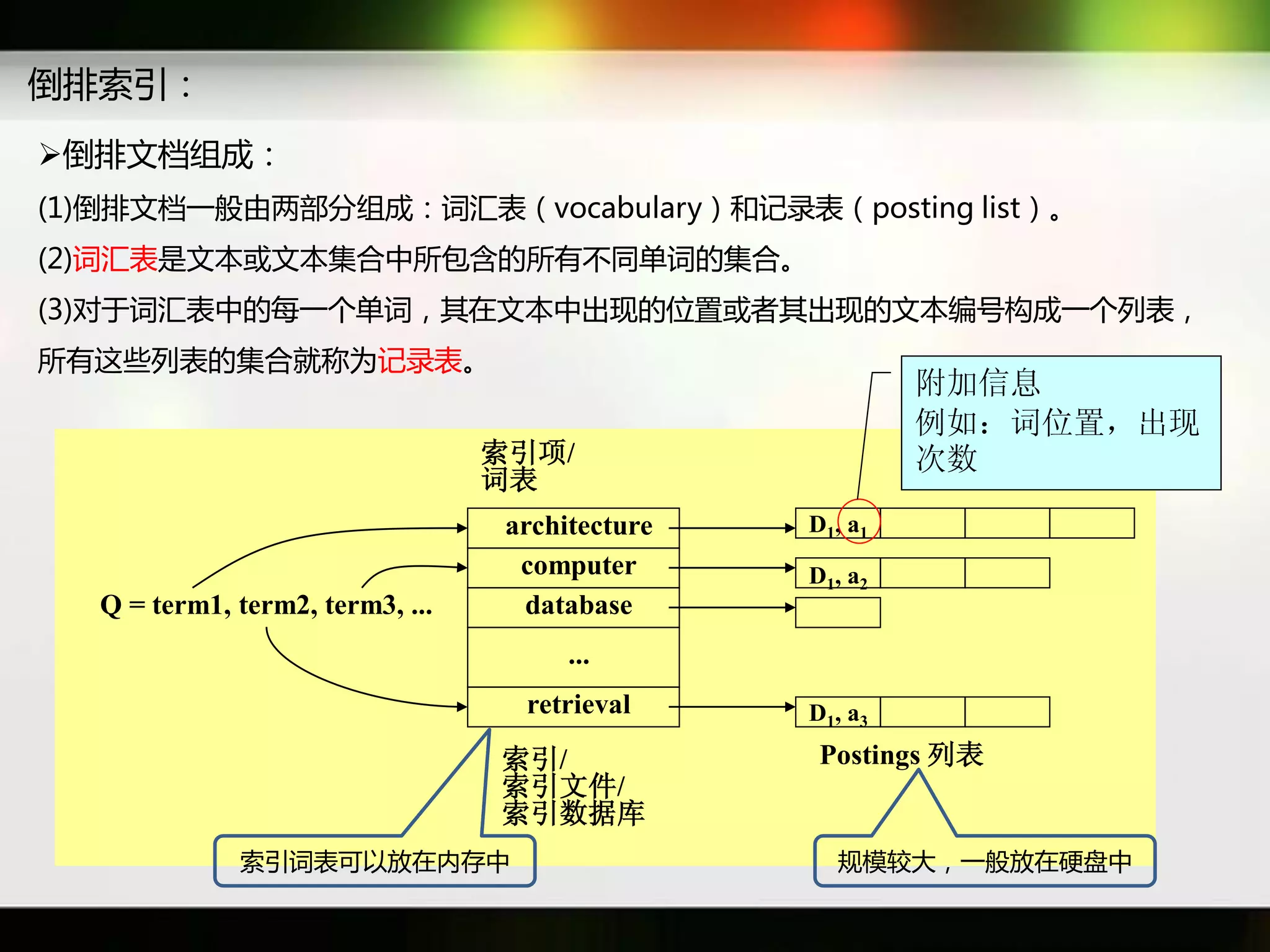
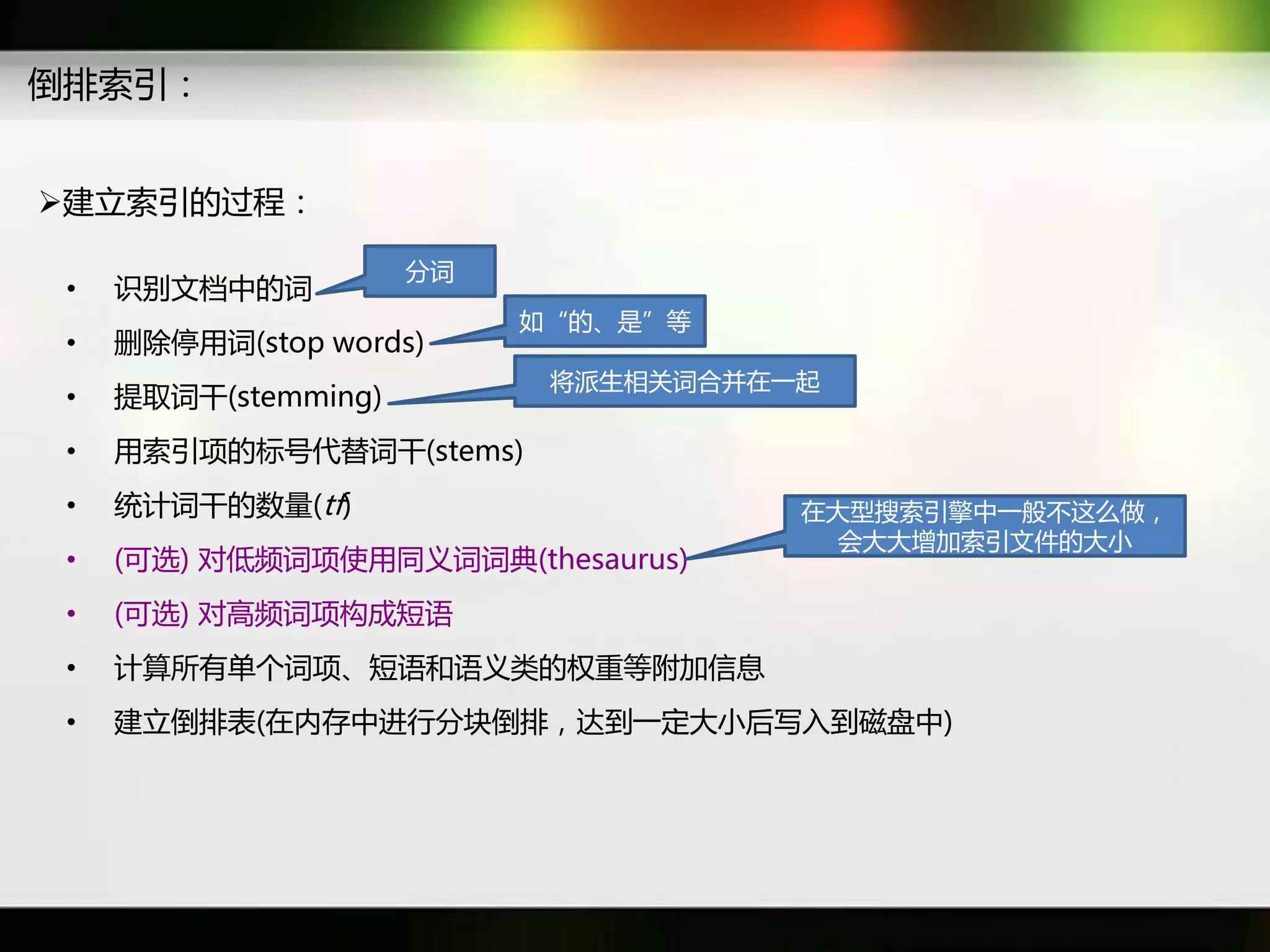
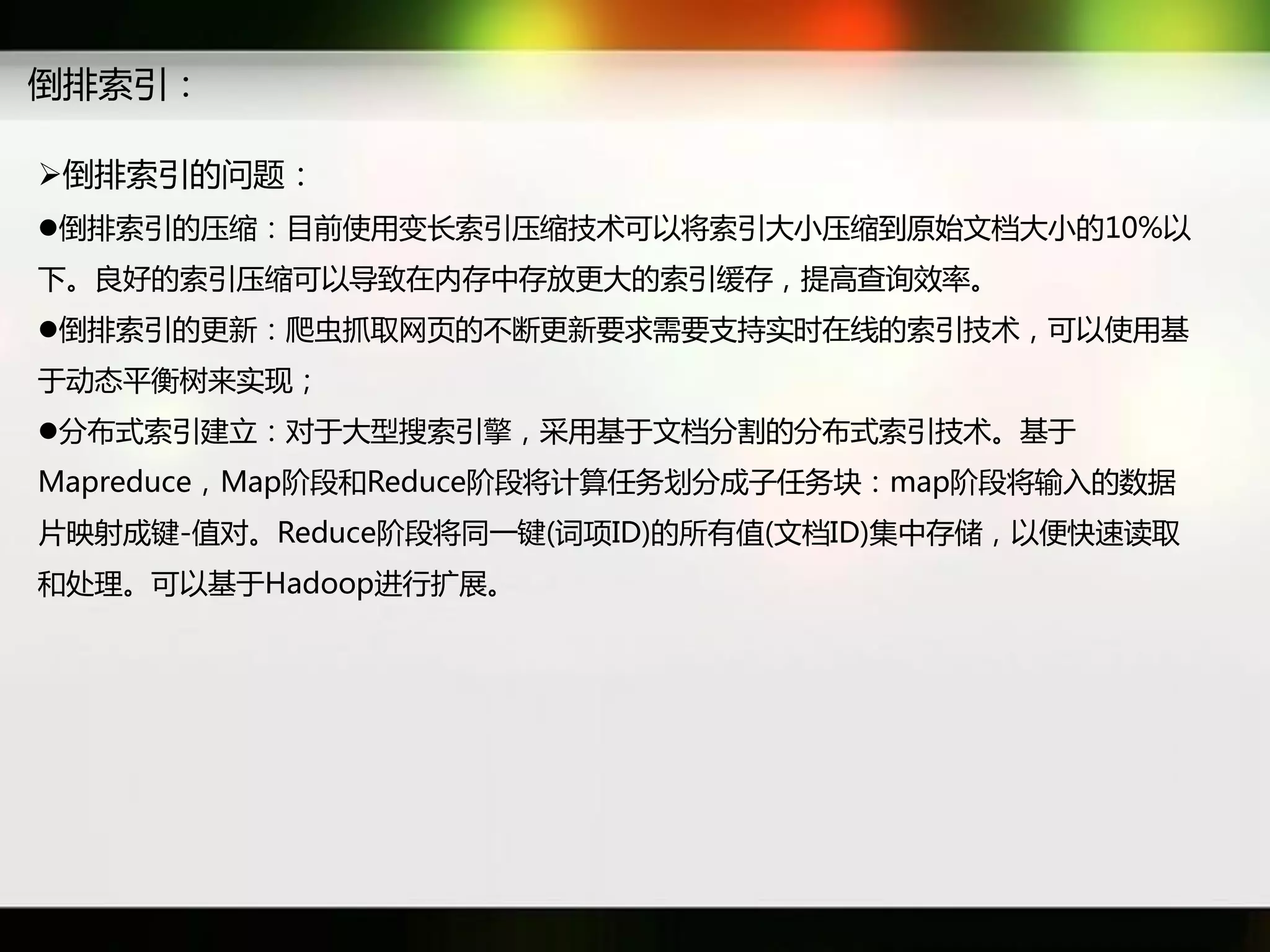
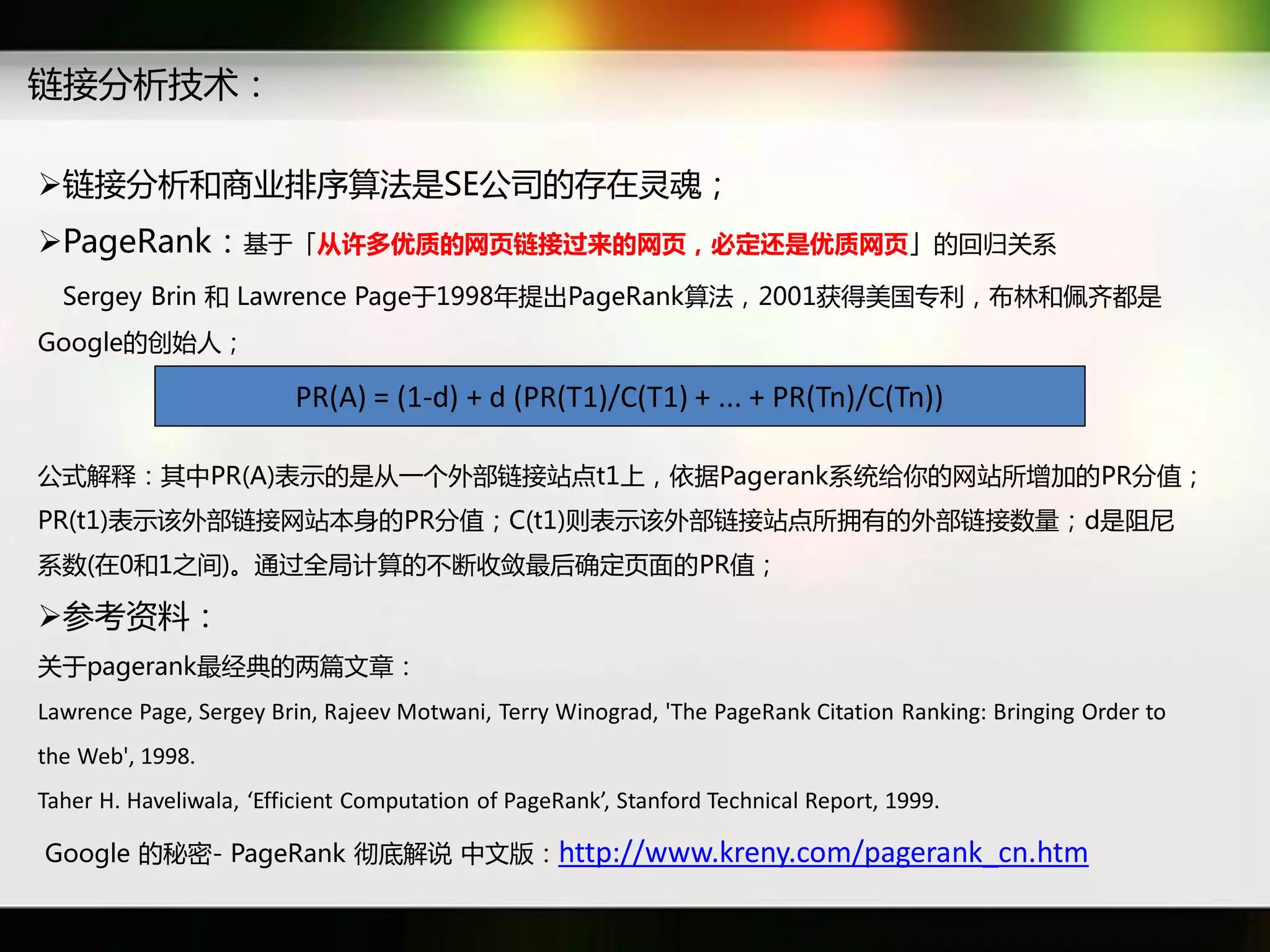
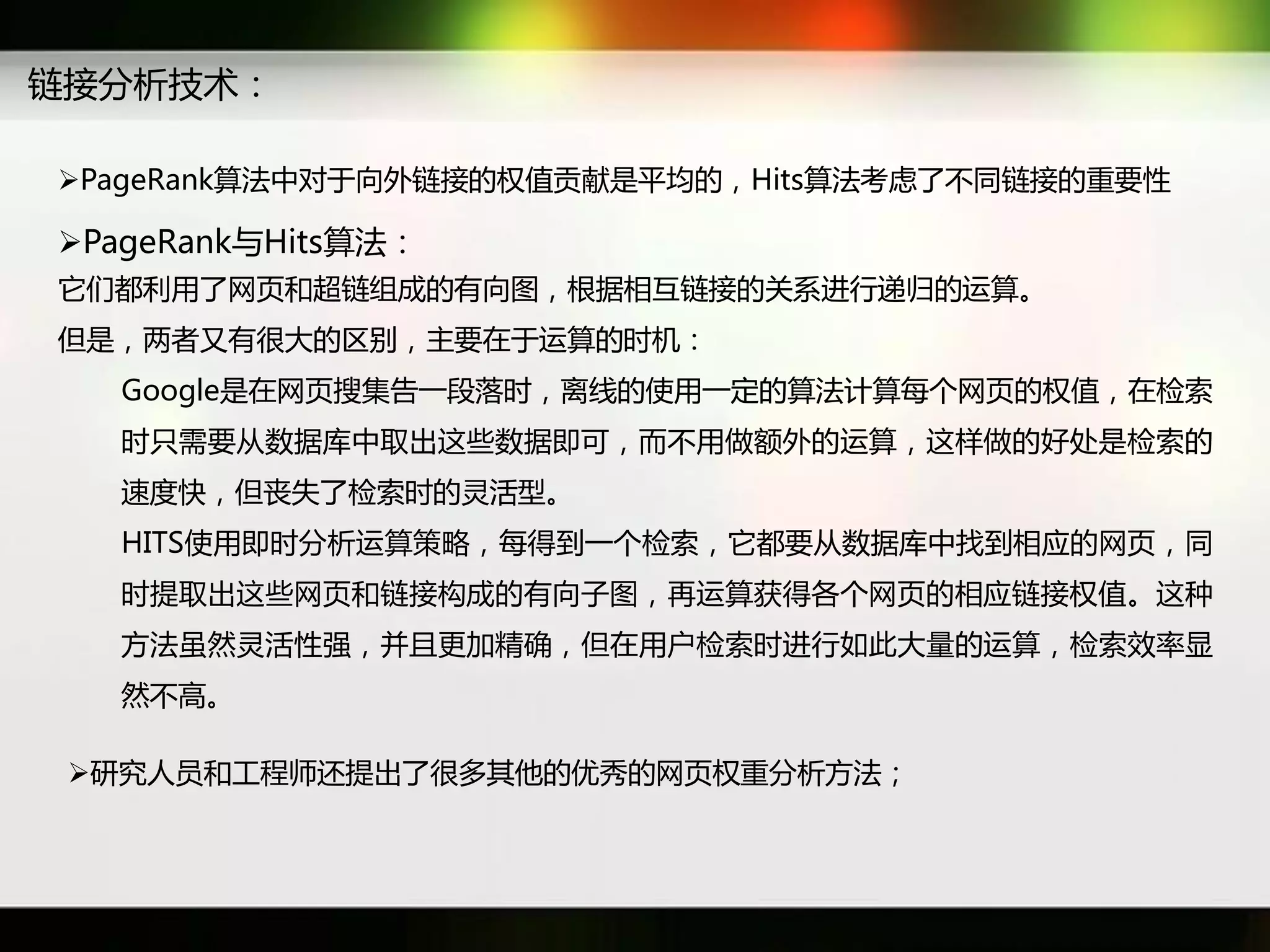
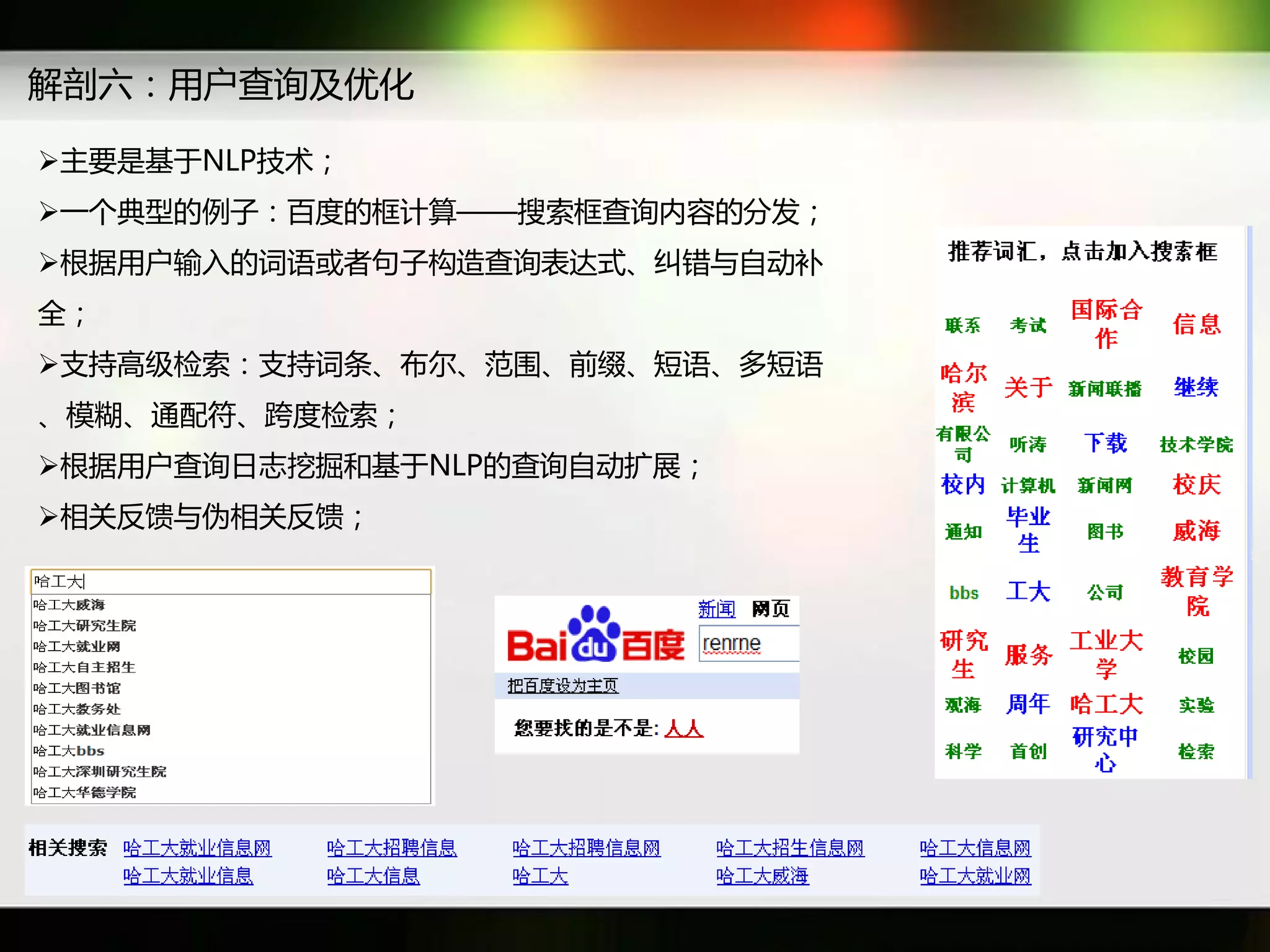
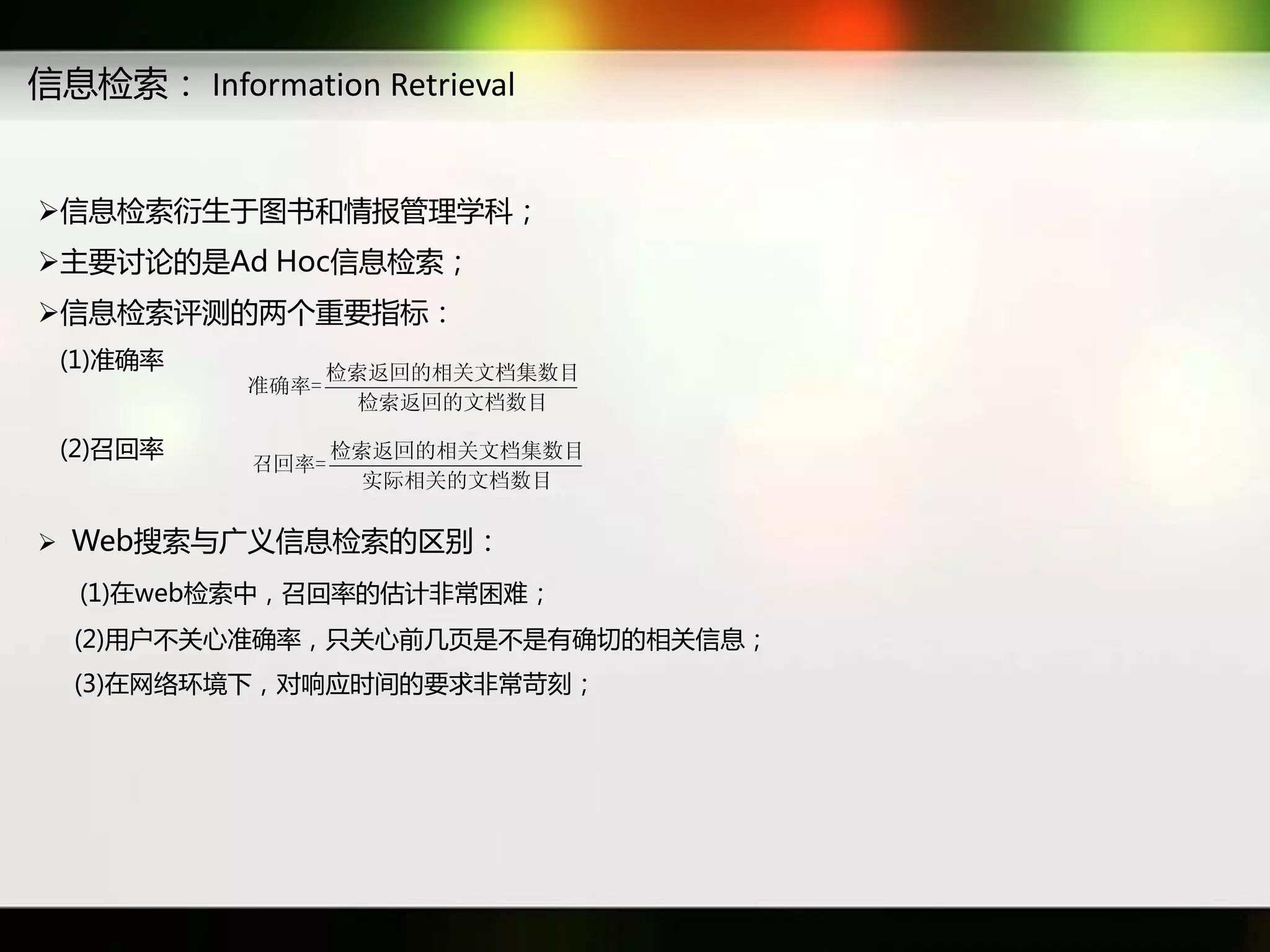
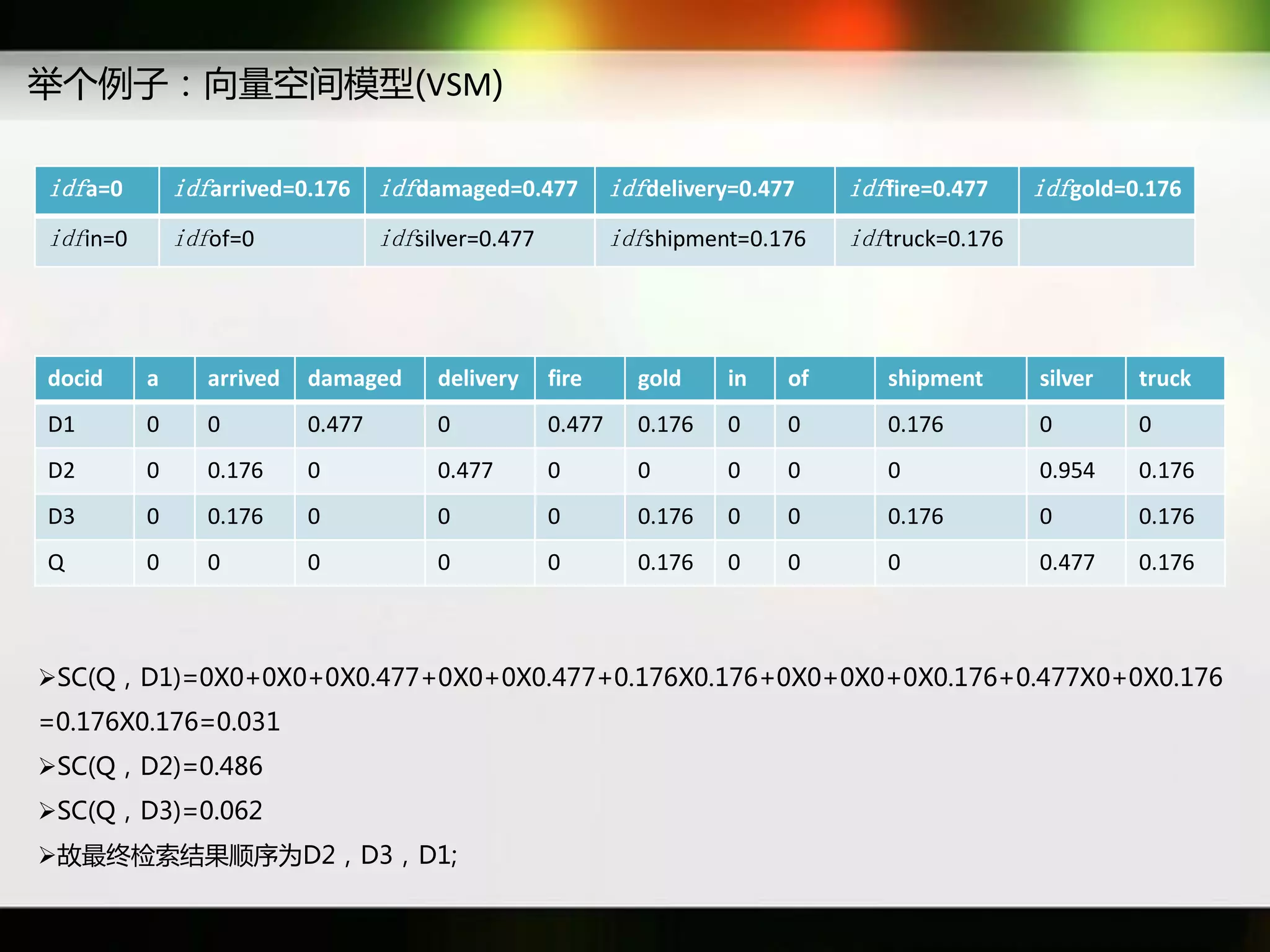
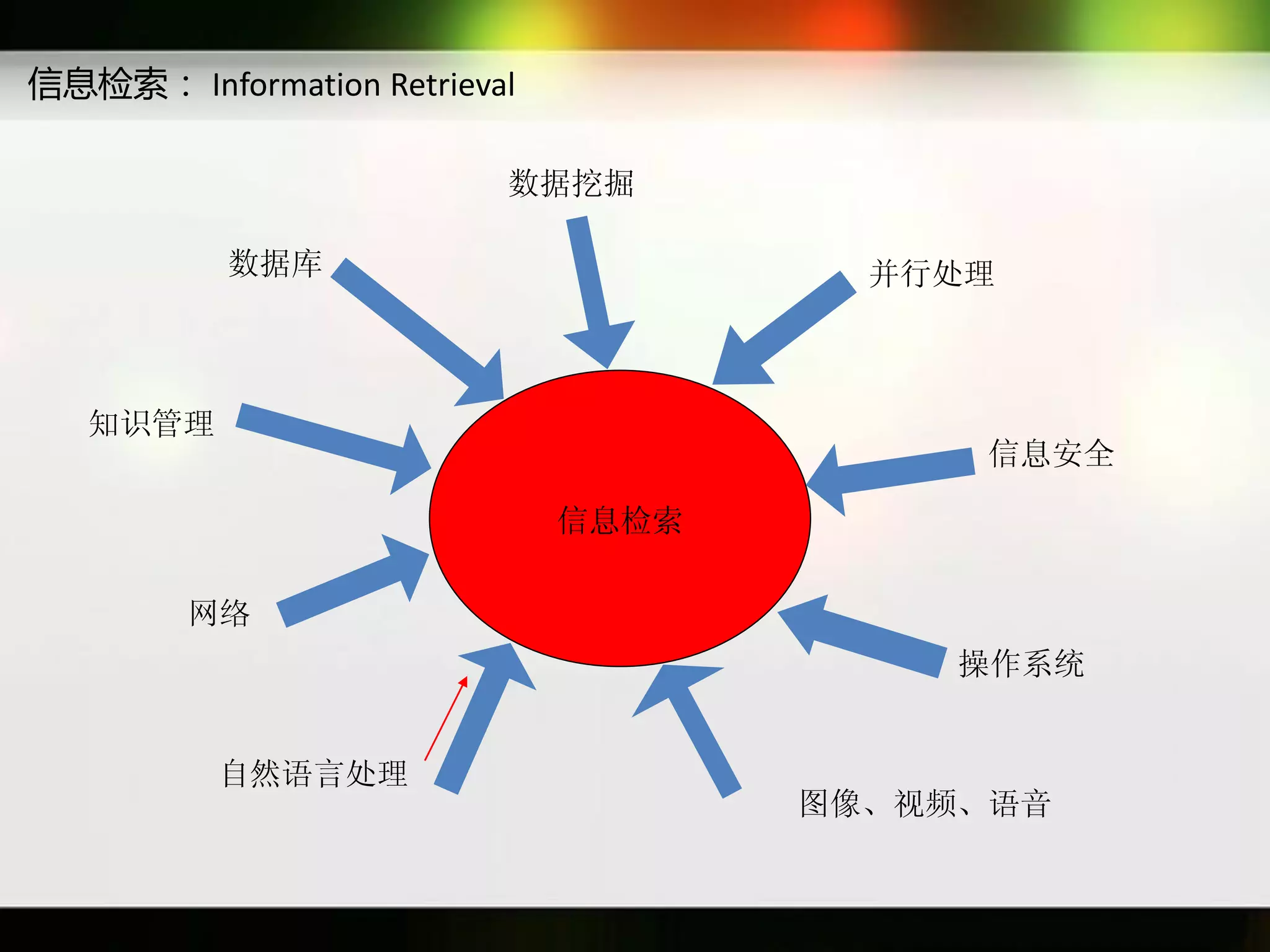
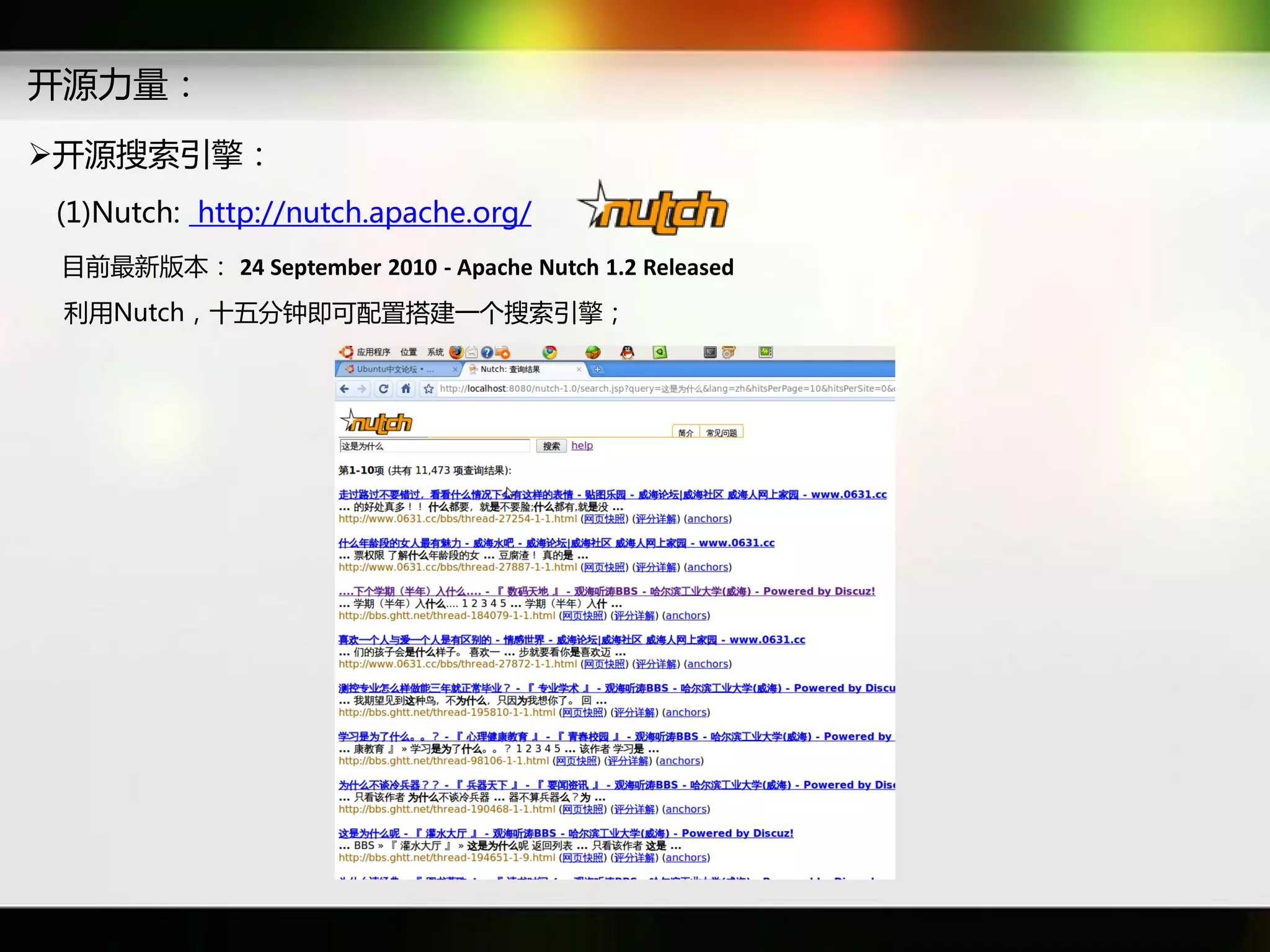
文档讨论了搜索引擎及信息检索技术的演变,重点介绍了布尔检索模型及其实现方法,包括使用倒排索引优化查询过程。在此基础上,文档还探讨了自然语言处理技术在搜索引擎中的应用,如文本分类、情感分析等,并简要介绍了v-searchengine系统的架构和功能。












![[系列活動] 手把手教你R語言資料分析實務](https://cdn.slidesharecdn.com/ss_thumbnails/stepbystepr20170114-170113030702-thumbnail.jpg?width=640&height=640&fit=bounds)
![[系列活動] Python 爬蟲實戰](https://cdn.slidesharecdn.com/ss_thumbnails/pythonafunjimv1-171213041823-thumbnail.jpg?width=640&height=640&fit=bounds)

![[系列活動] Python爬蟲實戰](https://cdn.slidesharecdn.com/ss_thumbnails/python-170809083644-thumbnail.jpg?width=640&height=640&fit=bounds)










![[系列活動] 手把手打開Python資料分析大門](https://cdn.slidesharecdn.com/ss_thumbnails/python-171213042421-thumbnail.jpg?width=640&height=640&fit=bounds)



![[系列活動] Python 程式語言起步走](https://cdn.slidesharecdn.com/ss_thumbnails/python20170812-170808043244-thumbnail.jpg?width=640&height=640&fit=bounds)





















![Lucene 3[1] 0 原理与代码分析](https://cdn.slidesharecdn.com/ss_thumbnails/lucene31-0-100225194736-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
