Downloaded 15 times




![How much do we actually save in the
real world use case?
Column Type Column Type
advertiserId int memberId int
creativeId int industry int
campaignId int region int
campaignType String seniority String
age char titles Int[]
company int requestType String
education int time int
function String impressionCount int
gender char](https://image.slidesharecdn.com/indextypes-121126080051-phpapp02/85/Index-types-9-320.jpg)


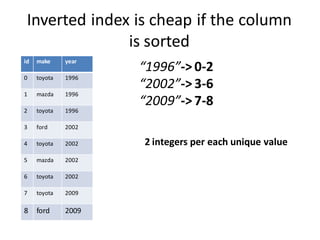
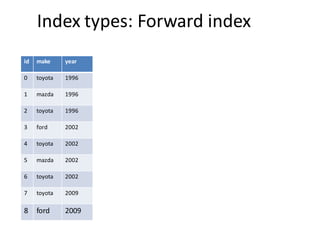
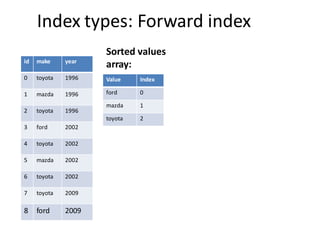
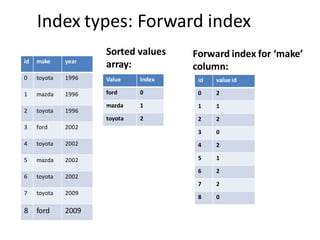
The document discusses different types of indexes that can be used for columnar data, including inverted indexes and forward indexes. It explains that inverted indexes are cheap to store if the column is sorted, as each unique value only needs to be stored once along with its positions. Forward indexes require storing a mapping from unique values to their IDs. This mapping can be compressed using dictionary compression or fixed bit encoding to reduce the space needed. In real use cases, Pinot is able to compress indexes to require only 16 bytes per document while other systems may use over 100 bytes, allowing Pinot to store 7 times more documents in memory.





































