1. Index?
1.1 Whatan index is
1.2 Benefits
1.3 Overhaed
2. Recommendations for design
3. Clustered and nonclustered indexes
4. Advance indexing techniques
5. Additional characteristics
목차
4.
1. Index?
What Isan Index
4 / 30
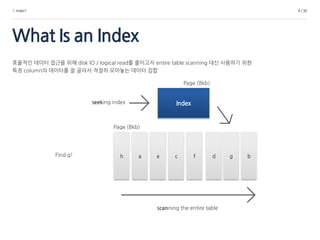
효율적인 데이터 접근을 위해 disk IO / logical read를 줄이고자 entire table scanning 대신 사용하기 위한
특정 column의 데이터를 잘 골라서 적절히 모아놓는 데이터 집합
Index
h a e c f d g b
scanning the entire table
seeking index
Find g!
Page (8kb)
Page (8kb)
5.
1. Index?
Benefit &Overhead
5 / 30
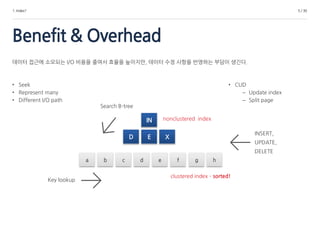
데이터 접근에 소모되는 I/O 비용을 줄여서 효율을 높이지만, 데이터 수정 사항을 반영하는 부담이 생긴다.
• Seek
• Represent many
• Different I/O path
• CUD
– Update index
– Split page
a b c d e f g h
IN
D E X
Search B-tree
Key lookup
nonclustered index
clustered index – sorted!
INSERT,
UPDATE,
DELETE
2. Recommendations fordesign
Index Design Recommendations
7 / 30
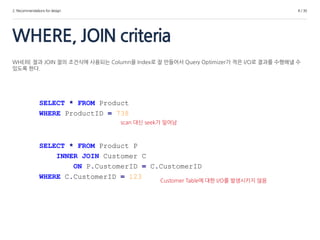
• Examine the WHERE clause and JOIN criteria columns
• Use narrow indexes
• Examine column uniqueness
• Examine the column data type
• Consider column order
• Consider the type of index (clustered or nonclustered)
8.
2. Recommendations fordesign
WHERE, JOIN criteria
8 / 30
SELECT * FROM Product
WHERE ProductID = 738
WHERE 절과 JOIN 절의 조건식에 사용되는 Column을 Index로 잘 만들어서 Query Optimizer가 적은 I/O로 결과를 수행해낼 수
있도록 한다.
SELECT * FROM Product P
INNER JOIN Customer C
ON P.CustomerID = C.CustomerID
WHERE C.CustomerID = 123
scan 대신 seek가 일어남
Customer Table에 대한 I/O를 발생시키지 않음
9.
2. Recommendations fordesign
Use narrow indexes
9 / 30
Index도 Page에 기록되니 한 페이지(8KB)에 최대한 많이 넣어 I/O 부담을 줄이고 Cache 사용 효율을 높이도록 한다.
• Reduces I/O (by having to read fewer 8KB pages)
• Caching more effective because can cache fewer index pages, reducing the logical reads
• Reduces the storage space
10.
2. Recommendations fordesign
Examine Column Uniqueness
10 / 30
Low selectivity에 의한 table scan을 피하고, unique columns에 index를 잘 걸어 high selectivity에 의한 seek로 성능을 높인다.
SELECT Filter
Compute
Scalar
Compute
Scalar
Clustered
Index Scan
SELECT
Compute
Scalar
Nested
Loops
Key
lookup
Compute
Scalar
Nonclustered
Index Seek
low selectivity에 의한 scan
composite index
high selectivity에 의한 seek
11.
2. Recommendations fordesign
Examine Column DataType
11 / 30
빠른 index search를 위해 작고, arithmetic manipulation이 가능한 type을 index에 사용한다.
• Small size
• Easy arithmetic manipulation
INTEGER
BIGINT
SMALLINT
TINYINT
CHAR
VARCHAR
NCHAR
NVARCHAR
12.
2. Recommendations fordesign
Consider Column Order
12 / 30
Composite index에서 각 column을 어떤 순서로 조합하여 index를 만드냐에 따라 index 효과 여부가 달라진다.
City PostalCode AddressID
Index
WHERE City = 'Warrington'
WHERE PostalCode = 'WA3 7BH'
SELECT AddressID, City, PostalCode
FROM Address
WHERE PostalCode = 'WA3 7BH‘
AND City = 'Warrington'
City는 Index에 포함, ∴ Index Seek
Row Locator
PostalCode는 City에 종속되어 Index에 포함, ∴Index Scan
Index에 모든 데이터 있음. Covering Index
City와 PostalCode (순서 바꿀 수 있음) 모두 Index에 있음. ∴ Index Seek
13.
2. Recommendations fordesign
Consider the Type of Index
13 / 30
Clustered와 nonclustered를 특성을 고려해서 index를 사용한다.
s o r t e d
IN
D E X
d r o e r s
IN
D E X
Clustered index
B-tree
root
branch
leaf
data page
data page
root
leaf
Nonclustered index
B-tree
• Leaf node is data-page
• Only one
• Bookmark lookup
• Seek data-table directly
• Leaf node links data-page
• Separate index and date page
• Create many
• Leaf has Row Locator
때문에 데이터 가져올 때 lookup 발생때문에 Seek하면 데이터까지 바로 가져옴
때문에 Scan은 Table Scan을 의미함
14.
1. Index?
2. Recommendationfor design
3. Clustered and nonclustered indexes
3.1 Clustered index and recommendations
3.2 Nonclustered index and recommandations
3.3 Clustered vs. Nonclustered indexes
4. Advanced indexing techniques
5. Additional characteristics
목차
15.
3. Clustered andNonclustered indexes
Clustered Indexes
15 / 30
Leaf-node가 data-page인, 그리고 data를 정렬해서 가지고 있는, 때문에 Table에 1개 밖에 가질 수 없는 Index이다.
• Leaf-node가 data-page
– 때문에 lookup 없이 데이터 바로 조회
• Heap 테이블과 달리 데이터를 정렬해서 가지고 있음
– 때문에 테이블에 1개 밖에 가질 수 없음
– 때문에 bookmark lookup을 통해 빠른 seek가 가능함
– 때문에 데이터 삽입 시 중간 삽입을 위한 page split 부담이 발생
• Nonclustered index가 Row Locator로 clustered index key를 가리킴
– 때문에 page split이 발생해도 nonclustered index를 갱신할 필요가 없음
16.
3. Clustered andNonclustered indexes
Clustered Index Recommendations
16 / 30
Clustered Index를 쓸 때 다음을 주의해서 쓰자.
• Create the Clustered Index First
– Nonclustered index가 RID 대신 clustered index key를 갖게 하는 것은 부담이므로, 먼저 만드는게 좋음
• Keep Indexes Narrow
– Nonclustered index가 Row Locator로 clustered index key를 갖기 때문에,
Clustered Index가 크면 모든 Nonclustered Index가 커져서 I/O 부담이 커짐
• Rebuild the Clustered Index in a Single Step
– DROP INDEX 후 CREATE INDEX하면 Nonclustered index가 2번 갱신되므로 DROP_EXISTING을 씀
17.
3. Clustered andNonclustered indexes
When to Use or Not to Use?
17 / 30
Clustered Index는 데이터를 정렬해놓으므로, high selectivity seek, retrieving range or sorted data에 좋다.
반면 nonclustered index가 Row Locator로 포함하므로 너무 큰 값을 갖으면 부담이 크고, page split에 의한 CUD 부담이 크다.
• [When to] Retrieving a Range of Data
– 데이터가 정렬되어 sequential하게 배치되어 있으므로 range data를 읽을 때 I/O 이득이 큼
• [When to] Retrieving Presorted Data
– 이미 데이터가 정렬되어 있으므로, 정렬된 형태의 데이터를 조회할 때 정렬 비용없이 가져올 수 있음
• [When not to] Frequently Updatable Columns
– Nonclustered index의 Row Locator도 같이 갱신해줘야 하므로 부담이 큼
• [When not to] Wide keys
– Nonclustered index의 Row Locator도 같이 커지기 때문에 부담이 큼
• [When not to] Too many concurrent inserts in sequential order
– 삽입될 page가 “hot spot”이 되고, fill factor를 고려하지 않은 page split이 발생
18.
3. Clustered andNonclustered indexes
Nonclustered indexes
18 / 30
Data table과 분리되어 index만으로 page를 구성되고, row locator로 rowID or clustered index key를 갖기 때문에 lookup으
로 데이터를 조회한다. leaf-node에 데이터를 포함시키는 covering index 등을 통해 SELECT 효율을 향상시킬 수 있다.
• Leaf-node의 row locator가 table을 가리킴
– 때문에 간접층으로 인한 page split에 의한 overhead가 줄어듬
– 때문에 lookup을 해서 데이터를 조회해야 함
– 때문에 Table I/O와 Index I/O가 분리되어 I/O 이득이 생김
• 여러 개의 Nonclustered index를 가질 수 있음
– 때문에 성능 향상을 위해 다양한 index를 생성할 수 있음
• Leaf-node가 index column의 데이터를 포함
– 때문에 Nonclustered index 내의 데이터로만 조회가 가능할 경우 data table 접근이 필요 없음
19.
3. Clustered andNonclustered indexes
When to Use or Not to Use?
19 / 30
Clustered index처럼 다른 index에 영향을 안 주므로 좀 더 잦은 변경/큰 크기의 column에 대해 사용 가능하다. Lookup 비용으
로 high selectivity한 곳에 쓰는 것이 좋고, 많은 row를 조회할 경우에는 효율이 떨어진다.
• [When to] High selectivity
– Lookup 비용을 수반하므로 적은 row를 반환하는 곳에서 씀
– 데이터를 leaf-node에 포함하는 convering index를 사용할 경우는 예외
• [When to] won’t be suitable for a clustered index
– Clustered index key는 모든 nonclustered index에 포함되므로 frequently updatable column 혹은 wide keys에
부적합하지만, nonclustered index는 그에 비해 자유롭게 쓸 수 있음
• [When not to] retrieving a large result set
– Bookmark Lookup 비용이 proportionately하게 증가하므로 covering index가 아닌 경우에는 안 쓰는 것이 좋음
20.
3. Clustered andNonclustered indexes
Clustered vs. Nonclustered Indexes
20 / 30
• Number of rows to be retrived
• Data-ordering requirement
• Bookmark cost
Benefits of A Clustered Index
No lookup
Benefits of A Nonclustered Index
When the index key size is large
To avoid the overhead cost associated with a
clustered index
To resolve blocking by having a database reader
work on pages on only index page
Covering index
• Column update frequency
• Index key width
• Any dist hot spots
21.
1. Index?
2. Recommendationfor design
3. Clustered and nonclustered indexes
4. Advanced indexing techniques
4.1 Covering Indexes
4.2 Index Intersections and joins
4.3 Filtered Indexes
4.4 Index View
5. Additional characteristics
목차
22.
4. Advanced IndexingTechniques
Covering Indexes
22 / 30
Leaf-node에 데이터를 포함시켜 data-table 접근 없이 데이터를 조회하기 위한 방법이다.
SELECT PostalCode FROM Address
WHERE StateProvinceID = 42
CREATE NONCLUSTERED INDEX [IX_ASPID]
ON [Address] ([StateProvinceID] ASC)
INCLUDE (PostalCode)
때문에 lookup 없이 index seek만으로 SELECT가 된다.
• Don’t want to increase the size of index keys
• Data type that can’t be indexed
• Already exceed the max # of key columns
Best used cases
Key columns
23.
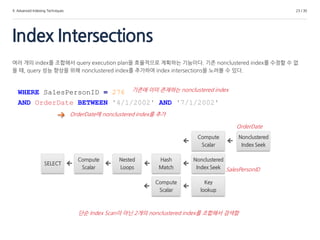
4. Advanced IndexingTechniques
Index Intersections
23 / 30
여러 개의 index를 조합해서 query execution plan을 효율적으로 계획하는 기능이다. 기존 nonclustered index를 수정할 수 없
을 때, query 성능 향상을 위해 nonclustered index를 추가하여 index intersections을 노려볼 수 있다.
기존에 이미 존재하는 nonclustered indexWHERE SalesPersonID = 276
AND OrderDate BETWEEN '4/1/2002' AND '7/1/2002'
OrderDate에 nonclustered index를 추가
SELECT
Compute
Scalar
Nested
Loops
Key
lookup
Compute
Scalar
Nonclustered
Index Seek
Nonclustered
Index Seek
Compute
Scalar
Hash
Match
OrderDate
SalesPersonID
단순 Index Scan이 아닌 2개의 nonclustered index를 조합해서 검색함
24.
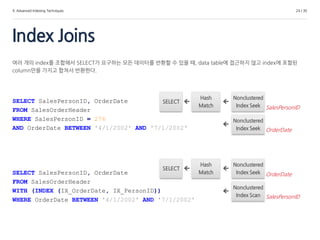
4. Advanced IndexingTechniques
Index Joins
24 / 30
여러 개의 index를 조합해서 SELECT가 요구하는 모든 데이터를 반환할 수 있을 때, data table에 접근하지 않고 index에 포함된
column만을 가지고 합쳐서 반환한다.
SELECT
Nonclustered
Index Seek
Nonclustered
Index Seek
Hash
Match
OrderDate
SalesPersonID
SELECT
Nonclustered
Index Seek
Nonclustered
Index Scan
Hash
Match
SalesPersonID
OrderDate
SELECT SalesPersonID, OrderDate
FROM SalesOrderHeader
WHERE SalesPersonID = 276
AND OrderDate BETWEEN '4/1/2002' AND '7/1/2002‘
SELECT SalesPersonID, OrderDate
FROM SalesOrderHeader
WITH (INDEX (IX_OrderDate, IX_PersonID))
WHERE OrderDate BETWEEN '4/1/2002' AND '7/1/2002'
25.
Filtered Indexes
25 /30
Index를 생성할 때 조건문을 넣어 index seek 수행 시 filtered 된 데이터만 seek함으로써 I/O 효율을 향상시키기 위한 방법이다.
• Filtered indexes pay off in many ways
– Improving the efficiency of queries by reducing the size of the index
– Reducing storage costs by making smaller indexes
– Cutting down on the costs of index maintenance because of the reduced size
4. Advanced Indexing Techniques
CREATE NONCLUSTERED INDEX [IX_Test]
ON (...) INCLUDE (...)
WHERE SalesPersonId IS NOT NULL
26.
Indexed Views
26 /30
View에 unique clustered index를 걸어서 materialized 된 view로 precompute된 aggregation column이나 materialized된
join 등 장점이 있지만, 그에 따른 갱신 overhead를 갖는다.
• Aggregations can be precomputed
• Tables can be prejoined
• Combinations of joins or aggregations can be materialized
4. Advanced Indexing Techniques
Benefit
• Any change in base tables has to be reflected by executing the view’s SELECT
• Any changes may initiate more changes in the clustered/nonclustered indexes of the indexed view
• Adds to the ongoing maintenance overhead of the database
• Additional storage is required
Overhead
• The first index on the view must be a unique clustered index
• The view definition must be deterministic
• Float columns cannot be included in clustered index key
Restrictions
Additional Characteristics ofIndexes
28 / 305. Additional Characteristics
• Different Column Sort Order
• Index On Computed Columns
• Index on BIT Date Type Columns
• CREATE INDEX Statement Processed As a Query
• Parallel Index Creation
• Online Index Creation
• Considering the Database Engine Tuning Advisor
29.
Summary
29 / 30
•효율적인 방법을 써서 logical reads와 dist I/O를 줄이자.
• WHERE과 JOIN criteria에 적절한 Index를 걸어서 성능을 향상시키자.
• # of rows, selectivity 등의 조건과 장단점을 고려해서 clustered index와 nonclustered index를 적절히 걸자.
• 필요에 따라 convering index, multiple indexes를 사용하여 성능을 높이자.













![3. Clustered and Nonclustered indexes
When to Use or Not to Use?
17 / 30
Clustered Index는 데이터를 정렬해놓으므로, high selectivity seek, retrieving range or sorted data에 좋다.
반면 nonclustered index가 Row Locator로 포함하므로 너무 큰 값을 갖으면 부담이 크고, page split에 의한 CUD 부담이 크다.
• [When to] Retrieving a Range of Data
– 데이터가 정렬되어 sequential하게 배치되어 있으므로 range data를 읽을 때 I/O 이득이 큼
• [When to] Retrieving Presorted Data
– 이미 데이터가 정렬되어 있으므로, 정렬된 형태의 데이터를 조회할 때 정렬 비용없이 가져올 수 있음
• [When not to] Frequently Updatable Columns
– Nonclustered index의 Row Locator도 같이 갱신해줘야 하므로 부담이 큼
• [When not to] Wide keys
– Nonclustered index의 Row Locator도 같이 커지기 때문에 부담이 큼
• [When not to] Too many concurrent inserts in sequential order
– 삽입될 page가 “hot spot”이 되고, fill factor를 고려하지 않은 page split이 발생](https://image.slidesharecdn.com/ch4indexanalysis-140613012847-phpapp01/85/Index-Analysis-17-320.jpg)

![3. Clustered and Nonclustered indexes
When to Use or Not to Use?
19 / 30
Clustered index처럼 다른 index에 영향을 안 주므로 좀 더 잦은 변경/큰 크기의 column에 대해 사용 가능하다. Lookup 비용으
로 high selectivity한 곳에 쓰는 것이 좋고, 많은 row를 조회할 경우에는 효율이 떨어진다.
• [When to] High selectivity
– Lookup 비용을 수반하므로 적은 row를 반환하는 곳에서 씀
– 데이터를 leaf-node에 포함하는 convering index를 사용할 경우는 예외
• [When to] won’t be suitable for a clustered index
– Clustered index key는 모든 nonclustered index에 포함되므로 frequently updatable column 혹은 wide keys에
부적합하지만, nonclustered index는 그에 비해 자유롭게 쓸 수 있음
• [When not to] retrieving a large result set
– Bookmark Lookup 비용이 proportionately하게 증가하므로 covering index가 아닌 경우에는 안 쓰는 것이 좋음](https://image.slidesharecdn.com/ch4indexanalysis-140613012847-phpapp01/85/Index-Analysis-19-320.jpg)


![4. Advanced Indexing Techniques
Covering Indexes
22 / 30
Leaf-node에 데이터를 포함시켜 data-table 접근 없이 데이터를 조회하기 위한 방법이다.
SELECT PostalCode FROM Address
WHERE StateProvinceID = 42
CREATE NONCLUSTERED INDEX [IX_ASPID]
ON [Address] ([StateProvinceID] ASC)
INCLUDE (PostalCode)
때문에 lookup 없이 index seek만으로 SELECT가 된다.
• Don’t want to increase the size of index keys
• Data type that can’t be indexed
• Already exceed the max # of key columns
Best used cases
Key columns](https://image.slidesharecdn.com/ch4indexanalysis-140613012847-phpapp01/85/Index-Analysis-22-320.jpg)
![Filtered Indexes
25 / 30
Index를 생성할 때 조건문을 넣어 index seek 수행 시 filtered 된 데이터만 seek함으로써 I/O 효율을 향상시키기 위한 방법이다.
• Filtered indexes pay off in many ways
– Improving the efficiency of queries by reducing the size of the index
– Reducing storage costs by making smaller indexes
– Cutting down on the costs of index maintenance because of the reduced size
4. Advanced Indexing Techniques
CREATE NONCLUSTERED INDEX [IX_Test]
ON (...) INCLUDE (...)
WHERE SalesPersonId IS NOT NULL](https://image.slidesharecdn.com/ch4indexanalysis-140613012847-phpapp01/85/Index-Analysis-25-320.jpg)







![[NDC 2014] 던전앤파이터 클라이언트 로딩 최적화](https://cdn.slidesharecdn.com/ss_thumbnails/ndc201420140605-140604221309-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)



![[야생의 땅: 듀랑고] 서버 아키텍처 - SPOF 없는 분산 MMORPG 서버](https://cdn.slidesharecdn.com/ss_thumbnails/public-140529222503-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)


![[2015-06-26] Oracle 성능 최적화 및 품질 고도화 3](https://cdn.slidesharecdn.com/ss_thumbnails/2015-06-26oracle3-150623063728-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)







![[2015 07-06-윤석준] Oracle 성능 최적화 및 품질 고도화 4](https://cdn.slidesharecdn.com/ss_thumbnails/2015-07-06-oracle4-150702090606-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)







![[제3회 스포카콘] SQL 쿼리 최적화 맛보기](https://cdn.slidesharecdn.com/ss_thumbnails/spoqacon2021keynotejhuni-210222015014-thumbnail.jpg?width=640&height=640&fit=bounds)
