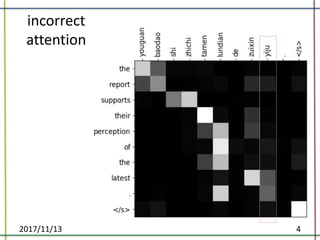
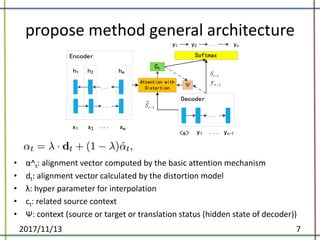
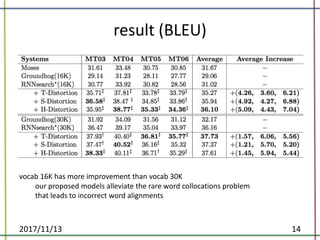
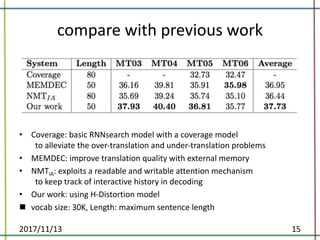
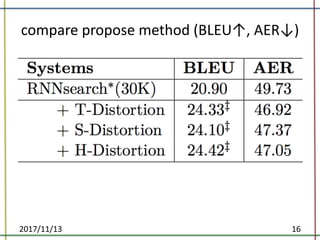
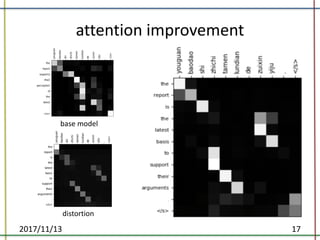
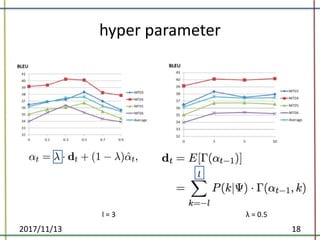
The document proposes a method to incorporate word reordering knowledge into attention-based neural machine translation using a distortion model. The method extends the attention mechanism to consider both the semantic requirements and a word reordering penalty. It achieves state-of-the-art performance on translation quality and improves word alignment quality compared to baseline neural machine translation and prior work.





























![[論文紹介]Selecting syntactic, non redundant segments in active learning for mach...](https://cdn.slidesharecdn.com/ss_thumbnails/selectingsyntacticnon-redundantsegmentsinactivelearningformachinetranslation-160623025240-thumbnail.jpg?width=640&height=640&fit=bounds)






























